RAG chatbot with Pinecone and OpenAI
Vector Databases for Embeddings with Pinecone

James Chapman
Curriculum Manager, DataCamp
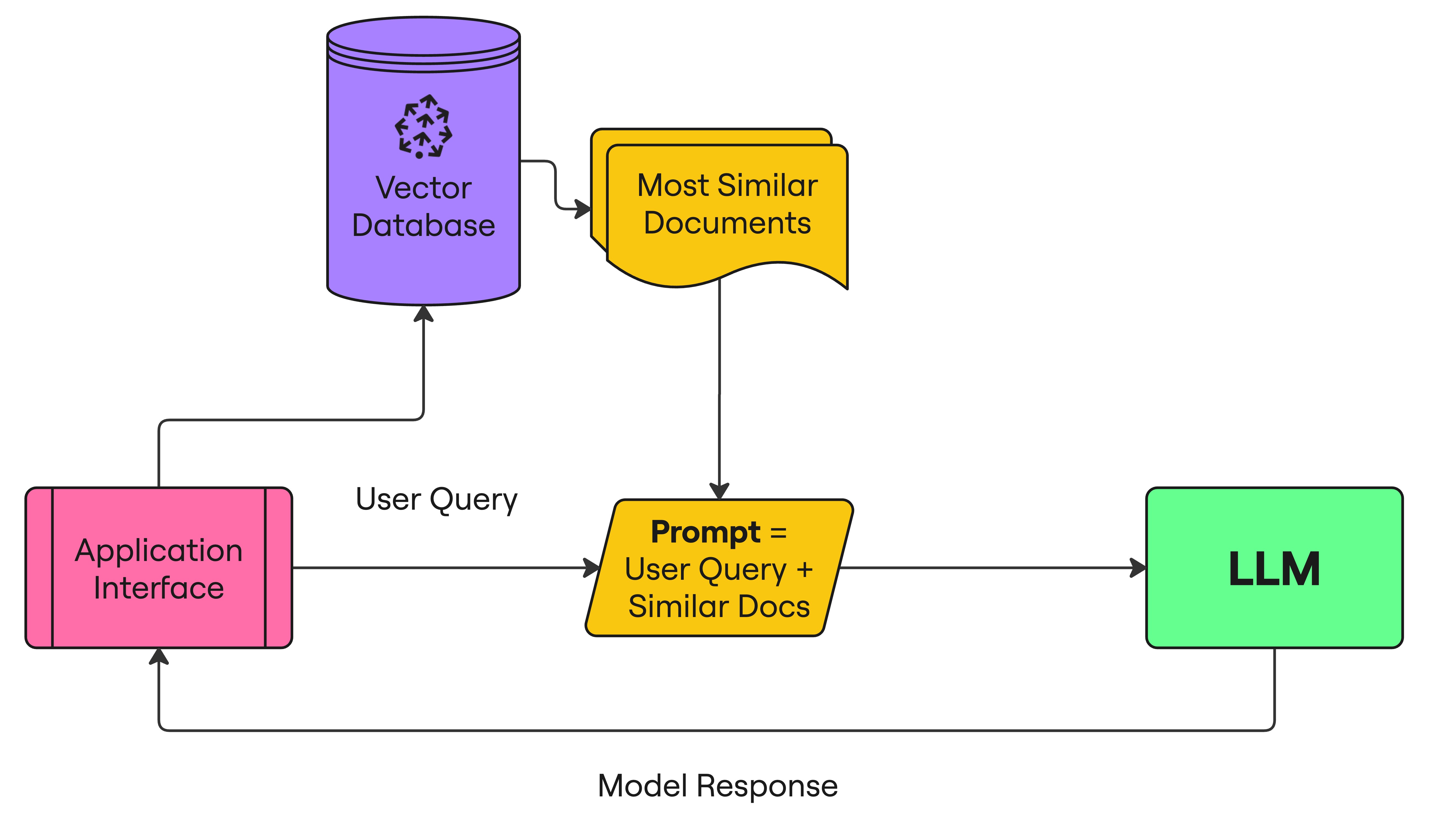
Retrieval Augmented Generation (RAG)
- Embed user query
- Retrieve similar documents
- Added documents to prompt
Prompt with context builder output
query = "How to build next-level Q&A with OpenAI"
context_prompt = prompt_with_context_builder(query, documents)

Question-answering output
query = "How to build next-level Q&A with OpenAI"
answer = question_answering(prompt_with_context, sources,
chat_model='gpt-4o-mini')