Monte Carlo methods
Reinforcement Learning with Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Recap: model-based learning
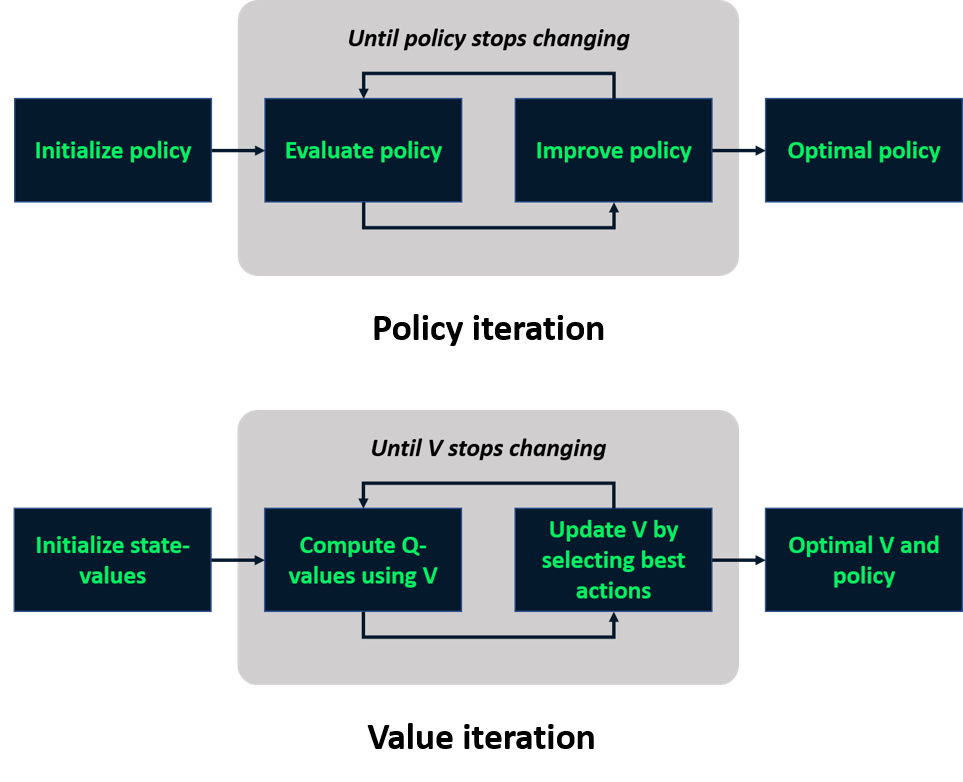
Model-free learning

Monte Carlo methods
- Model-free techniques
- Estimate Q-values based on episodes
Monte Carlo methods
- Model-free techniques
- Estimate Q-values based on episodes

Monte Carlo methods
- Model-free techniques
- Estimate Q-values based on episodes

- Two methods: first-visit, every-visit
Custom grid world
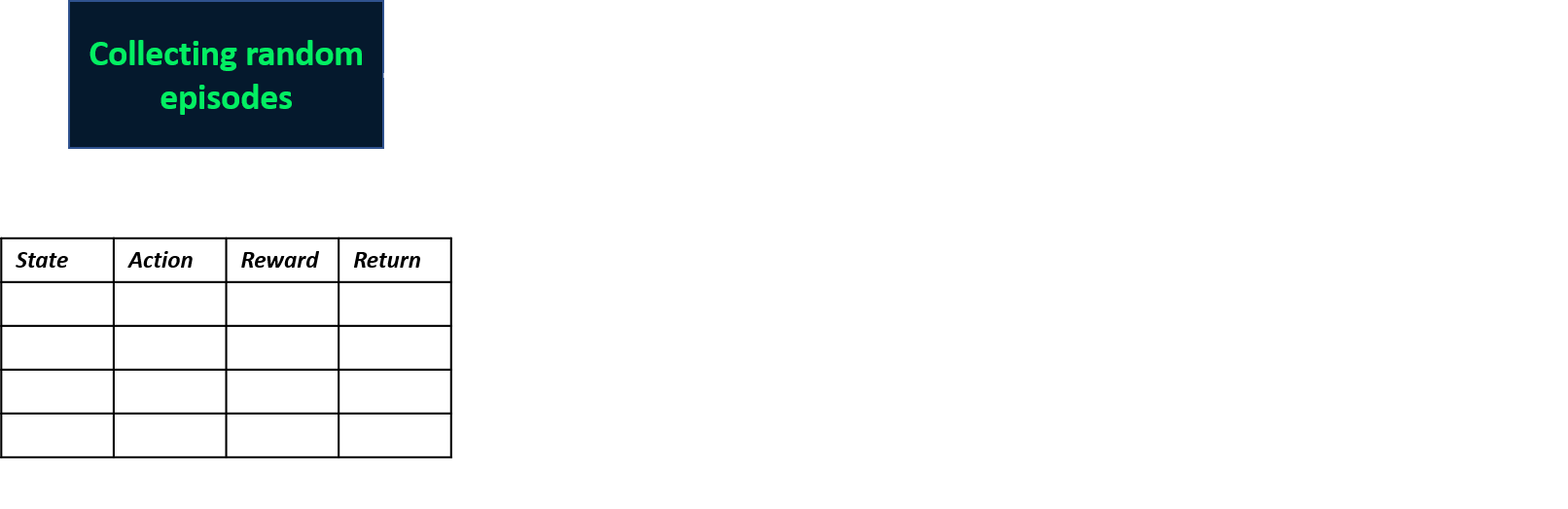
Collecting two episodes
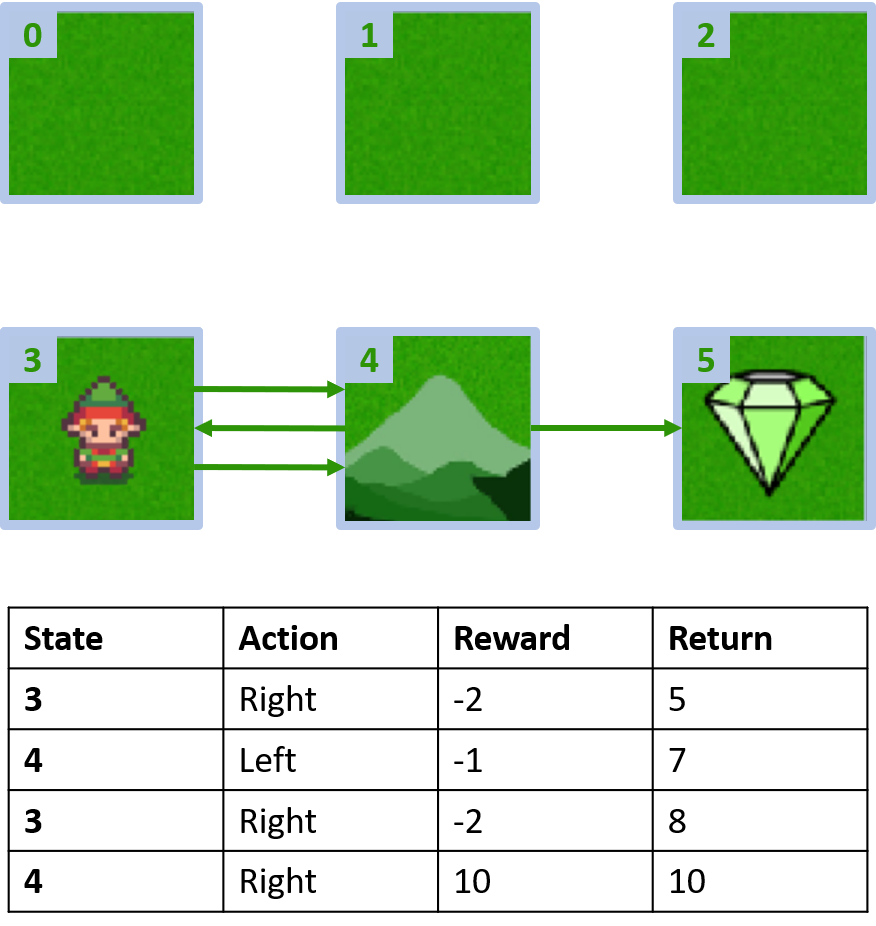
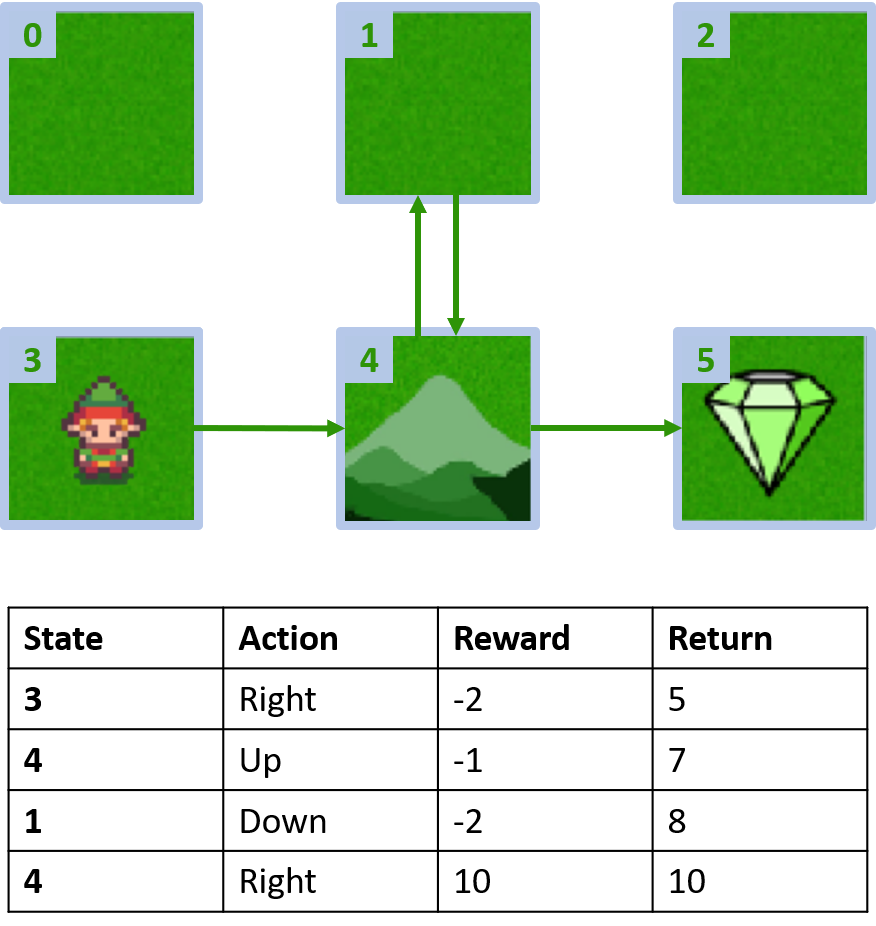
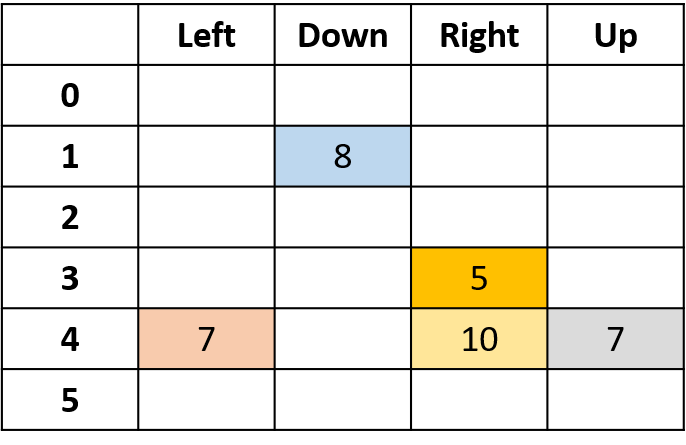
Estimating Q-values
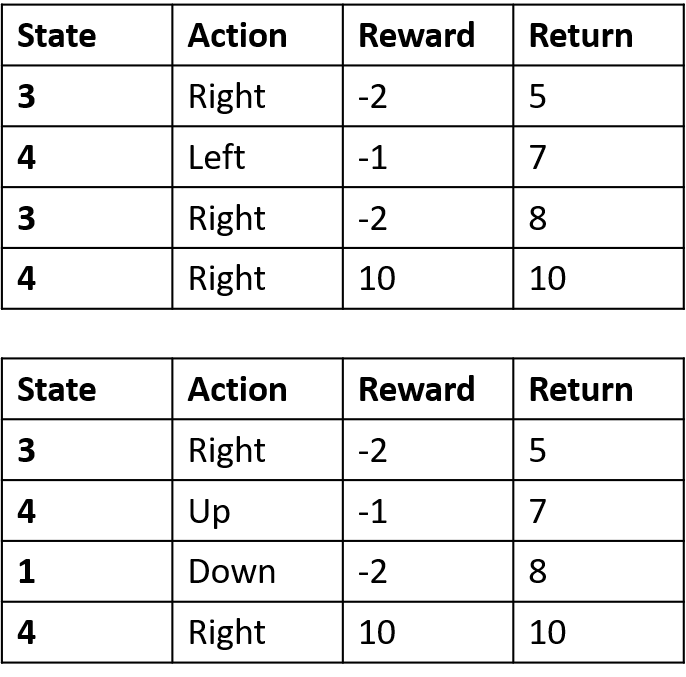
- Q-table: table for Q-values
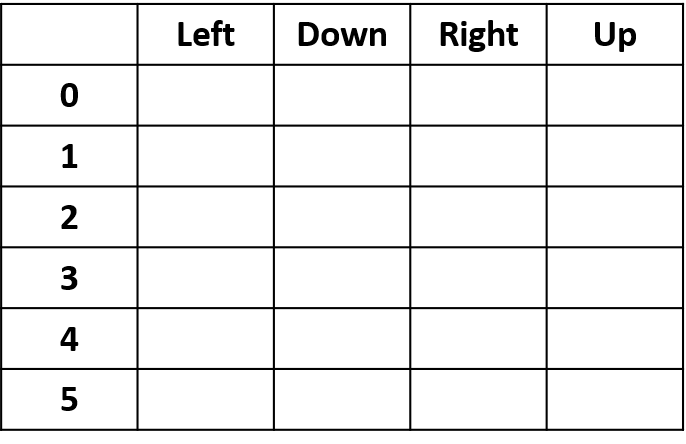
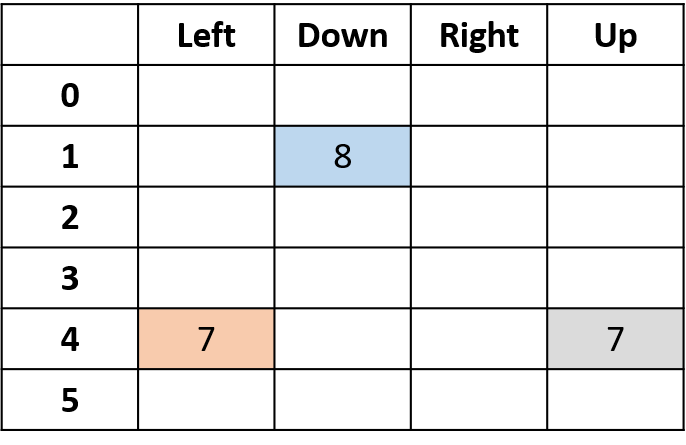
Q(4, left), Q(4, up), and Q(1, down)
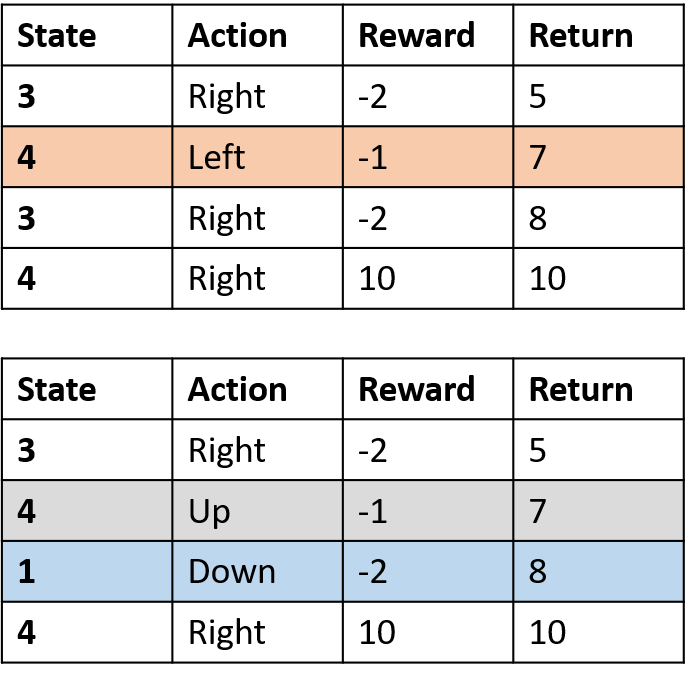
- (s,a) appears once -> fill with return
Q(4, right)
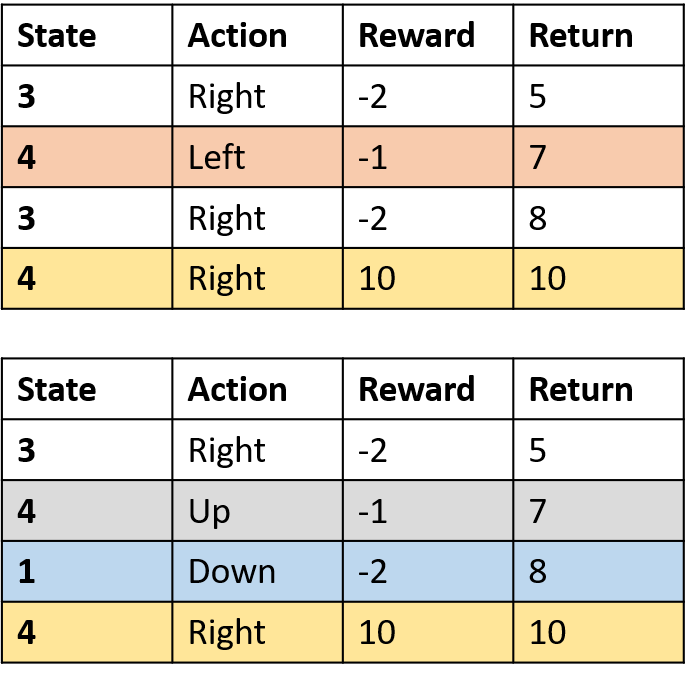
- (s,a) occurs once per episode -> average
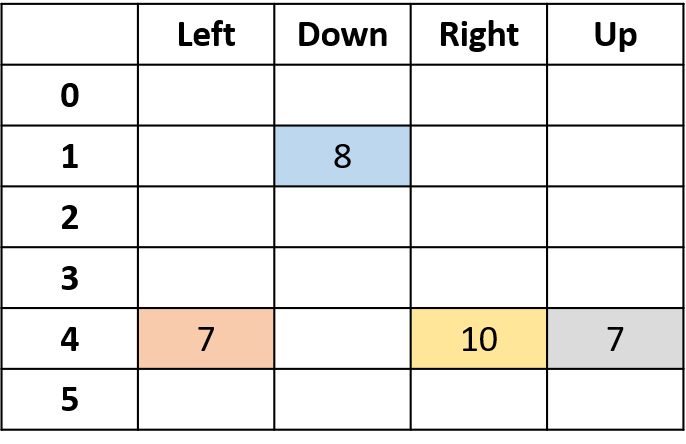
Q(3, right) - first-visit Monte Carlo
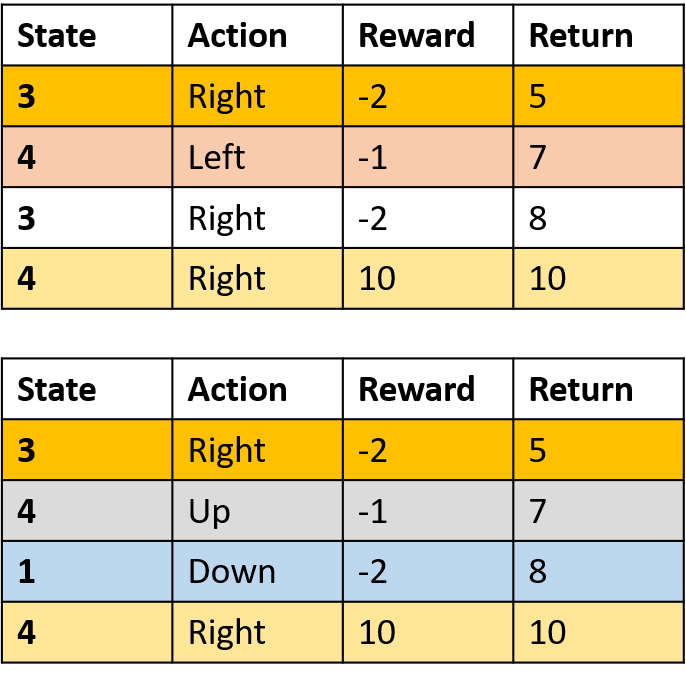
- Average first visit to (s,a) within episodes
Q(3, right) - every-visit Monte Carlo
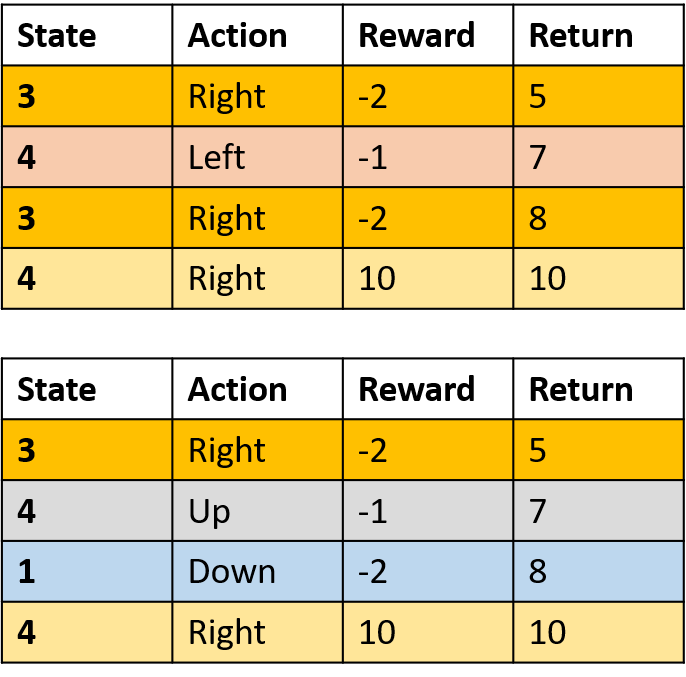
- Average every visit to (s,a) within episodes
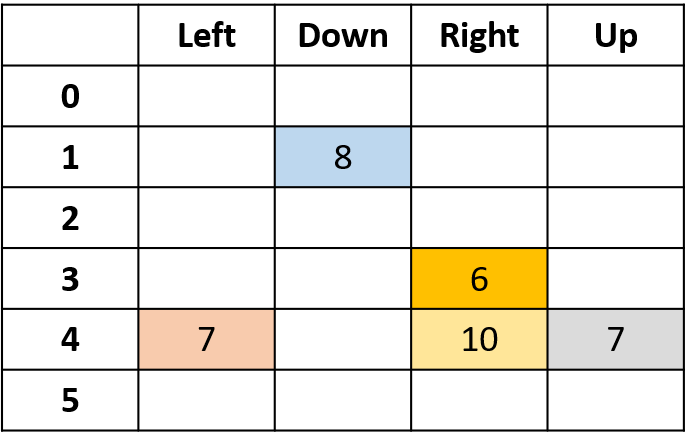
Putting things together