External Schemas, File, and Table Formats
Introduction to Redshift

Jason Myers
Principal Architect
External schemas
Database Components
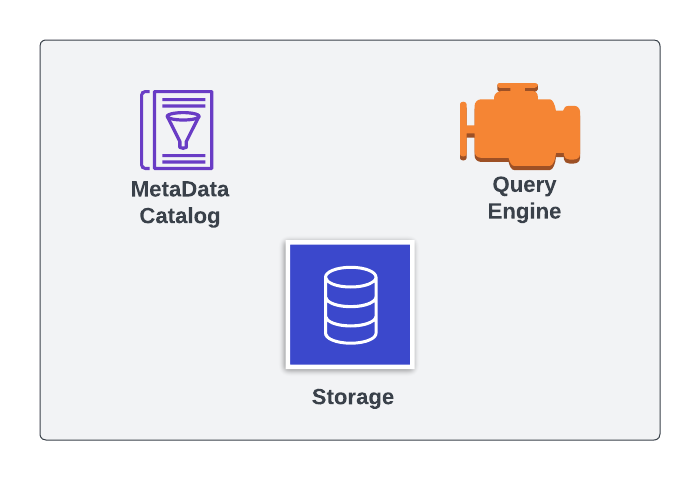
- When metadata catalog and storage are not part of the cluster it is considered external
Redshift Spectrum
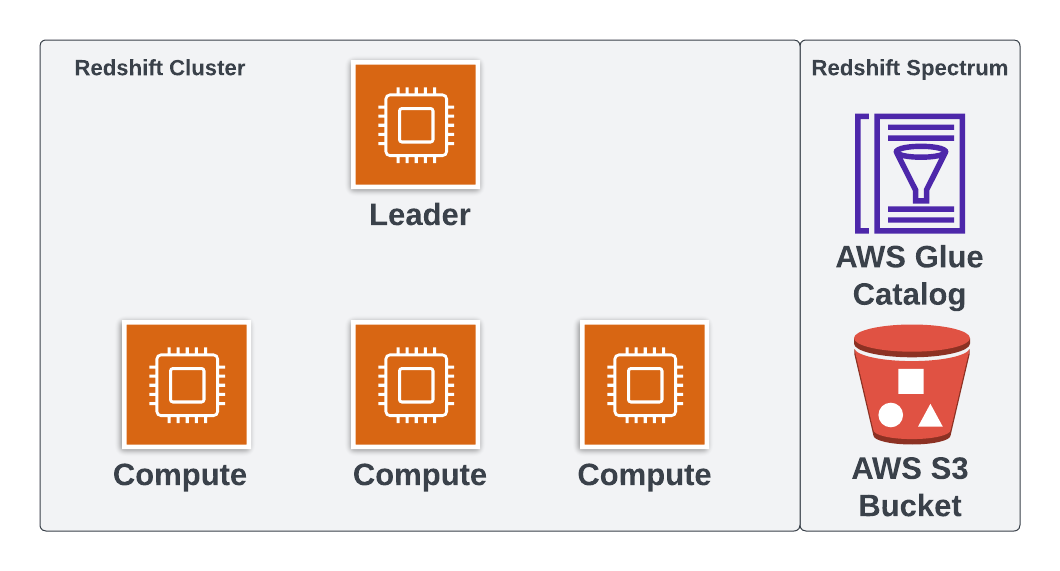
- Redshift is the engine
- Uses AWS Glue Data Catalog and AWS S3 storage by default

