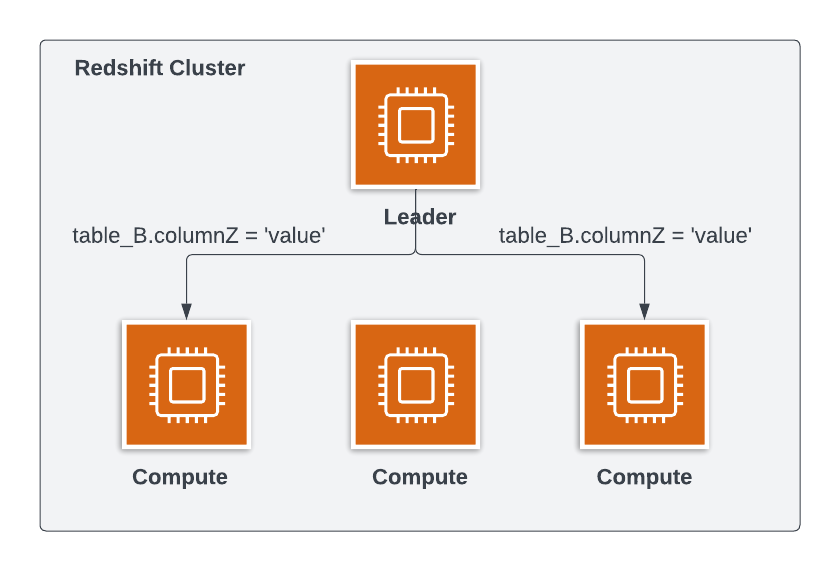
Remember that Redshift is columnar and pulls data by column
Use DISTKEY and SORTKEYs
Use in the following clauses whenever possible
JOIN
WHERE
GROUP BY
Use SORTKEYs in order in ORDER BY
Highly optimized sortkey_1, sortkey_2, sortkey_3
Not optimized sort_key_1, sort_key_3
Building good predicates
Use DISTKEY and SORTKEY
Close to the table join
Avoid using functions in them
SELECT receipts.cookie_id,
sum(receipts.total)
FROM receipts
JOIN cookies ON receipts.cookie_id = cookies.cookie_id
-- Keep cookies predicates in the join to push down to nodes holding the records for cookies
AND cookies.available_on < '2023-11-14'
AND cookies.end_of_sale IS null
-- Predicates that are not part of the join or on the joined table stay in the WHERE clause
WHERE receipts.order_time > '2023-11-13'
GROUP BY 1 ORDER BY 1;
Be consistent with column ordering
When using:
GROUP BY
ORDER BY
Bad
GROUP BY col_one, col_two, col_three
ORDER BY col_two, col_three, col_one
Good
GROUP BY col_two, col_three, col_one
ORDER BY col_two, col_three, col_one
Use subqueries wisely
Use proper join strategies instead of just using a subquery
Use EXISTS in your predicates when just checking for the truthfulness of a subquery result
SELECT column_name
FROM table_name
WHERE EXISTS
(SELECT column_name
FROM table_name
WHERE active is True);
If reusing subqueries, use CTEs to take advantage of caching