Policy iteration and value iteration
Reinforcement Learning with Gymnasium in Python

Fouad Trad
Machine Learning Engineer
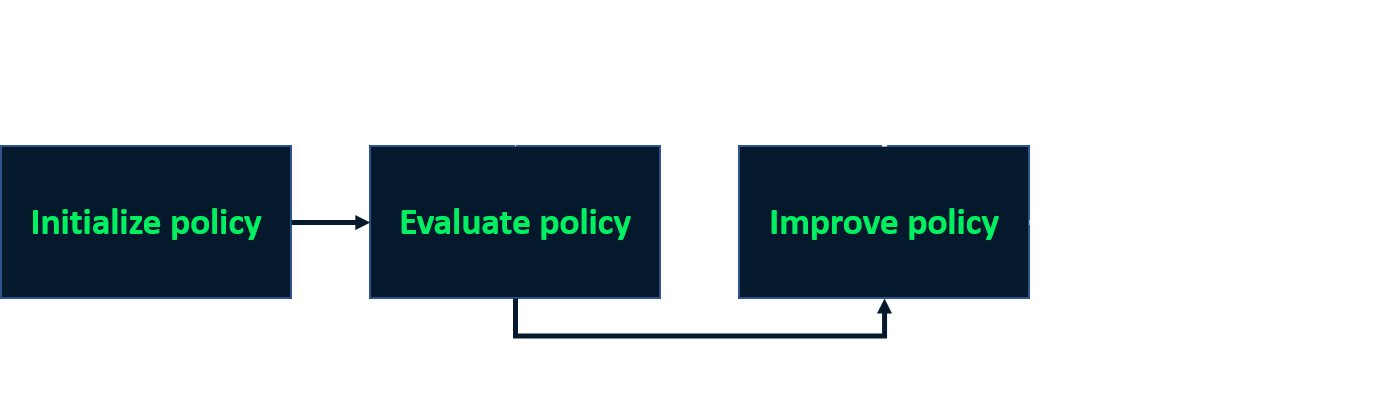
Policy iteration
- Iterative process to find optimal policy

Policy iteration
- Iterative process to find optimal policy

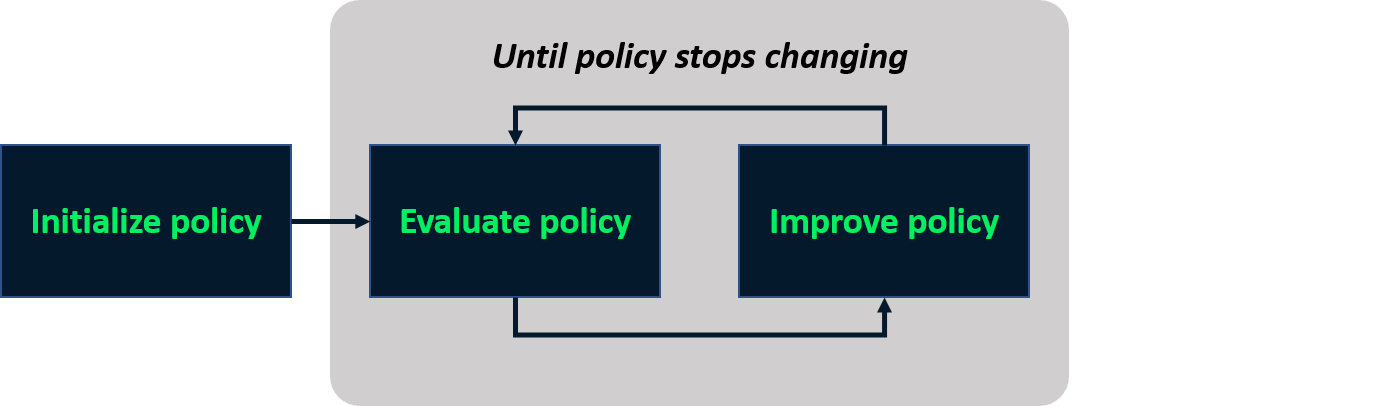
Policy iteration
- Iterative process to find optimal policy
Policy iteration
- Iterative process to find optimal policy
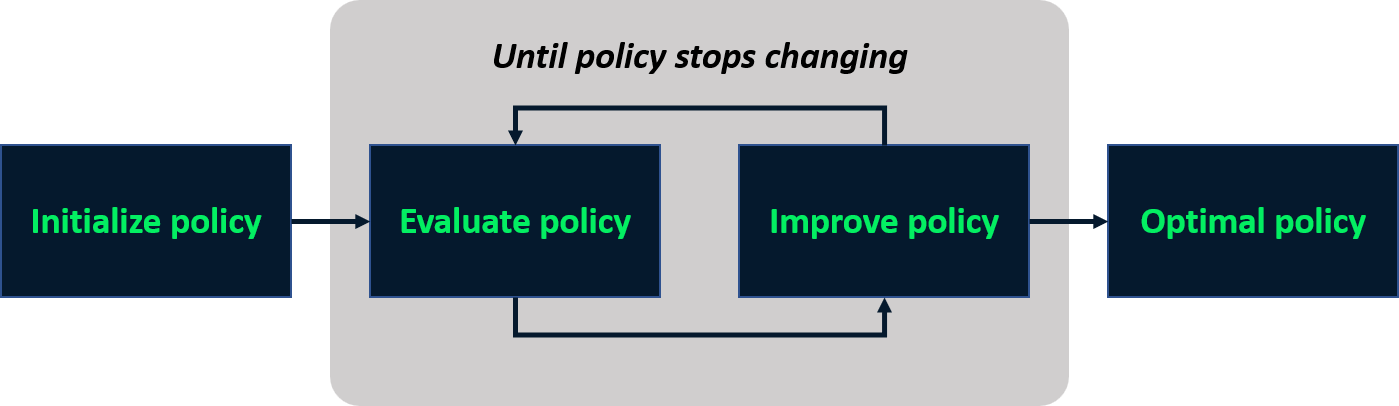
Policy iteration
- Iterative process to find optimal policy
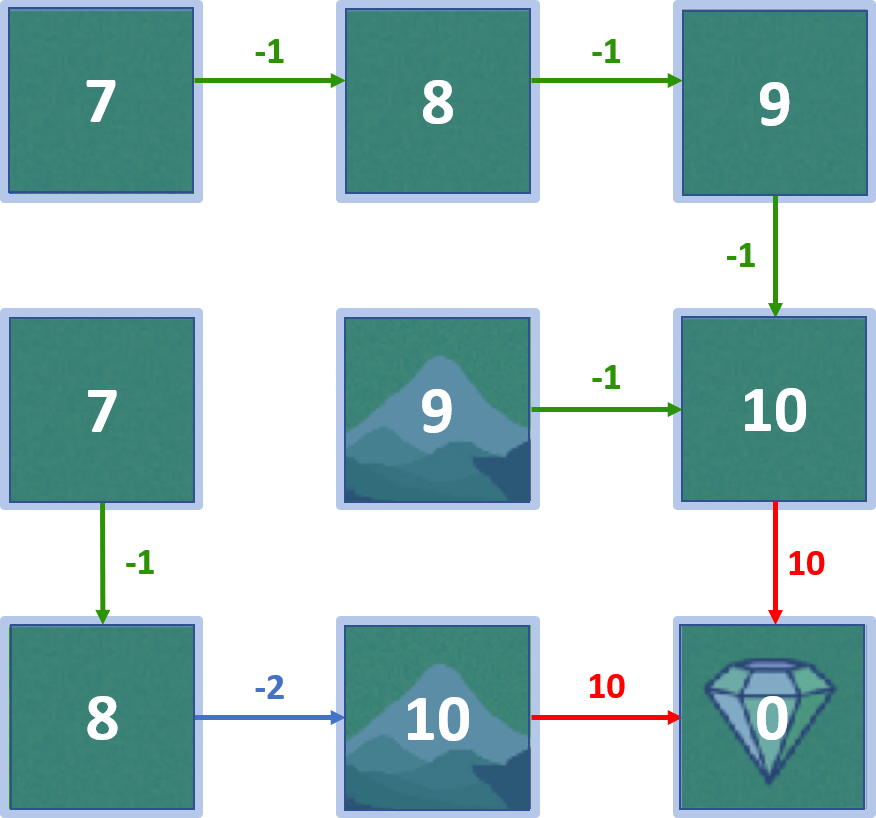
Grid world
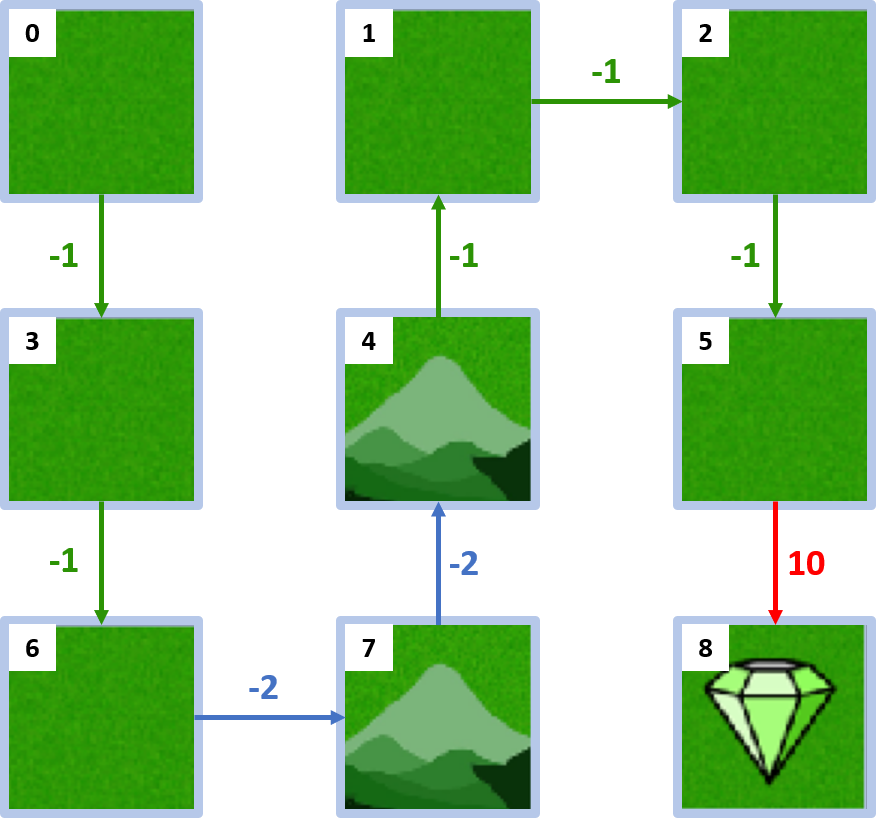
Optimal policy
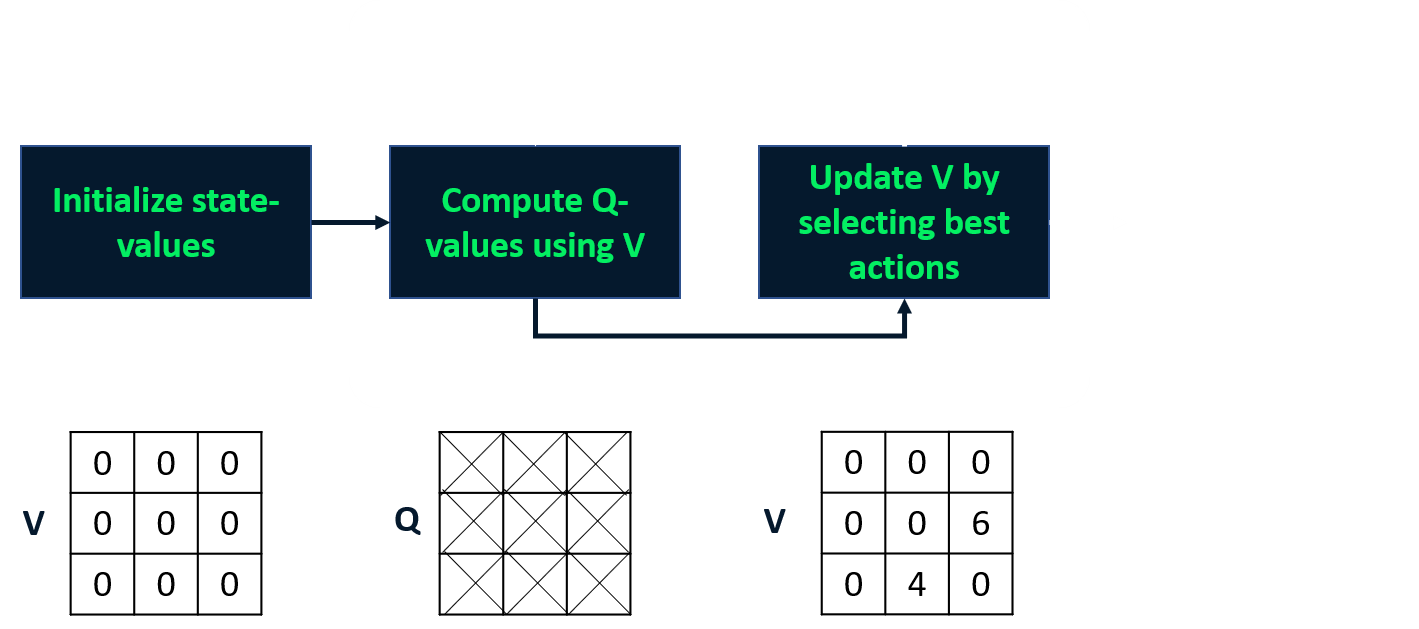
Value iteration
- Combines policy evaluation and improvement in one step
- Computes optimal state-value function
- Derives policy from it

Value iteration
- Combines policy evaluation and improvement in one step.
- Computes optimal state-value function
- Derives policy from it

Value iteration
- Combines policy evaluation and improvement in one step.
- Computes optimal state-value function
- Derives policy from it
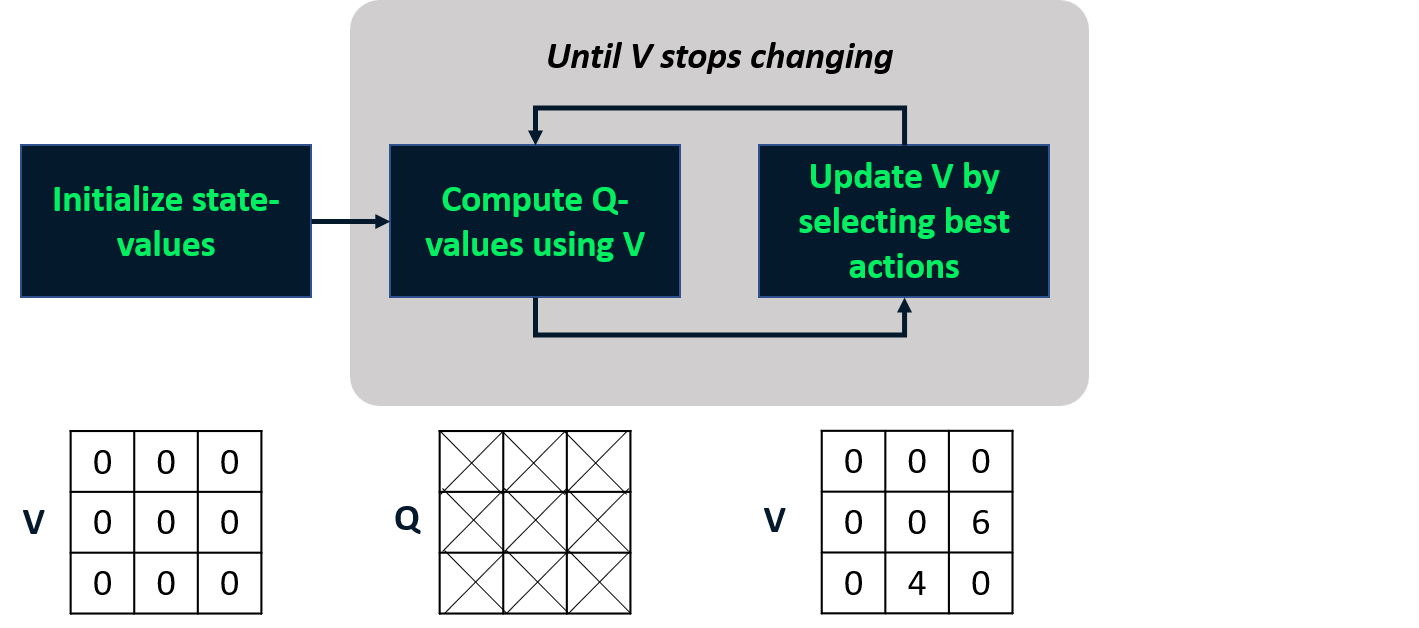
Value iteration
- Combines policy evaluation and improvement in one step.
- Computes optimal state-value function
- Derives policy from it
Value iteration
- Combines policy evaluation and improvement in one step.
- Computes optimal state-value function
- Derives policy from it
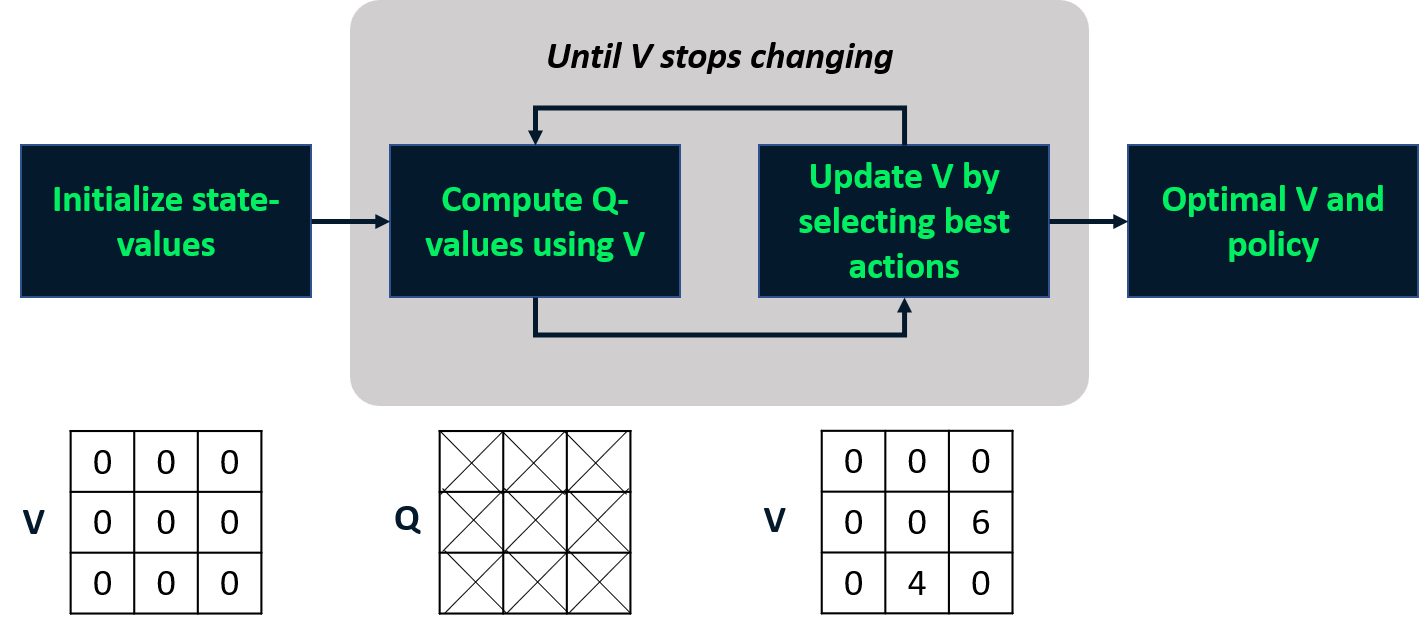
Optimal policy

