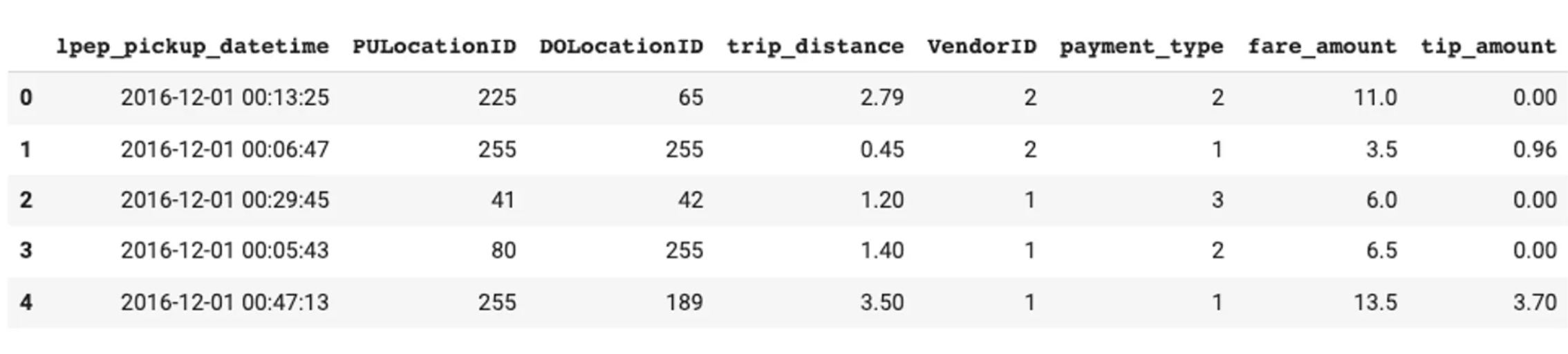
# Target column name
target = 'tip_amount'
# Features column name
features = ["PULocationID", "DOLocationID", "trip_distance", "VendorID", "pickup_time"]
# Training the model
model = LGBMRegressor(random_state=42)
model.fit(X_train, y_train)
# Making predictions
y_pred_train = model.predict(X_train)
y_pred_test = model.predict(X_test)
# Evaluating the model on train and test set
mae_train = MAE(y_train, y_pred_train)
mae_test = MAE(y_test, y_pred_test)
# Deploying the model to production
y_pred_prod = model.predict(X_prod)
Creating reference and analysis sets
Reference period
Uses a test set
Requires ground truth
Set the baseline performance
Analysis period
Latest production data
Ground truth is optional
NannyML analyzes the data drift and the performance
# Creating reference set
reference = X_test.copy() # Test set features
reference['y_pred'] = y_pred_test # Predictions
reference['tip_amount'] = y_test # Labels
reference = reference.join(
data['lpep_pickup_datetime']) # Timestamp
# Creating analysis set
analysis = X_prod.copy() # Production features
analysis['y_pred'] = y_pred_prod # Predictions
analysis = analysis.join(
data['lpep_pickup_datetime']) # Timestamp
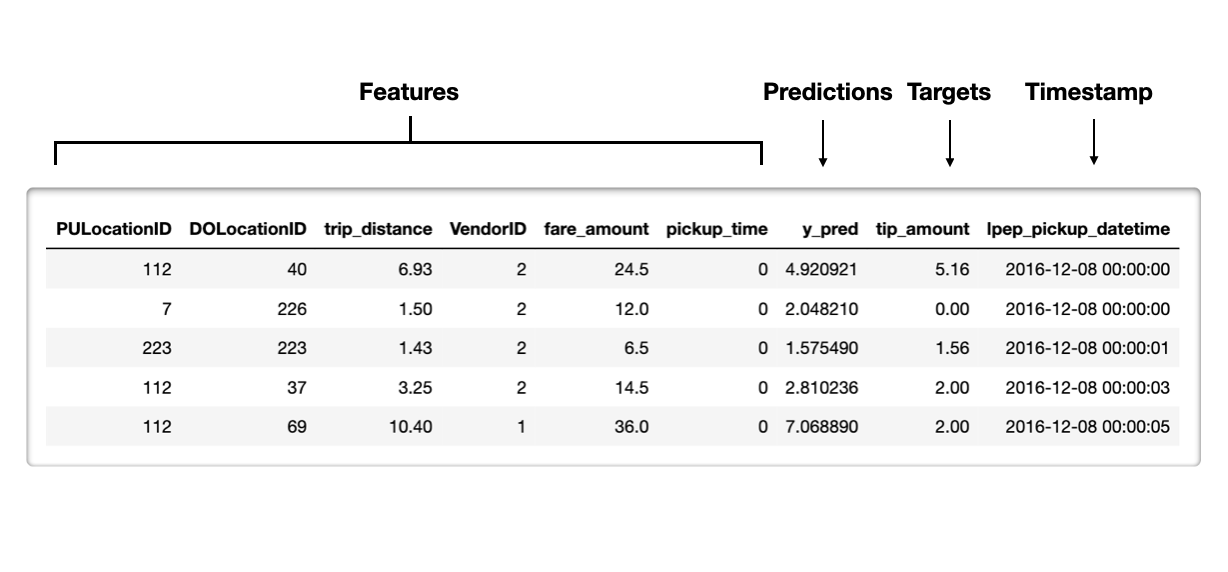
Reference set example
Timestamp - the time when observation occurred (optional)
Features - features fed to our model
Model outputs
Predictions - prediction score outputted by the model
Prediction class labels - thresholded probability scores