Balancing exploration and exploitation
Reinforcement Learning with Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Training with random actions

Exploration-exploitation trade-off

Dining choices

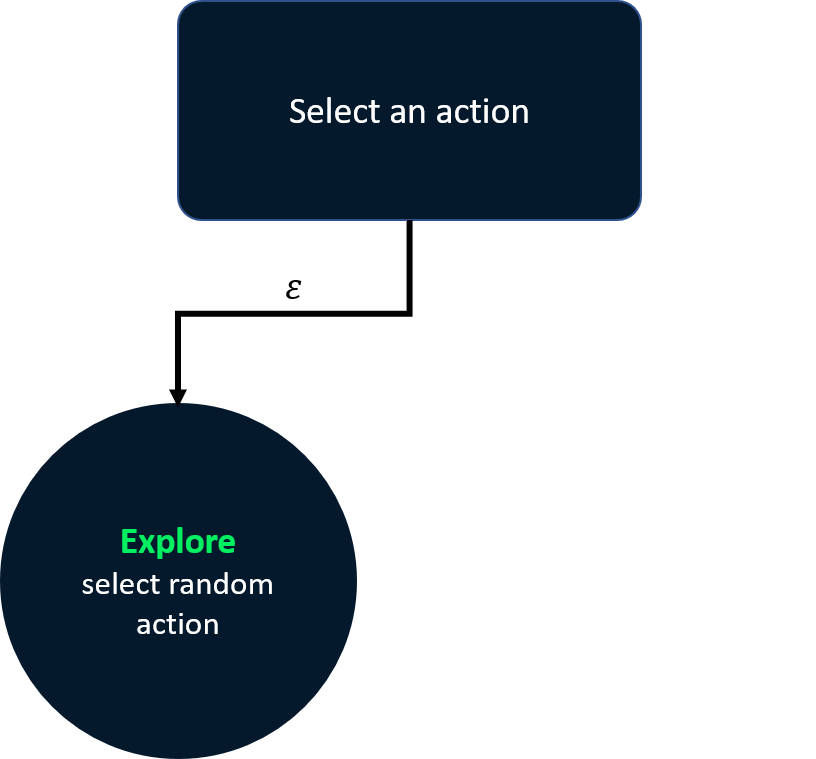
Epsilon-greedy strategy
Epsilon-greedy strategy
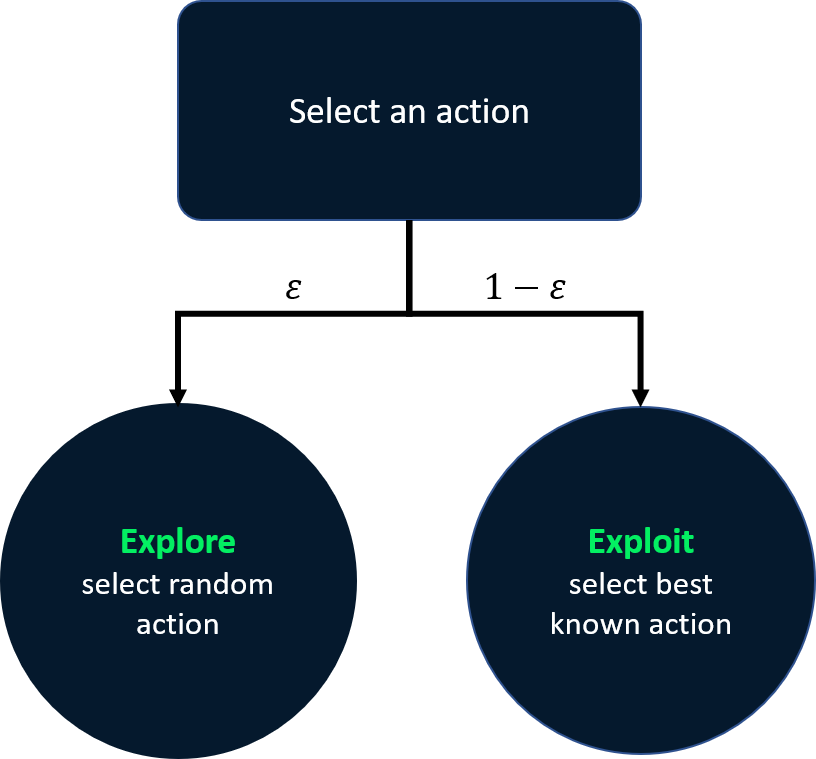
Decayed epsilon-greedy strategy

Implementation with Frozen Lake

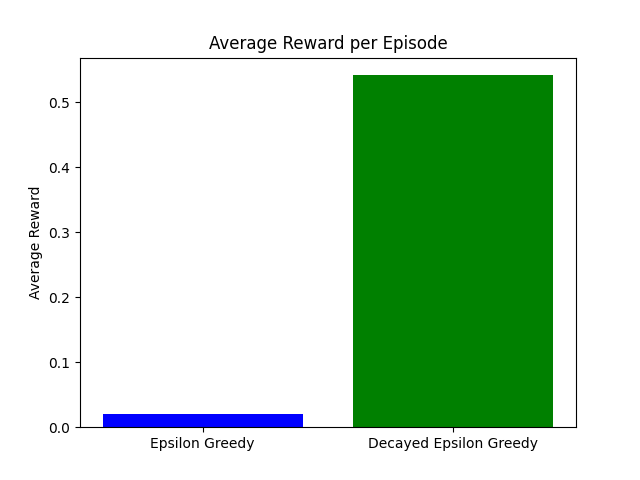
Comparing strategies