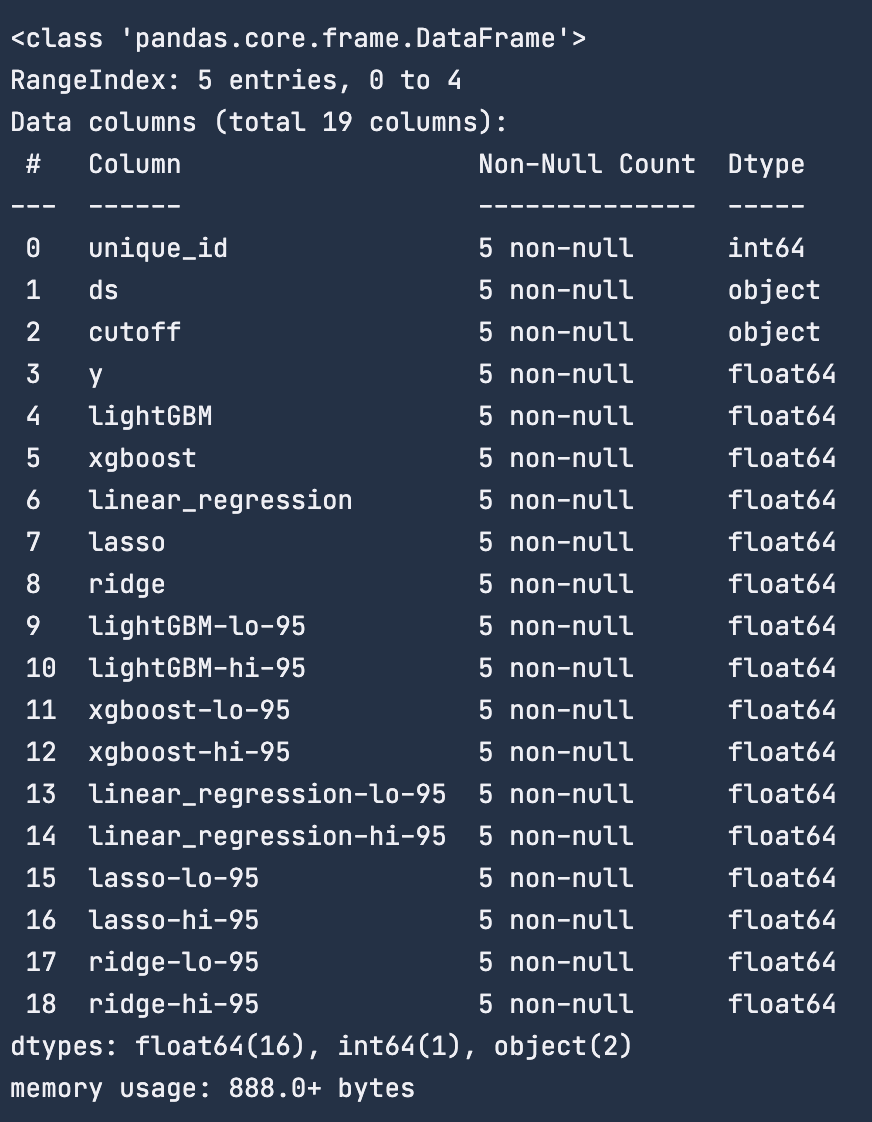
Backtesting
Designing Forecasting Pipelines for Production

Rami Krispin
Senior Manager, Data Science and Engineering
Backtesting
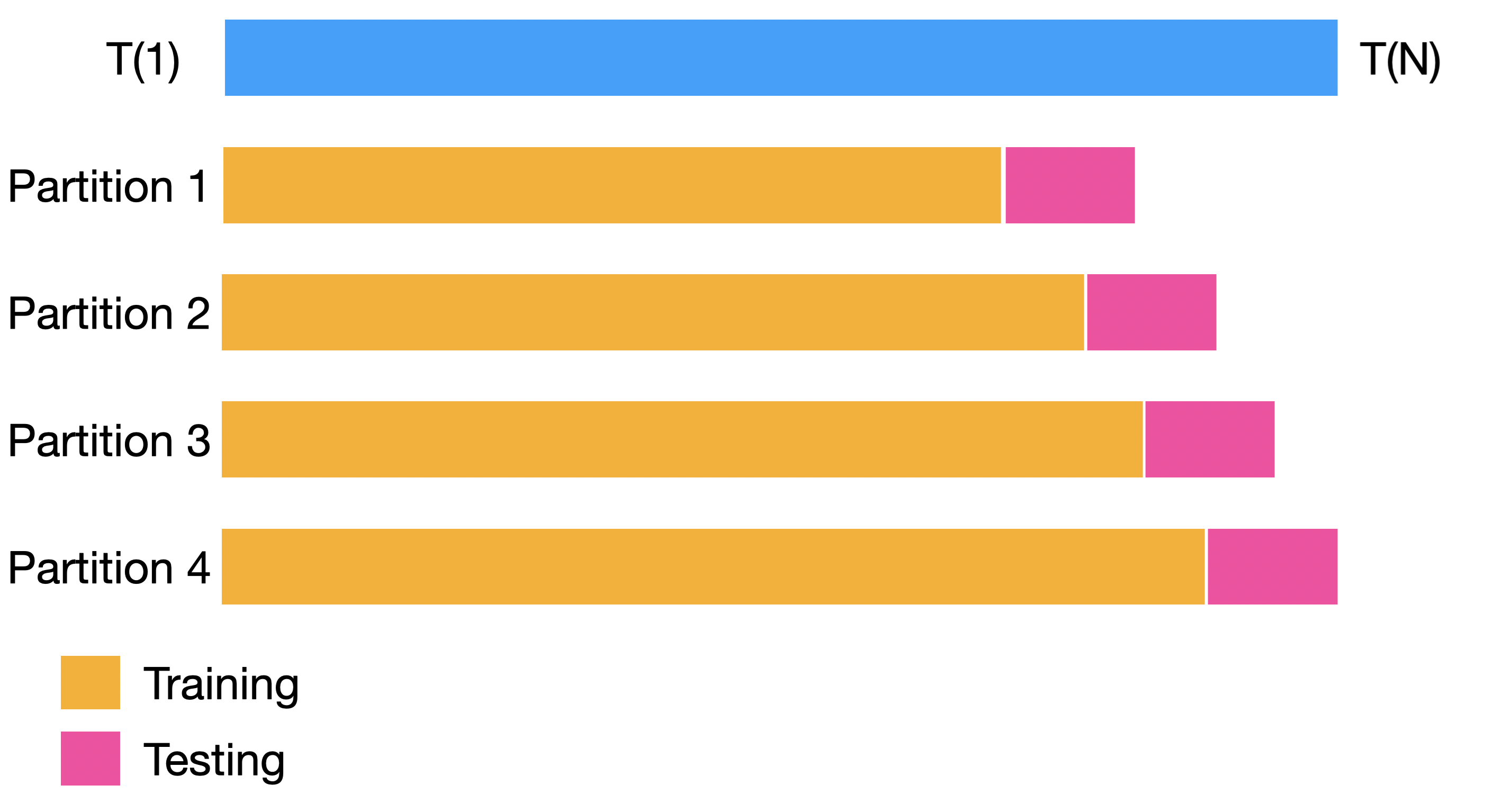
Backtesting
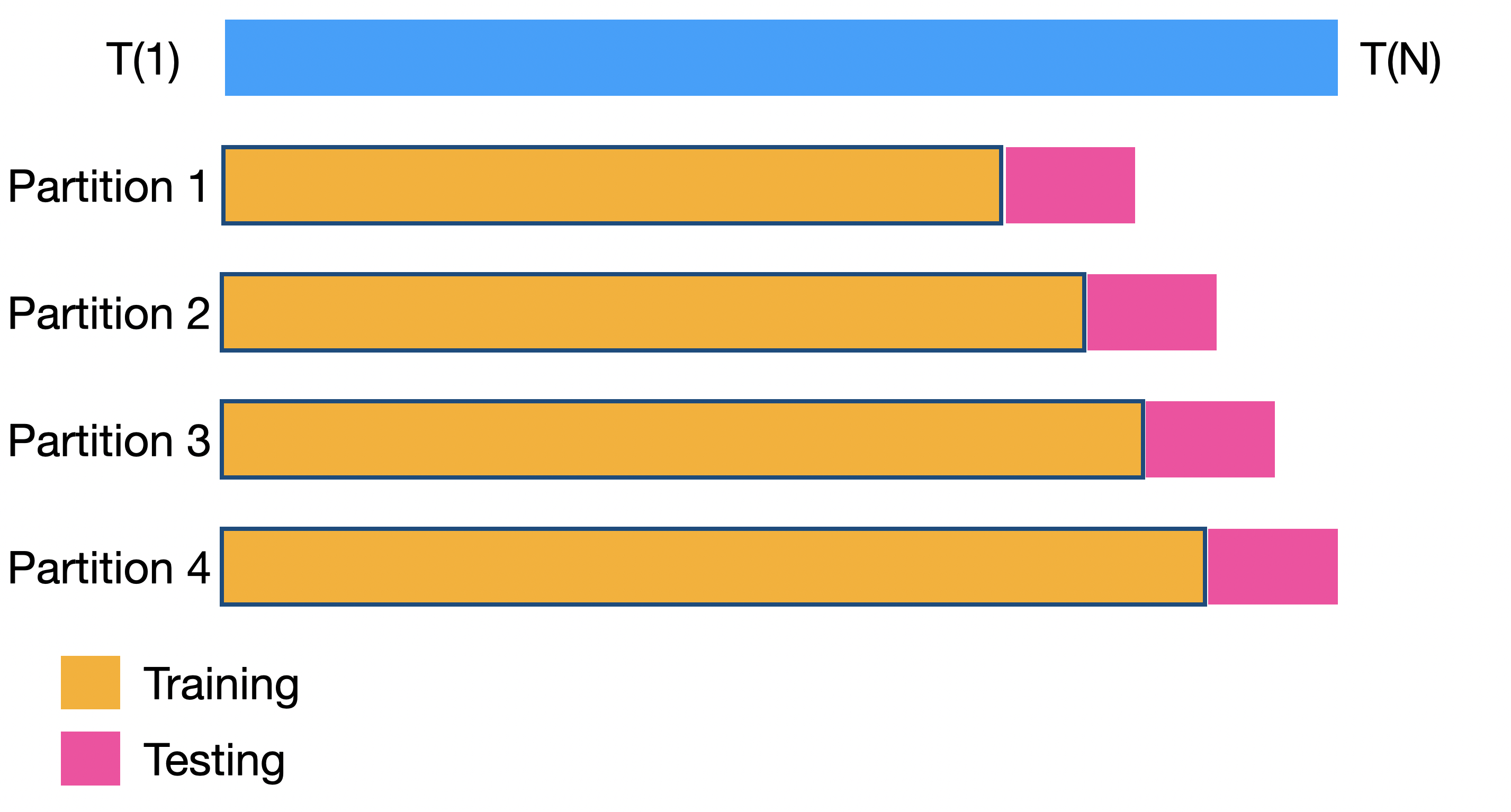
Backtesting
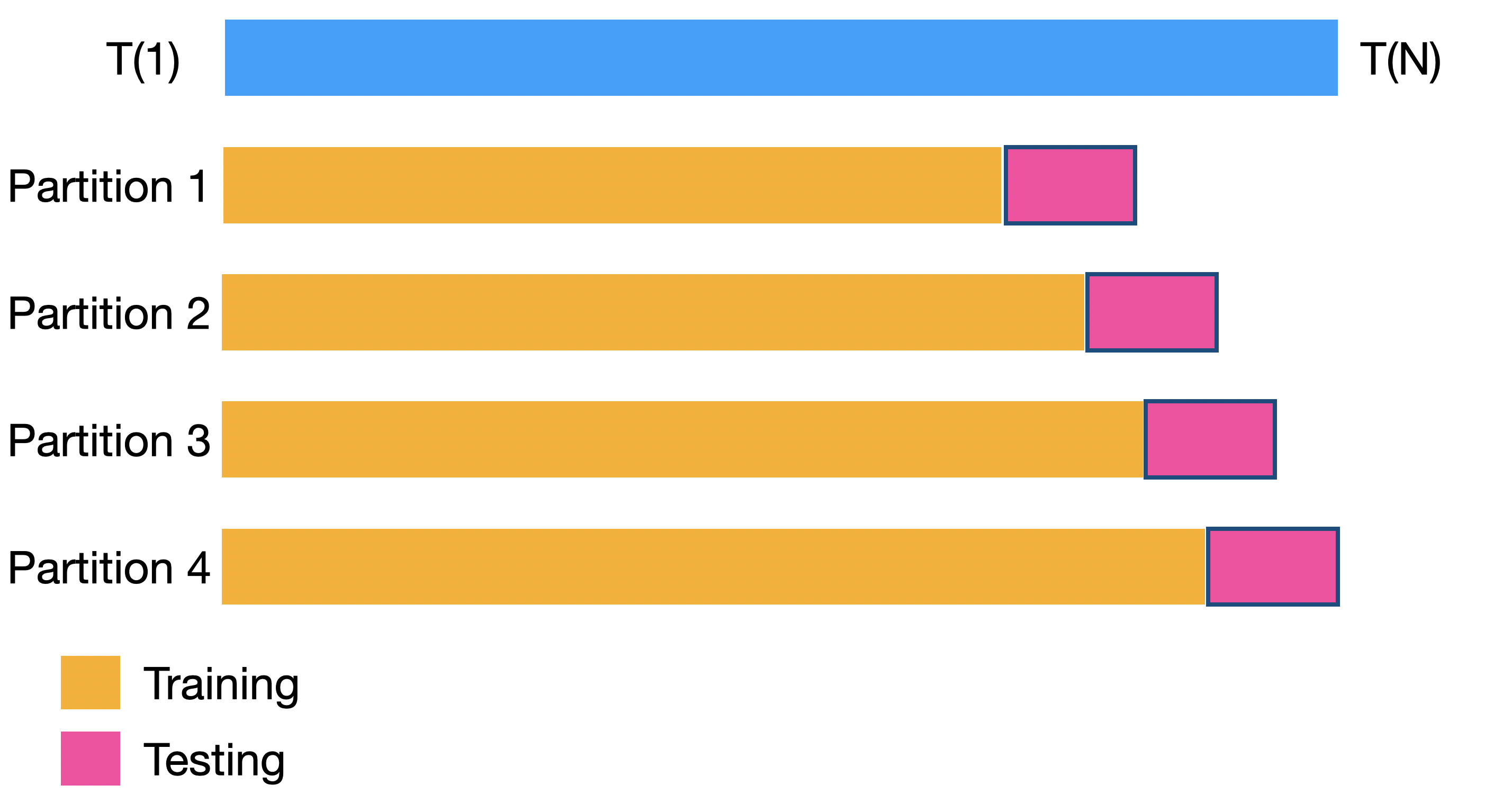
Backtesting
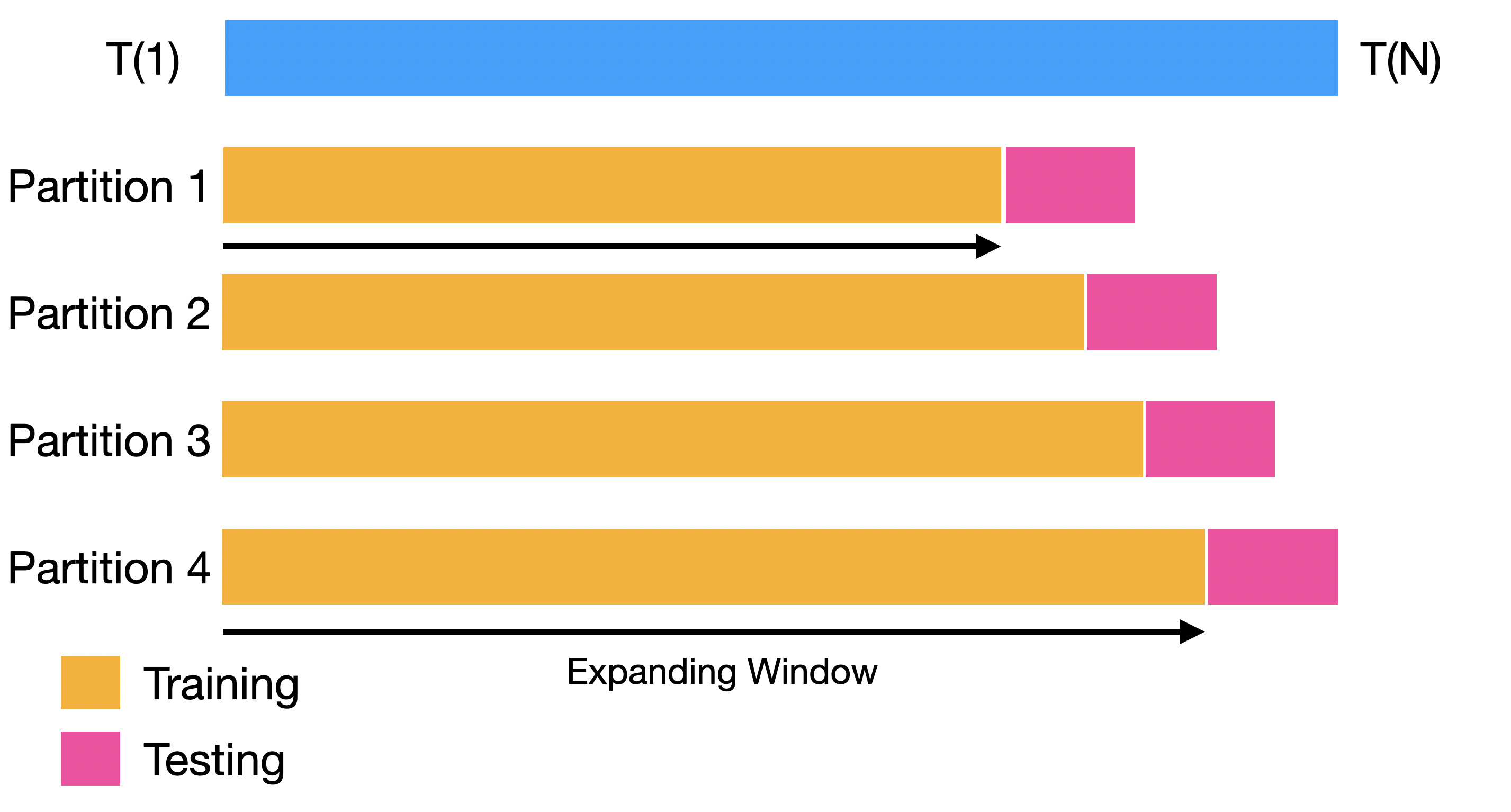
Backtesting
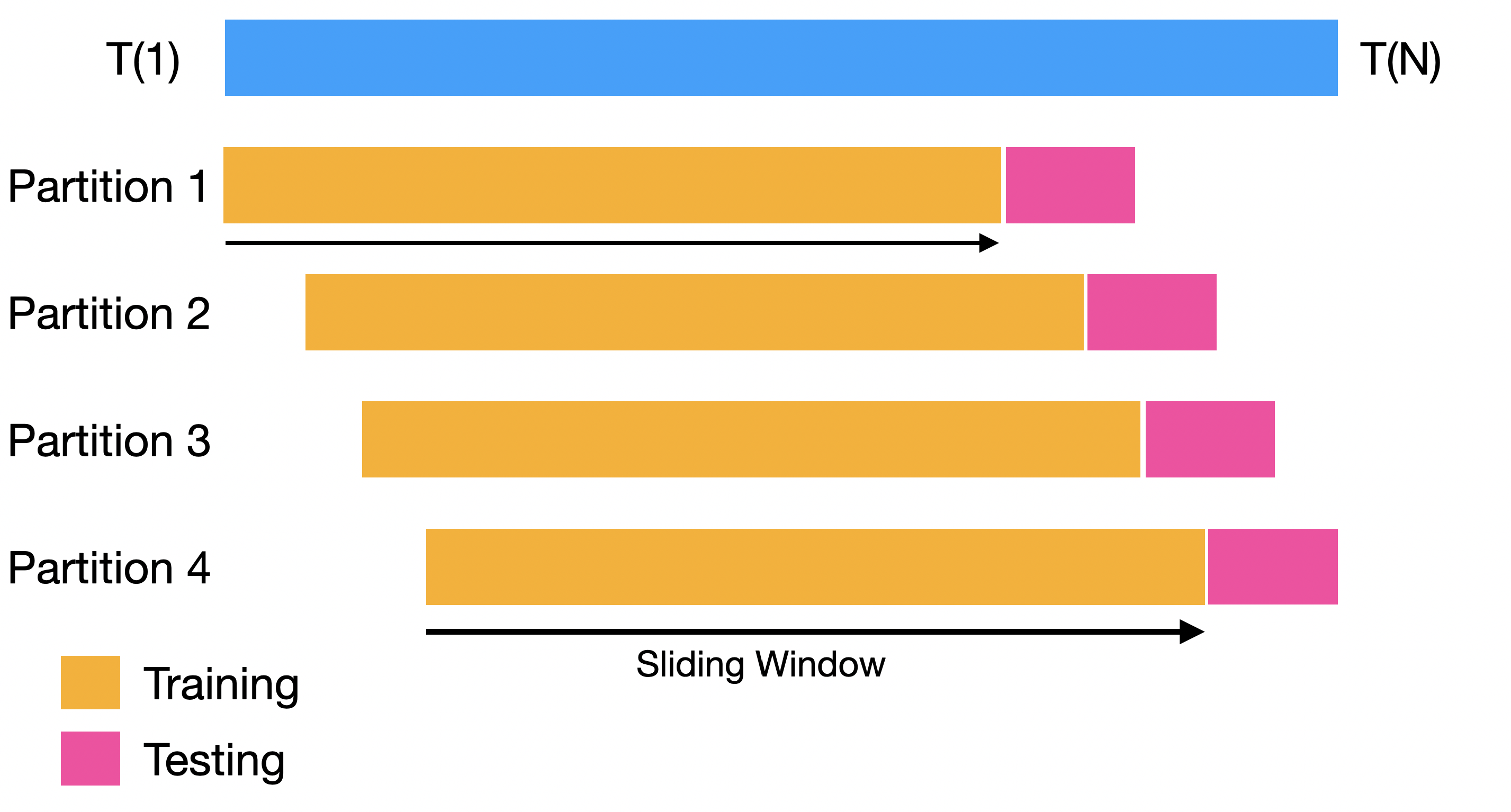
Backtesting
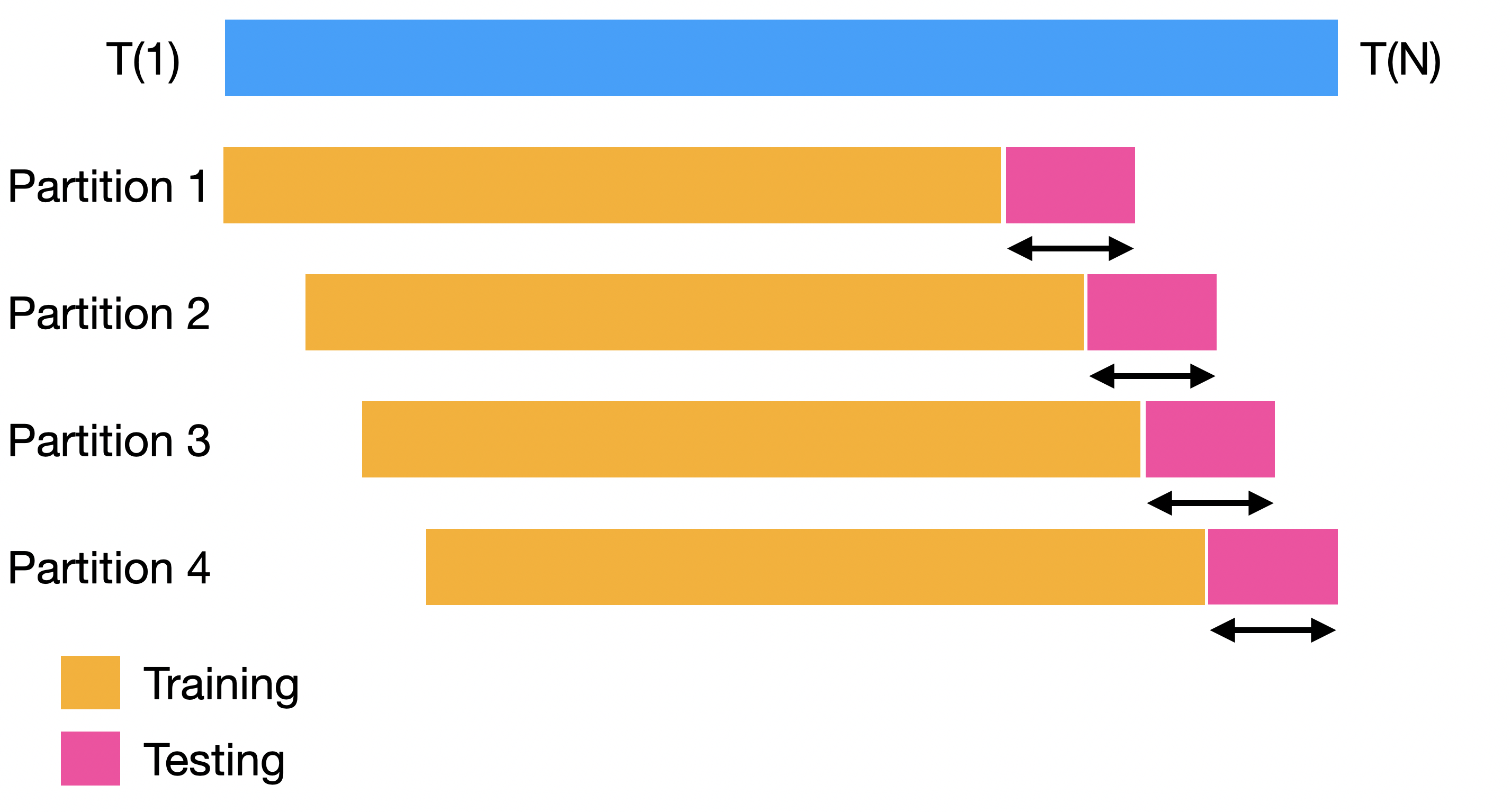
Backtesting
Backtesting settings
Partitions Settings
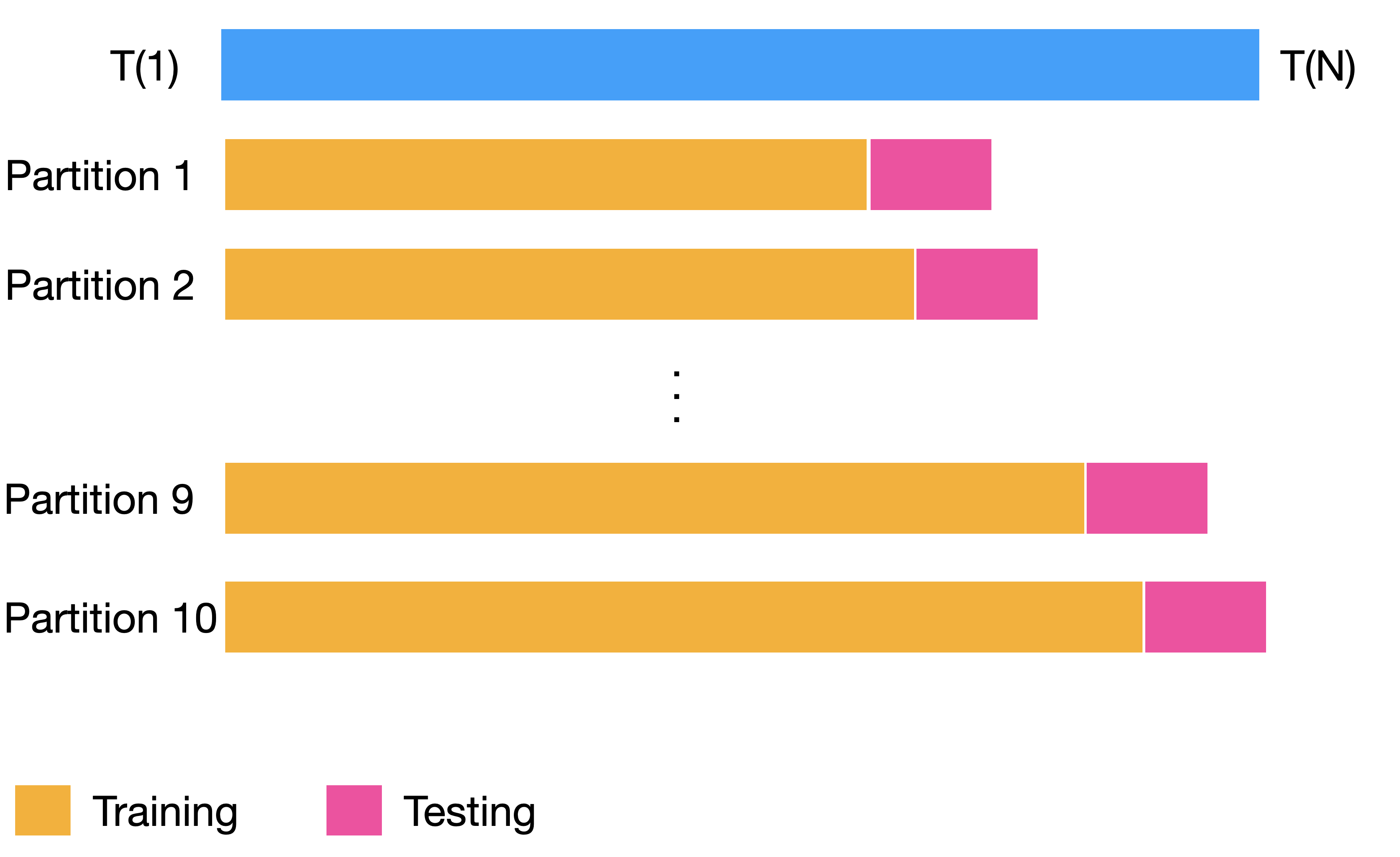
Backtesting settings
Partitions Settings
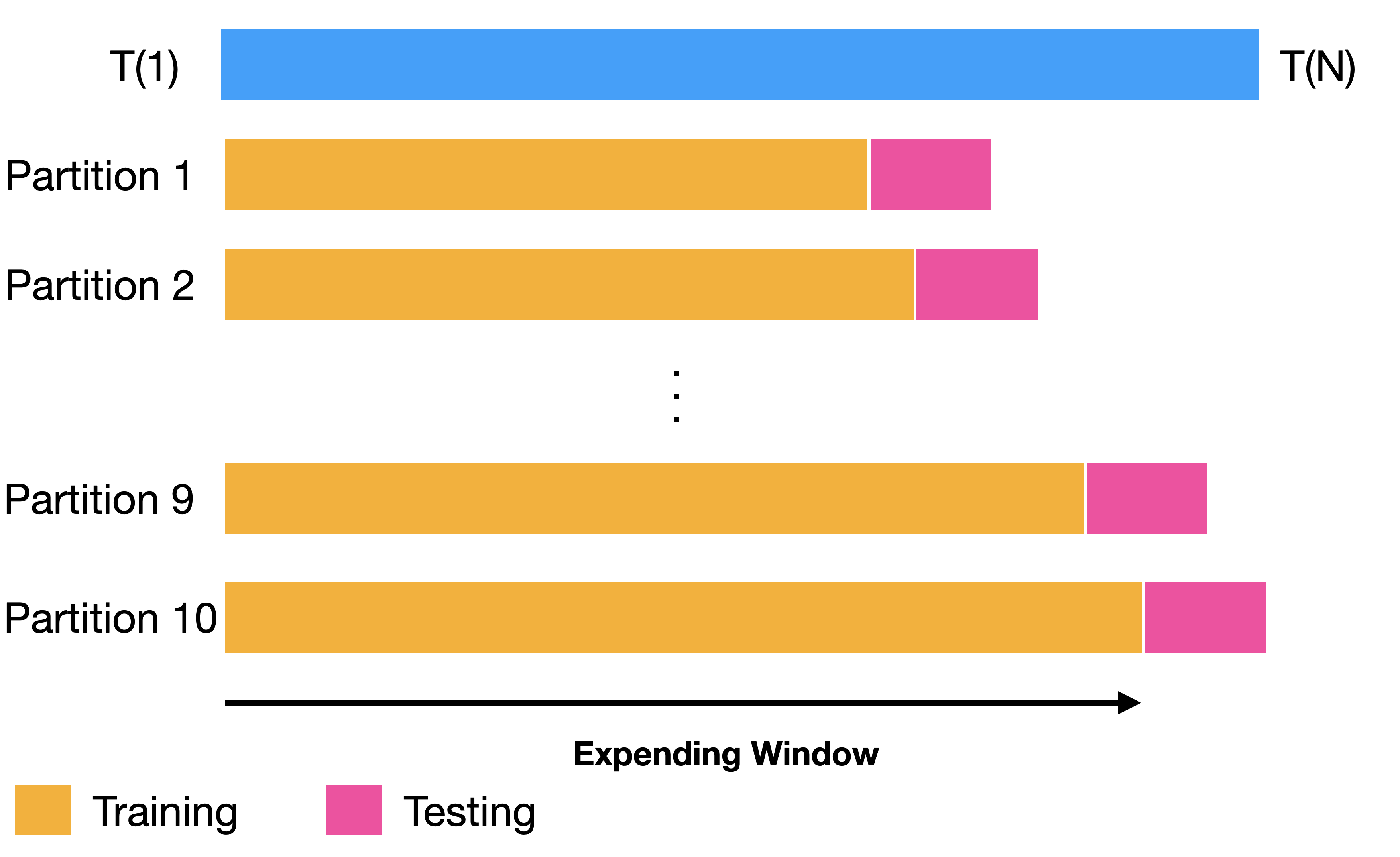
Backtesting settings
Partitions Settings
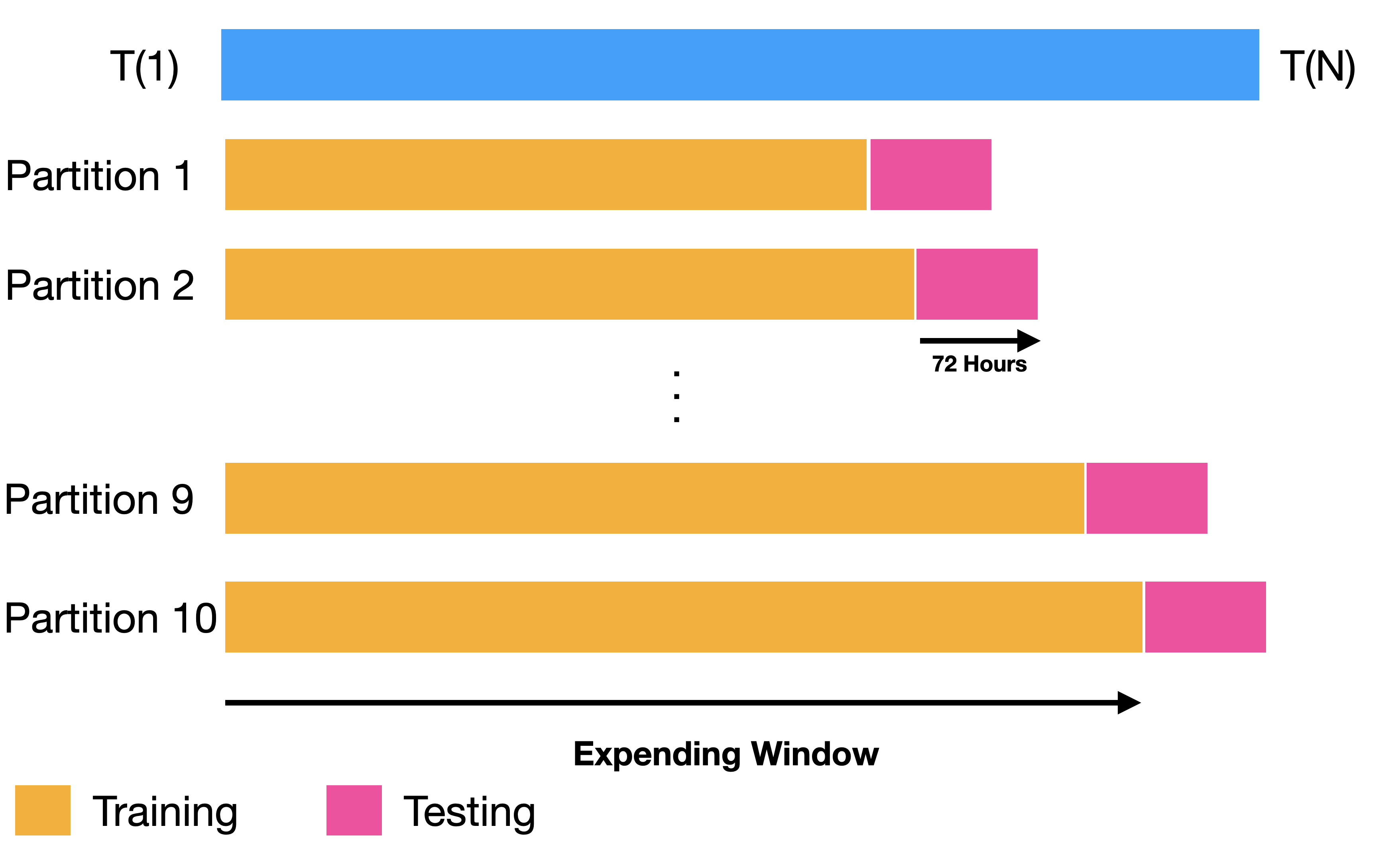
Backtesting settings
Partitions Settings
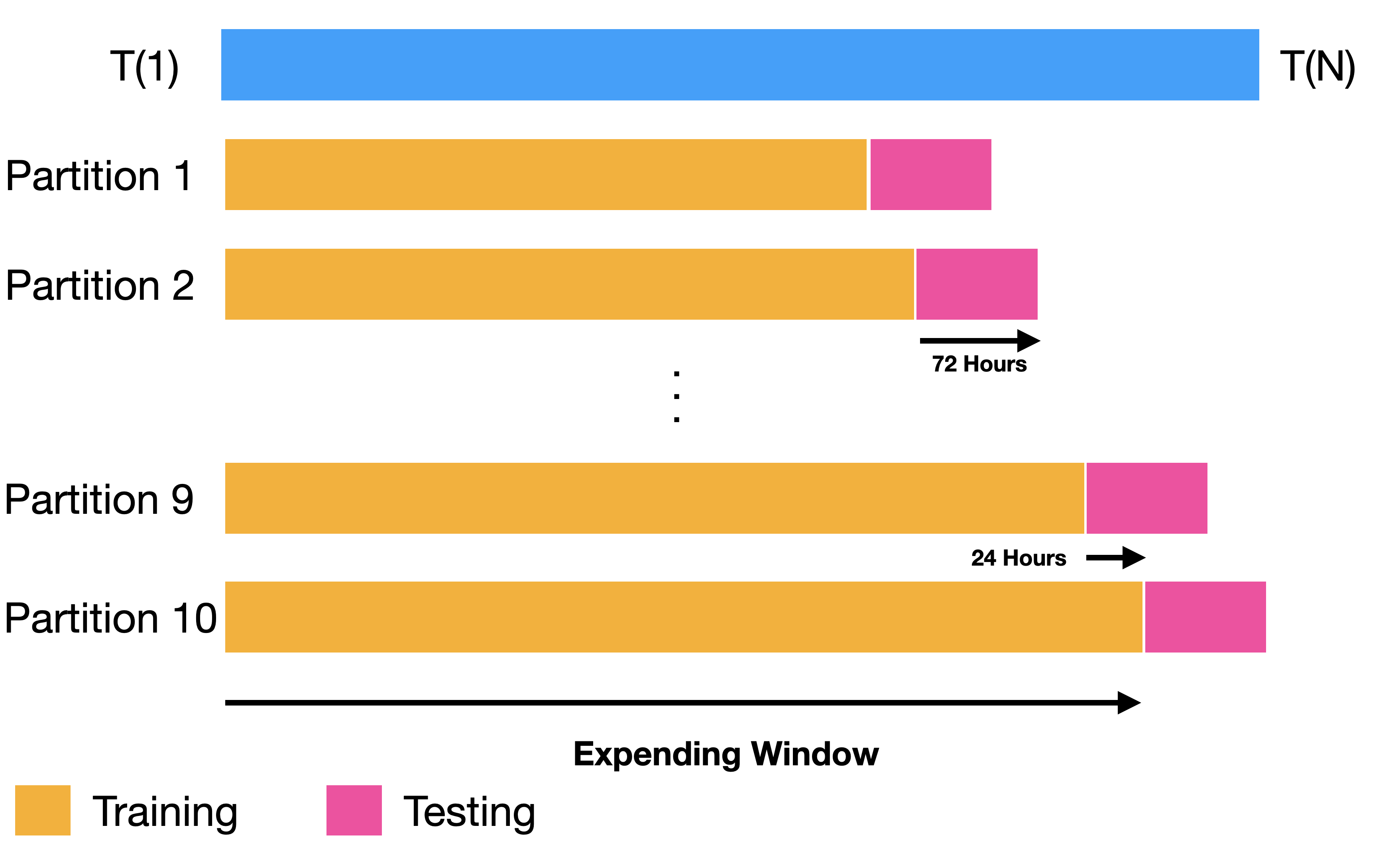
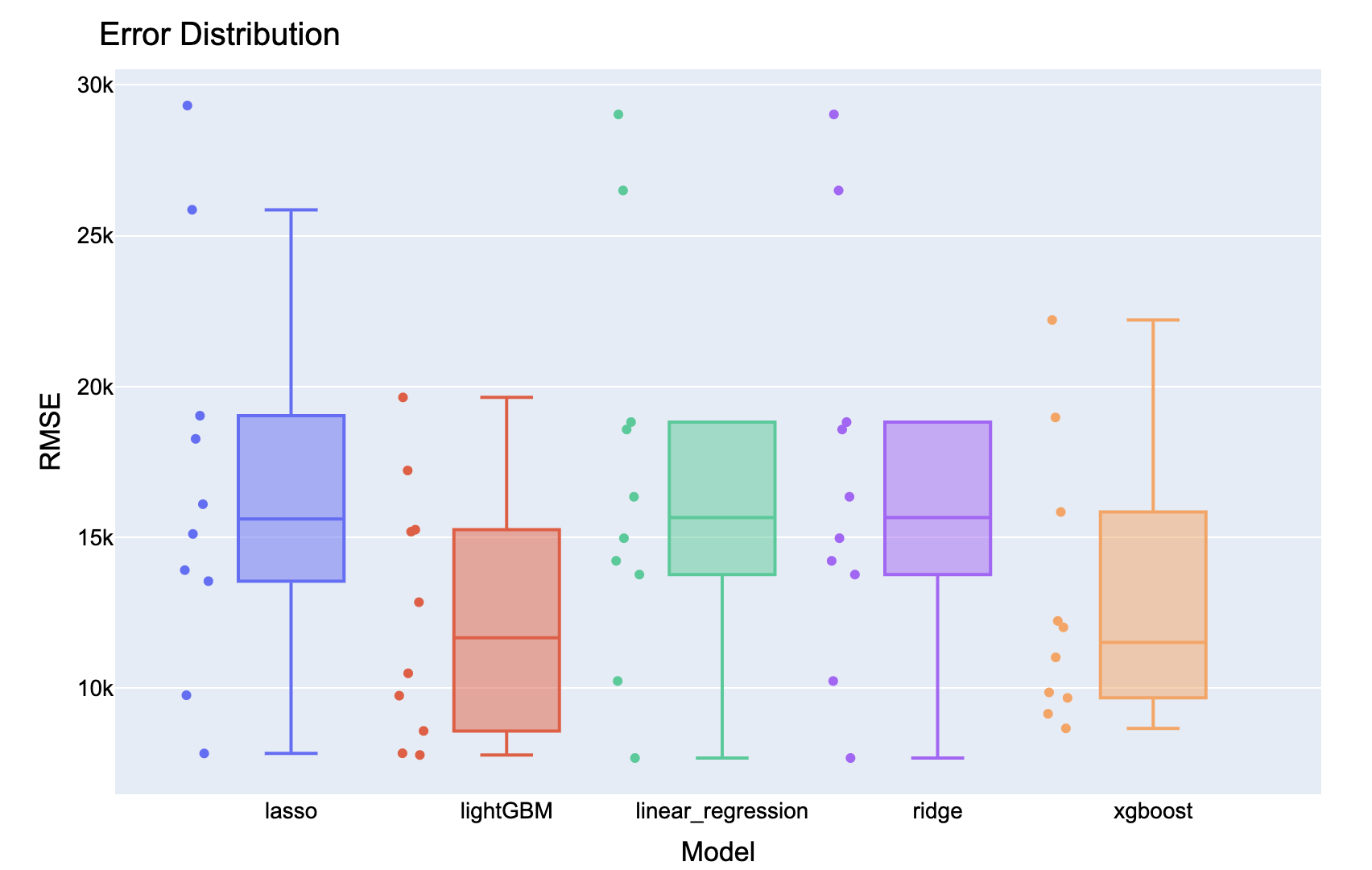
Backtesting results in wide format