Expected SARSA
Reinforcement Learning with Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Expected SARSA
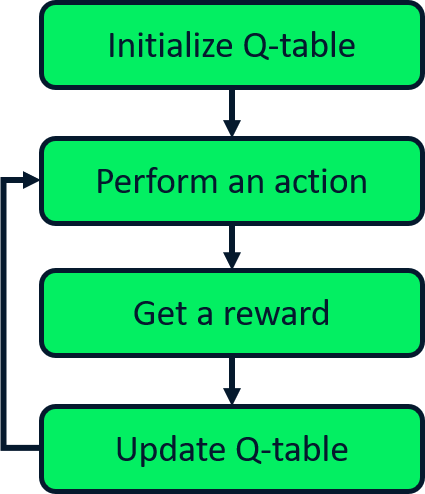
Expected SARSA update
SARSA

Q-learning

Expected SARSA
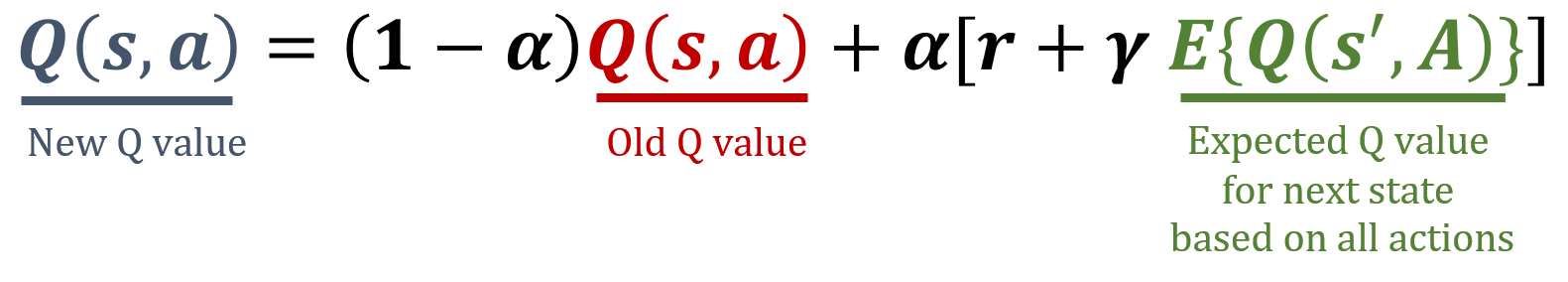
Expected value of next sate
- Takes into account all actions

- Random actions → equal probabilities

Implementation with Frozen Lake

Expected SARSA update rule
def update_q_table(state, action, next_state, reward):expected_q = np.mean(Q[next_state])Q[state, action] = (1-alpha) * Q[state, action] + alpha * (reward + gamma * expected_q)
Agent's policy