Action-value functions
Reinforcement Learning with Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Action-value functions (Q-values)
- Expected return of:
- Starting at a state $s$
- Taking action $a$
- Following the policy
- Estimates desirability of actions within states
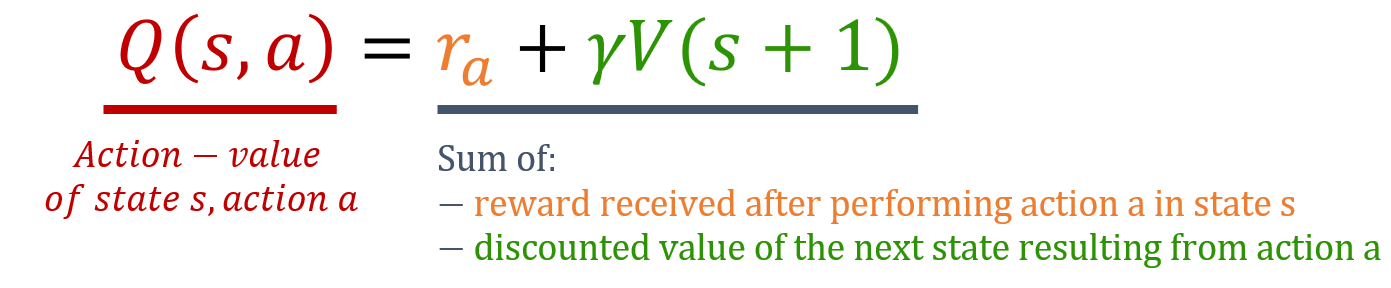
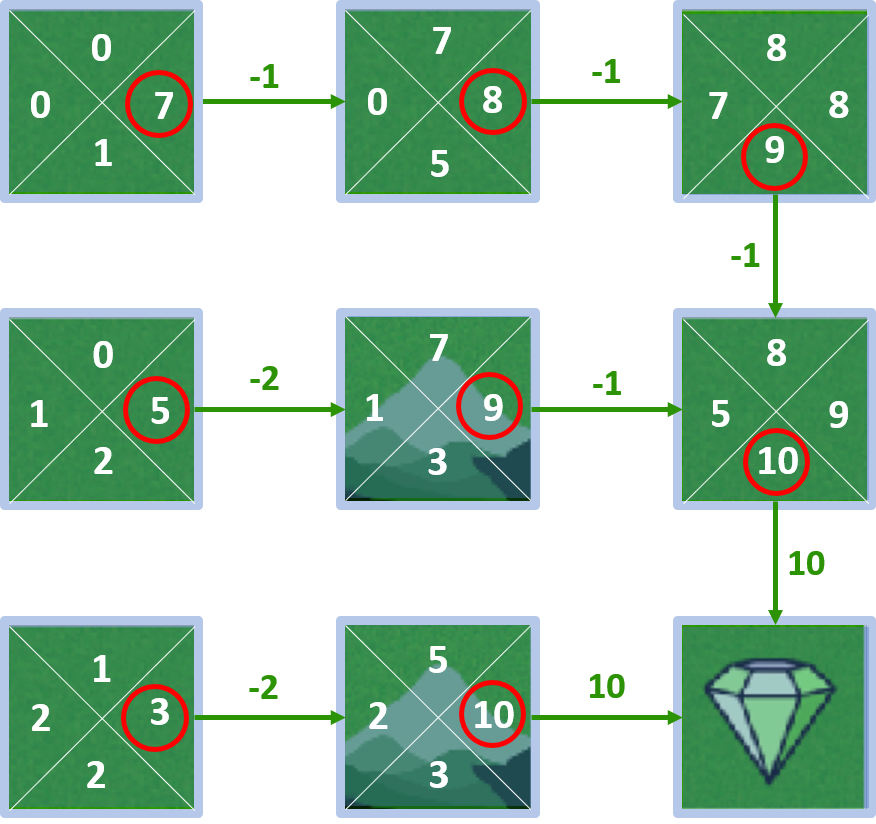
Grid world

- State-values
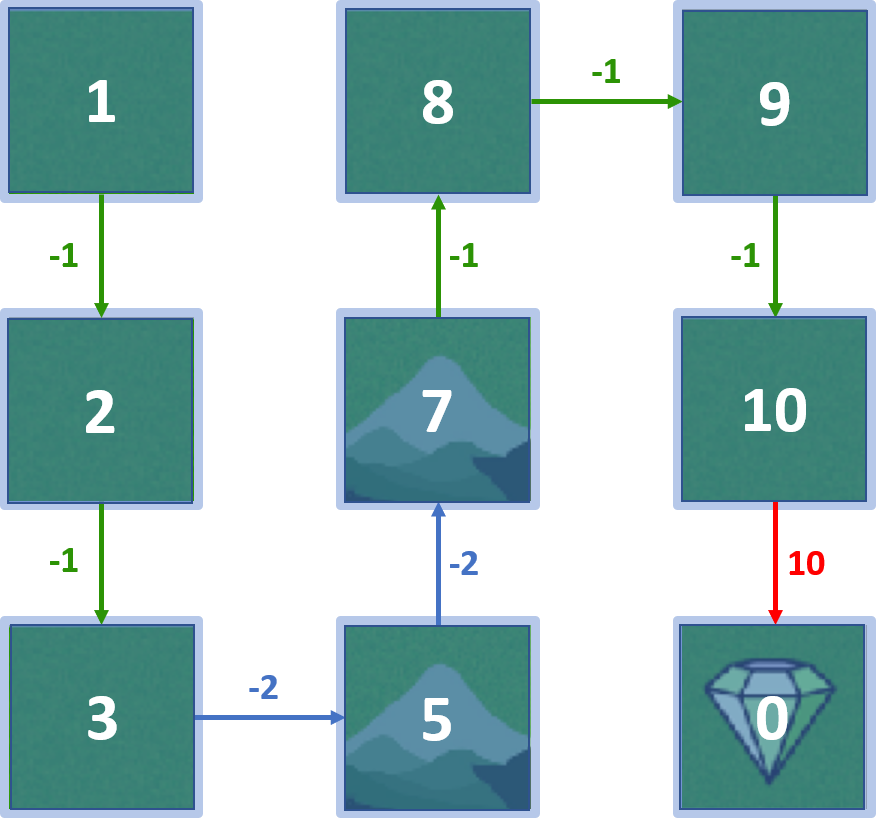
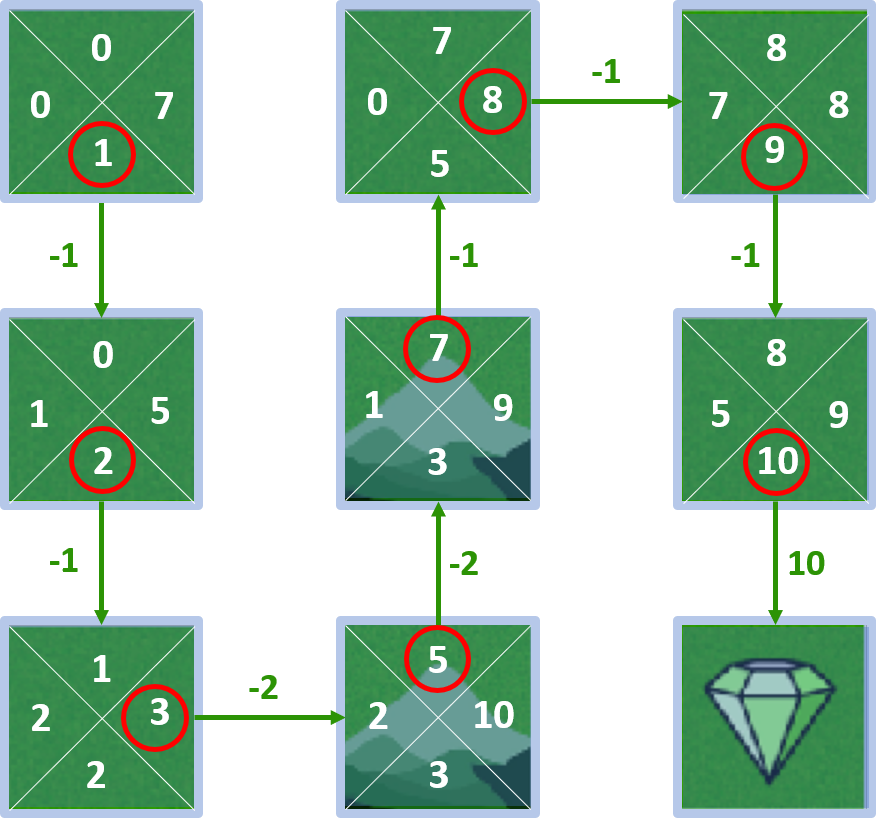
Q-values - state 4
- Agent born in state 4
Q-values - state 4
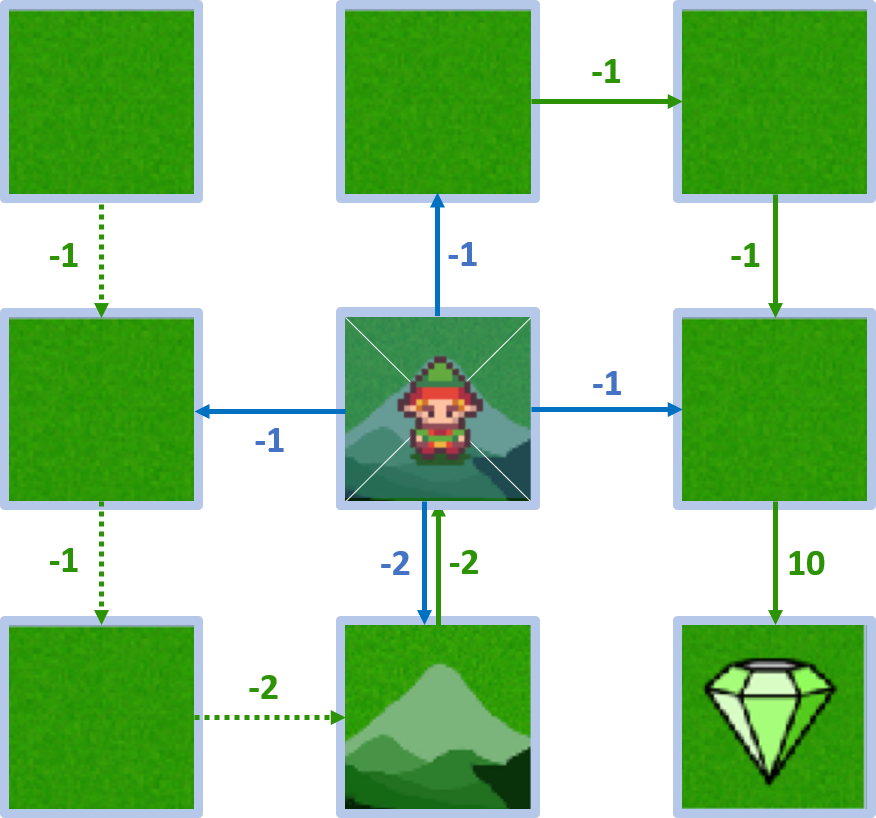
- Agent can move up, down, left, right
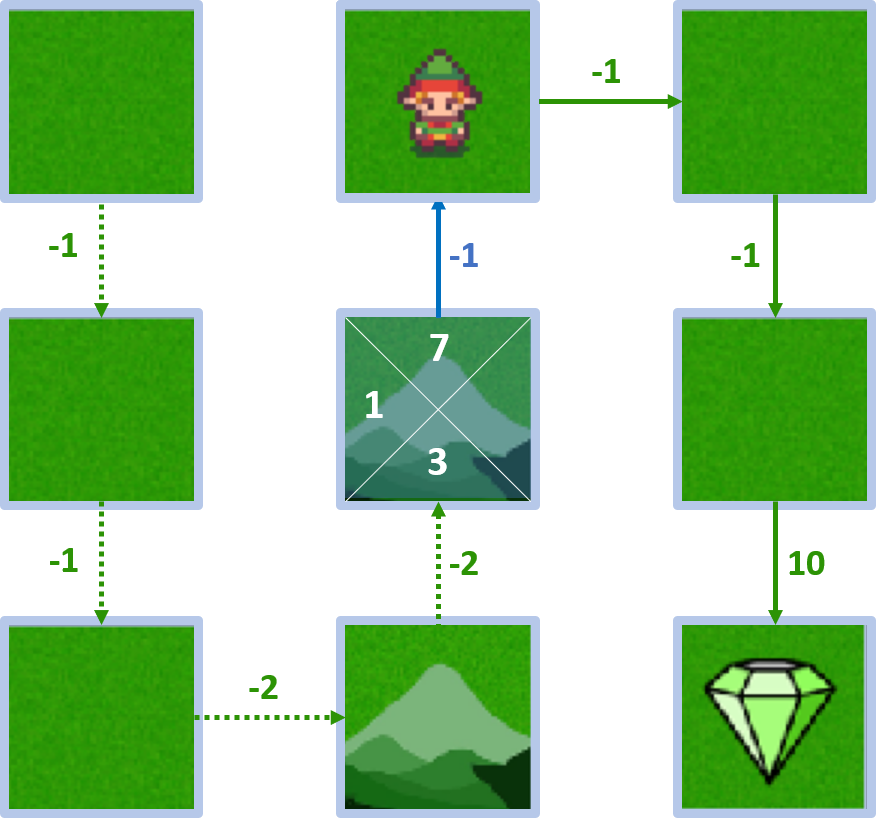
State 4 - action down
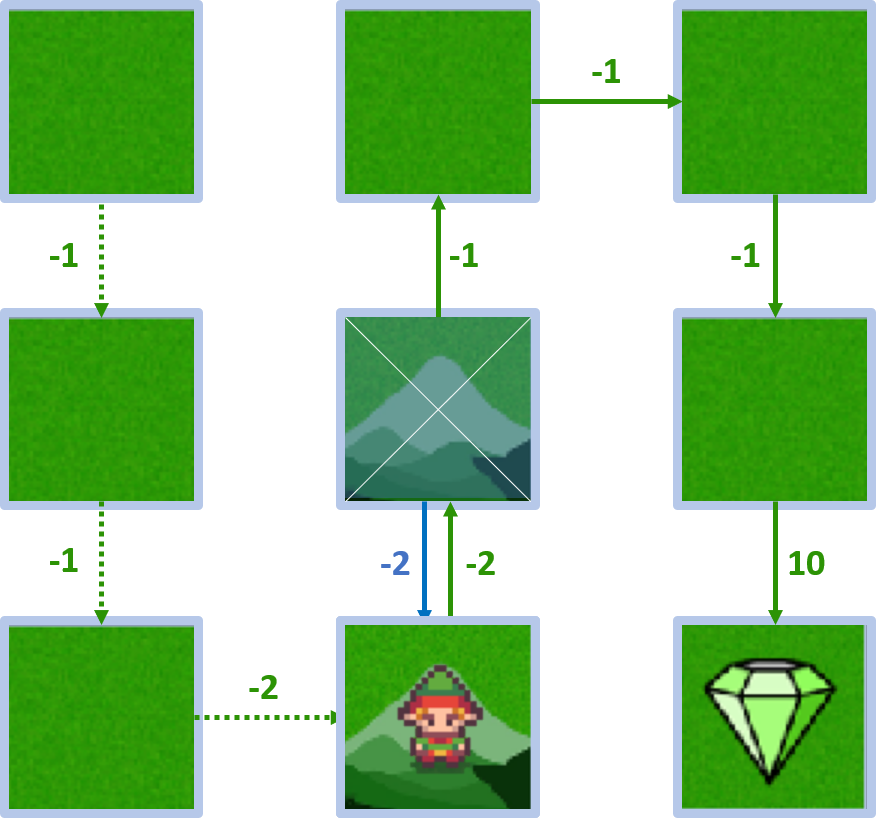
- Reward: -2, state-value: 5
State 4 - action down
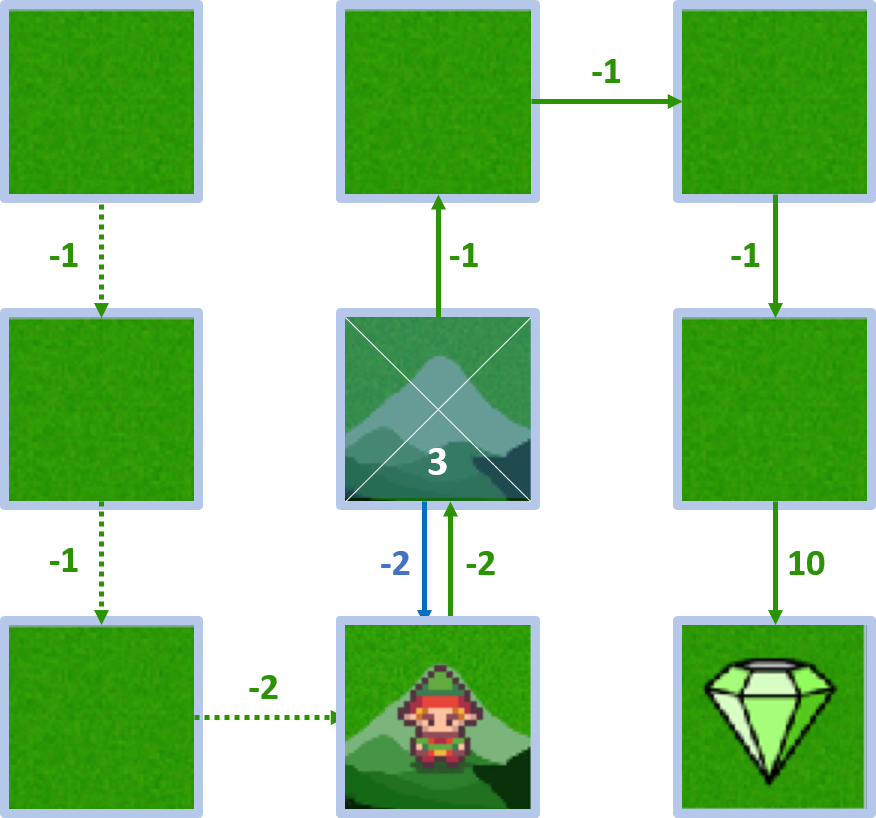
- $Q(4, \text{down}) = -2 + 1 \times 5 = 3$
State 4 - action left
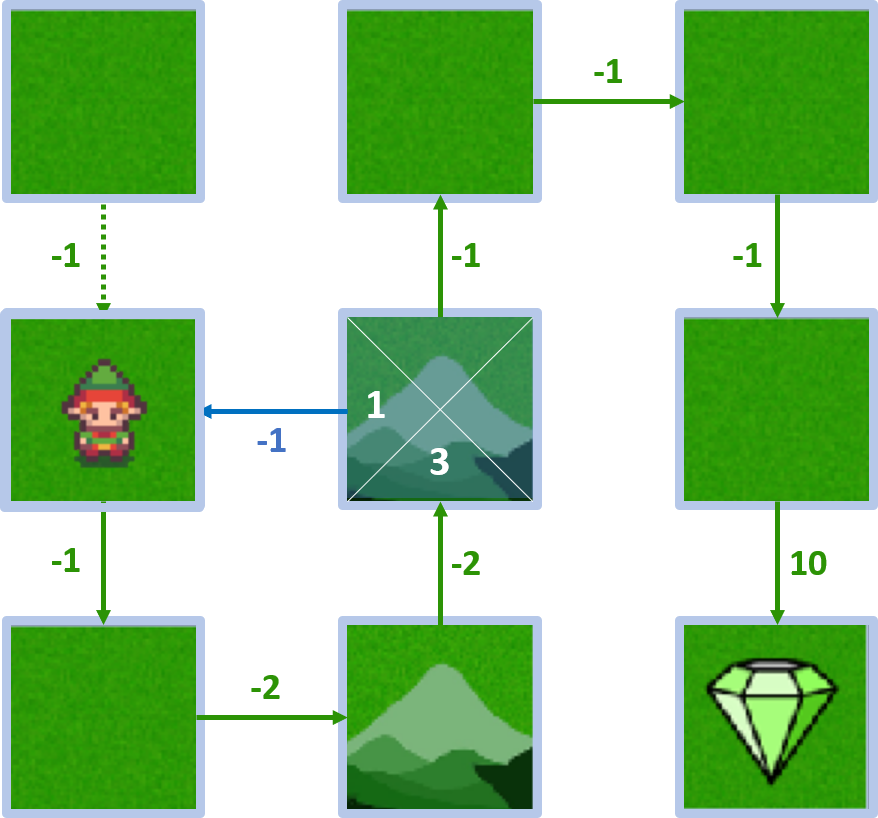
- $Q(4, \text{left}) = -1 + 1 \times 2 = 1$
State 4 - action up
- $Q(4, \text{up}) = -1 + 1 \times 8 = 7$
State 4 - action right
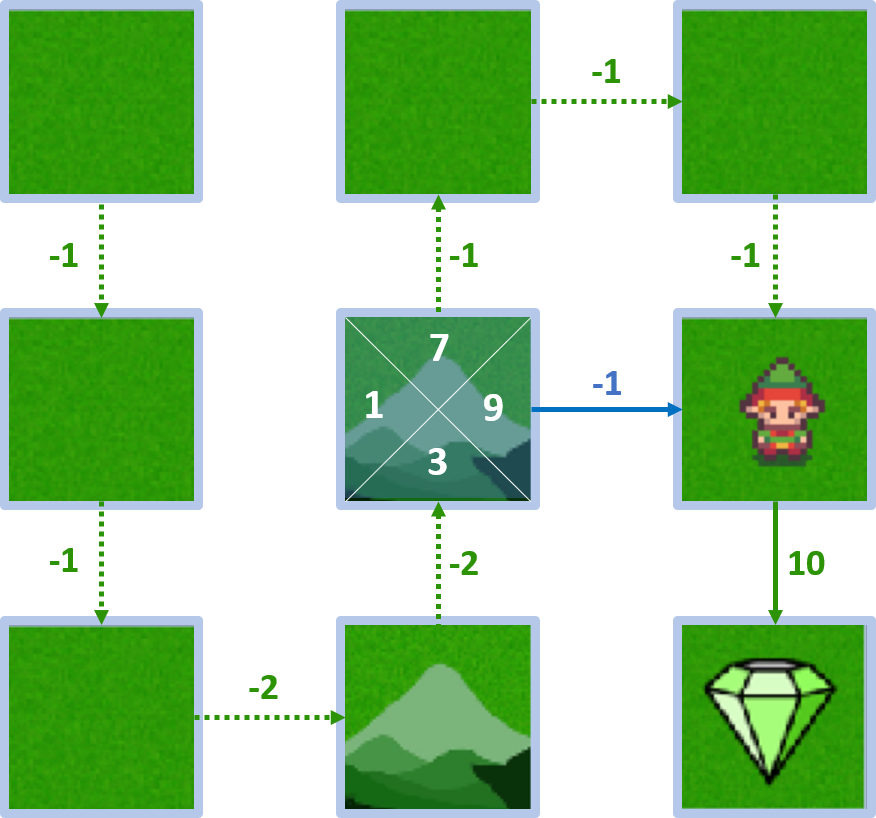
- $Q(4, \text{right}) = -1 + 1 \times 10 = 9$
All Q-values
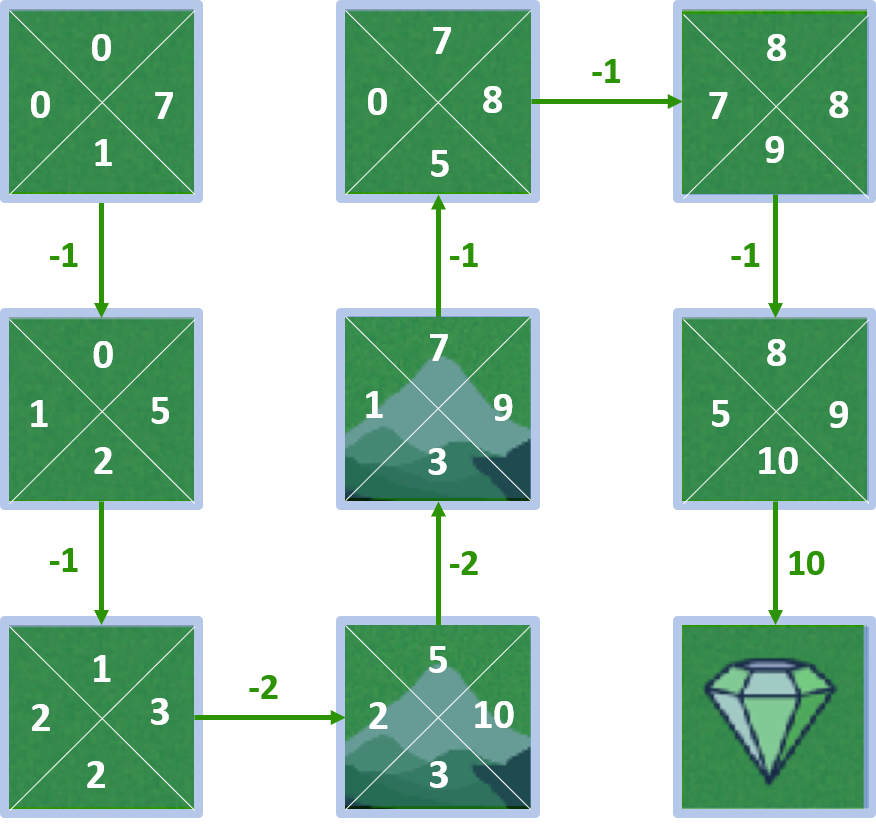
Computing Q-values
def compute_q_value(state, action):if state == terminal_state: return None_, next_state, reward, _ = env.unwrapped.P[state][action][0] return reward + gamma * compute_state_value(next_state)
Computing Q-values
Improving the policy
Improving the policy
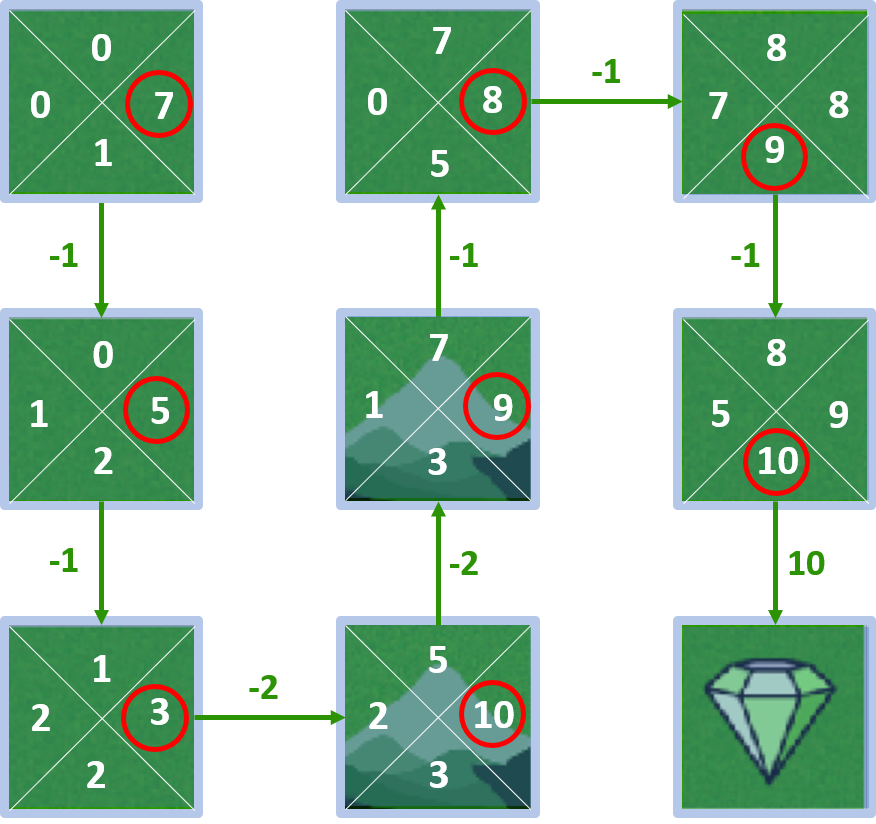
Improving the policy
 Old policy
Old policy