Double Q-learning
Reinforcement Learning with Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Q-learning
- Estimates optimal action-value function
- Overestimates Q-values by updating based on max Q
- Might lead to suboptimal policy learning

Double Q-learning
- Maintains two Q-tables
- Each table updated based on the other
- Reduces risk of Q-values overestimation
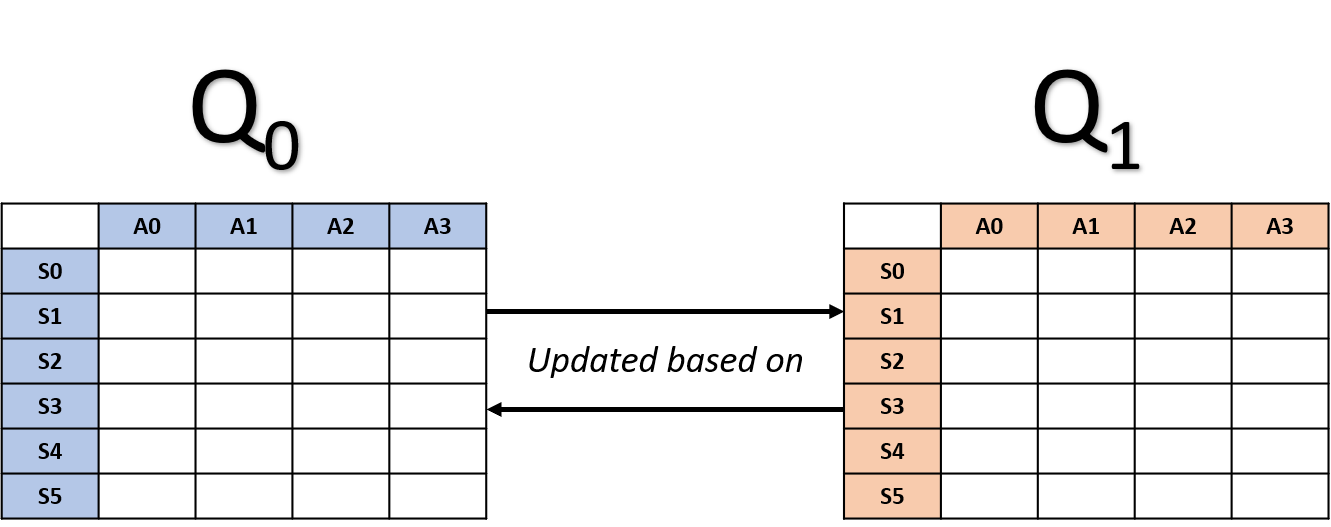
Double Q-learning updates
- Randomly select a table
Q0 update
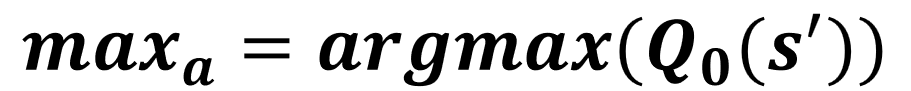
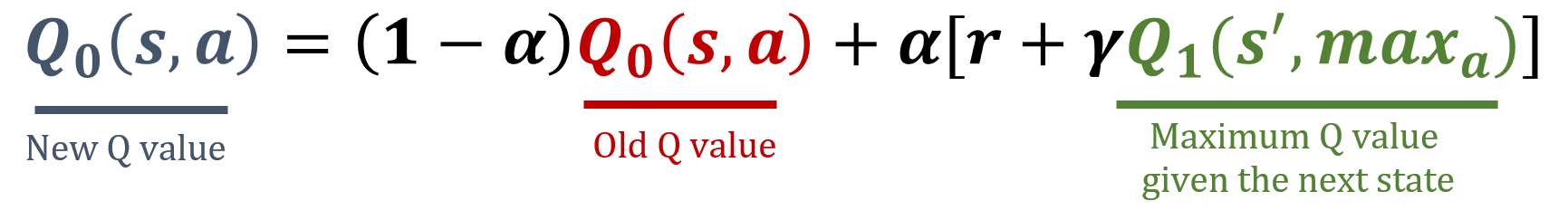
Q1 update
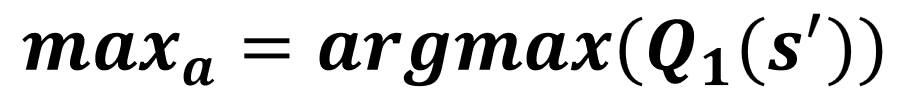
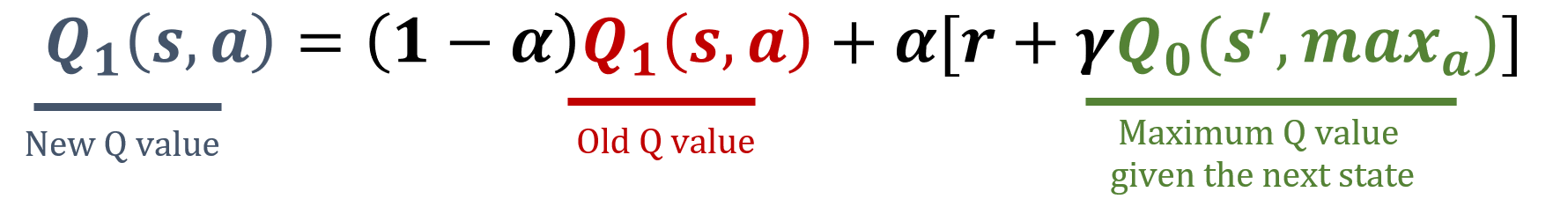
Double Q-learning
- Reduces overestimation bias
- Alternates between Q0 and Q1 updates
- Both tables contribute to learning process
Implementation with Frozen Lake

Implementing update_q_tables()
def update_q_tables(state, action, reward, next_state): # Select a random Q-table index (0 or 1) i = np.random.randint(2)# Update the corresponding Q-table best_next_action = np.argmax(Q[i][next_state])Q[i][state, action] = (1 - alpha) * Q[i][state, action] + alpha * (reward + gamma * Q[1-i][next_state, best_next_action])
Agent's policy