Data validation best practices
Responsible AI Data Management

Maria Prokofieva
Lead ML engineer
Subgroup analysis




Missing data
- Common in large datasets
- Data deletion
- Imputation strategies and model-based approaches
- Subgroup analysis for validation
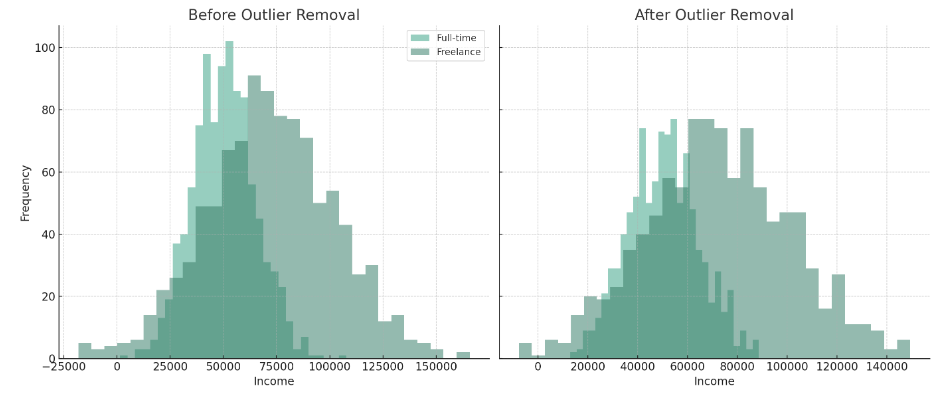
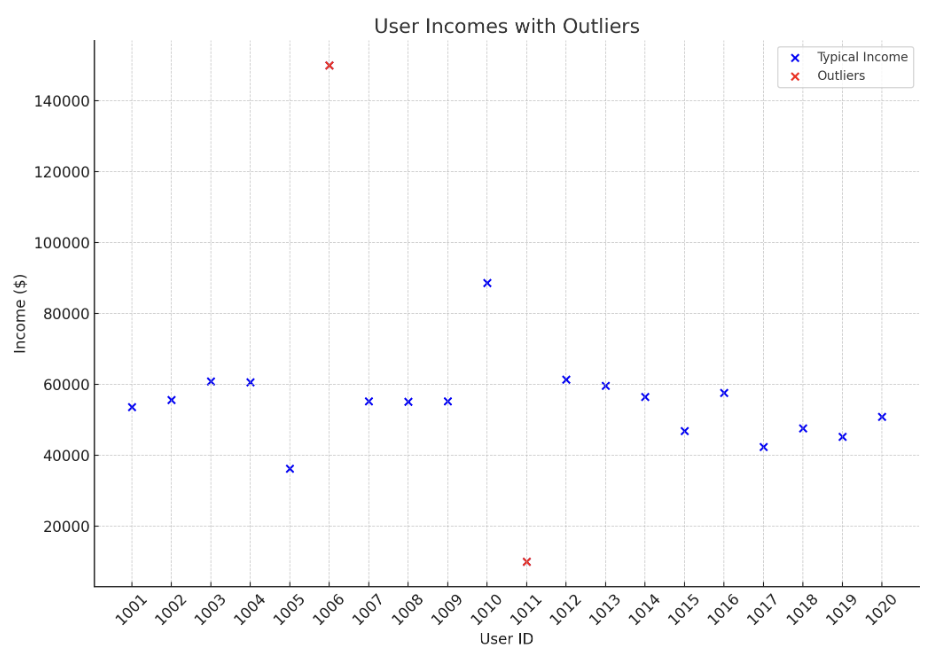
Outlier removal
- Statistical methods like z-scores and IQR, or robust scaling
- Validate for fair treatment across data segments
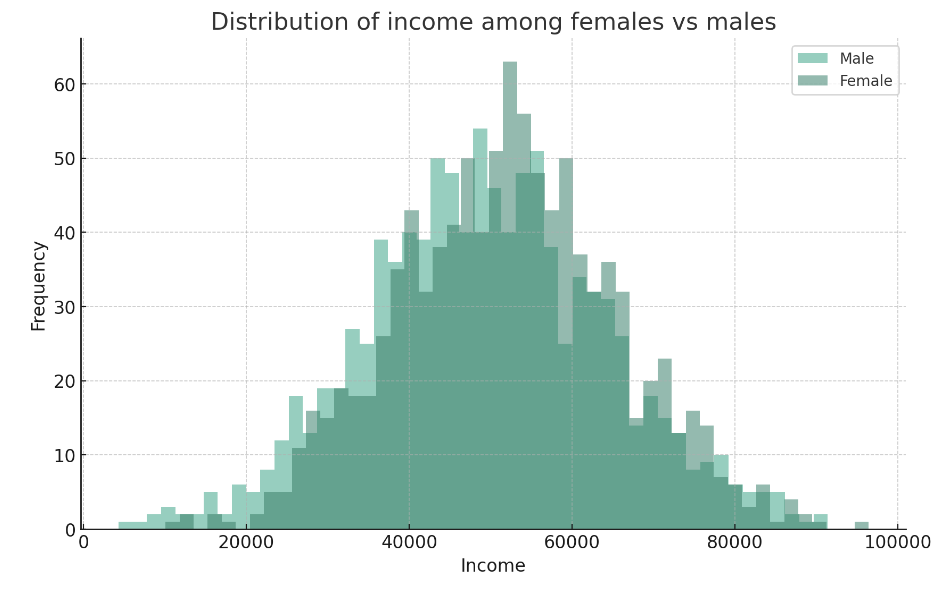
Feature scaling
- Feature scaling to transform input features
- Validate by checking the distributions among groups
Dimensionality reduction
- Reduce input features and preserve essential information
- May create bias
- Use fairness-conscious techniques like t-SNE
Financial advisor
- "Annual income" and "Investment frequency" features
- Adjust outliers and scale
- Subgroup analysis