Working with a forecast object
Designing Forecasting Pipelines for Production

Rami Krispin
Senior Manager, Data Science and Engineering
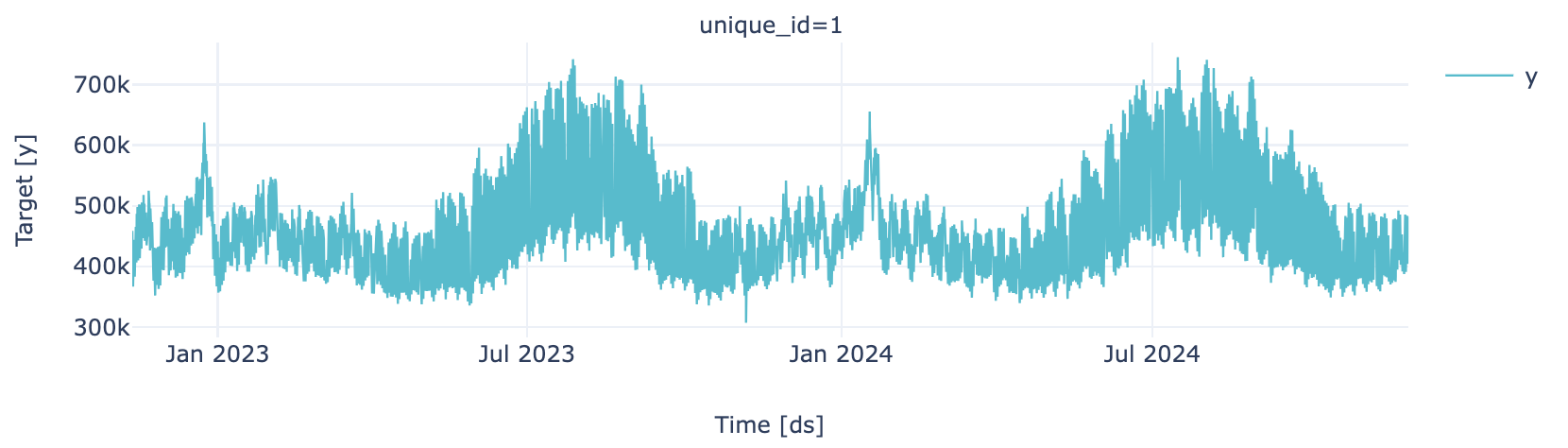
Training Partition
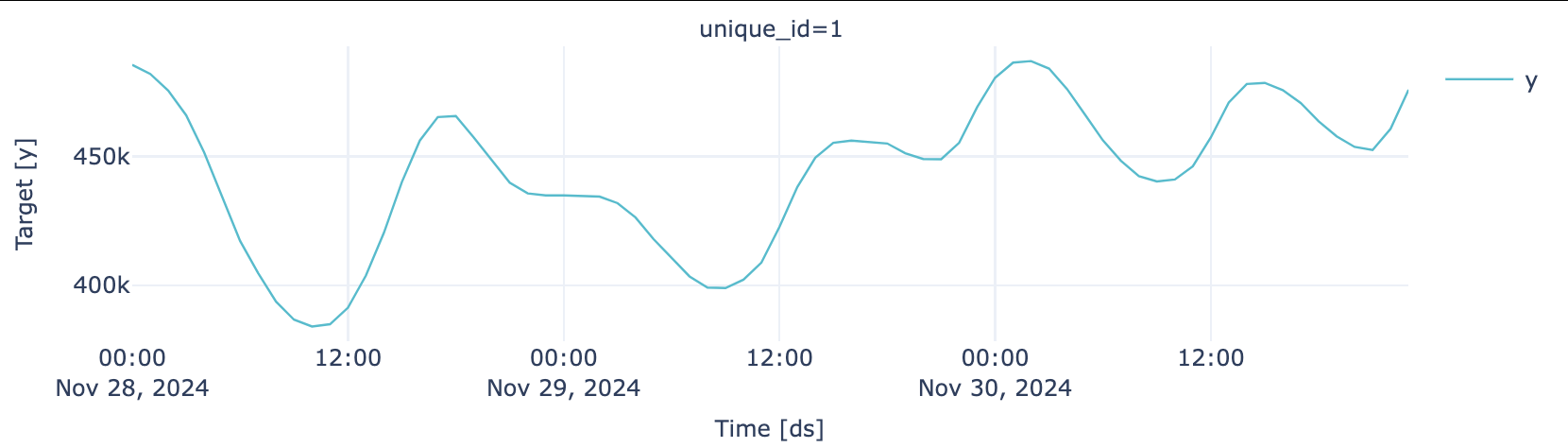
Testing Partition
Data preparation
plot_series(train, engine = "plotly")
plot_series(test, engine = "plotly")
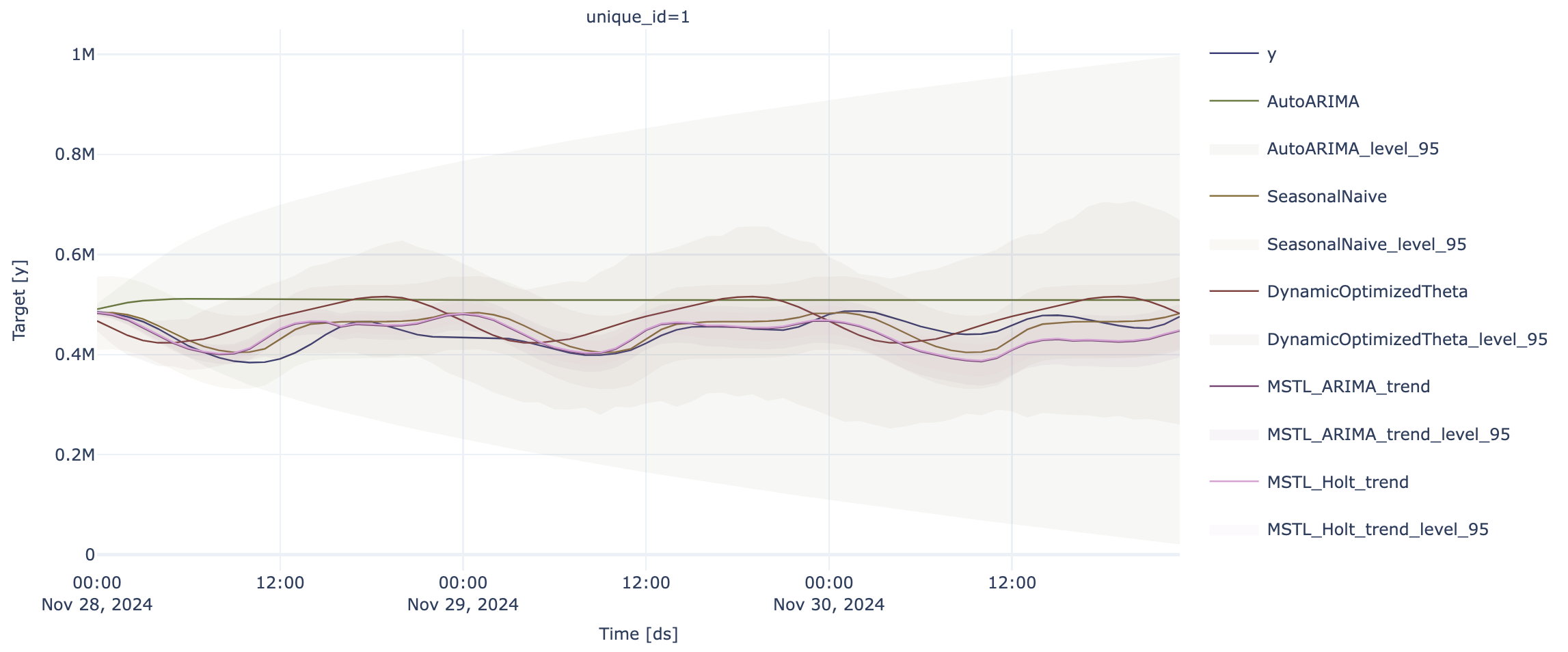
Forecast Forecasting with StatsModels StatsModels
p = sf.plot(test, forecast_stats, engine = "plotly", level=[95])
p.update_layout(height=400)