Batch updates in policy gradient
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
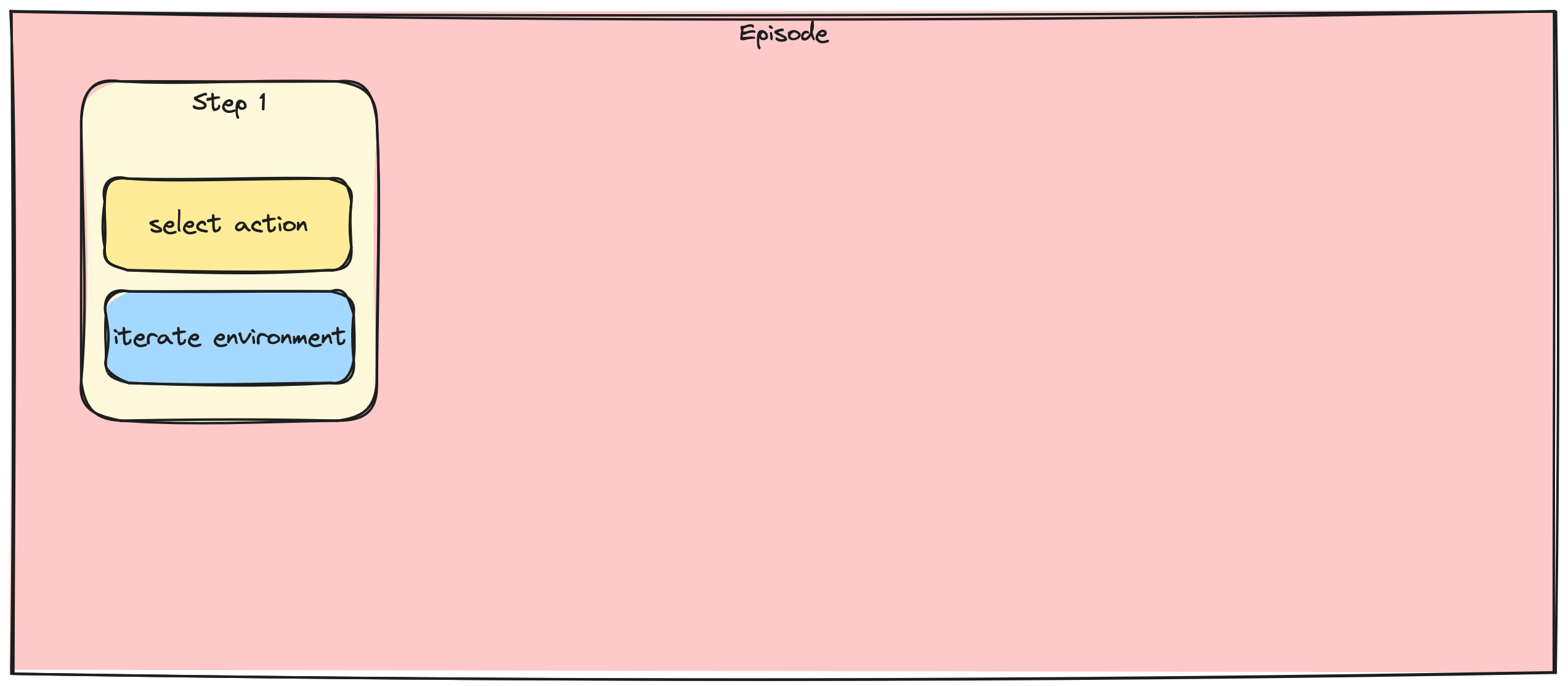
Stepwise vs batch gradient updates

Stepwise vs batch gradient updates

Stepwise vs batch gradient updates
Stepwise vs batch gradient updates

Stepwise vs batch gradient updates
Stepwise vs batch gradient updates
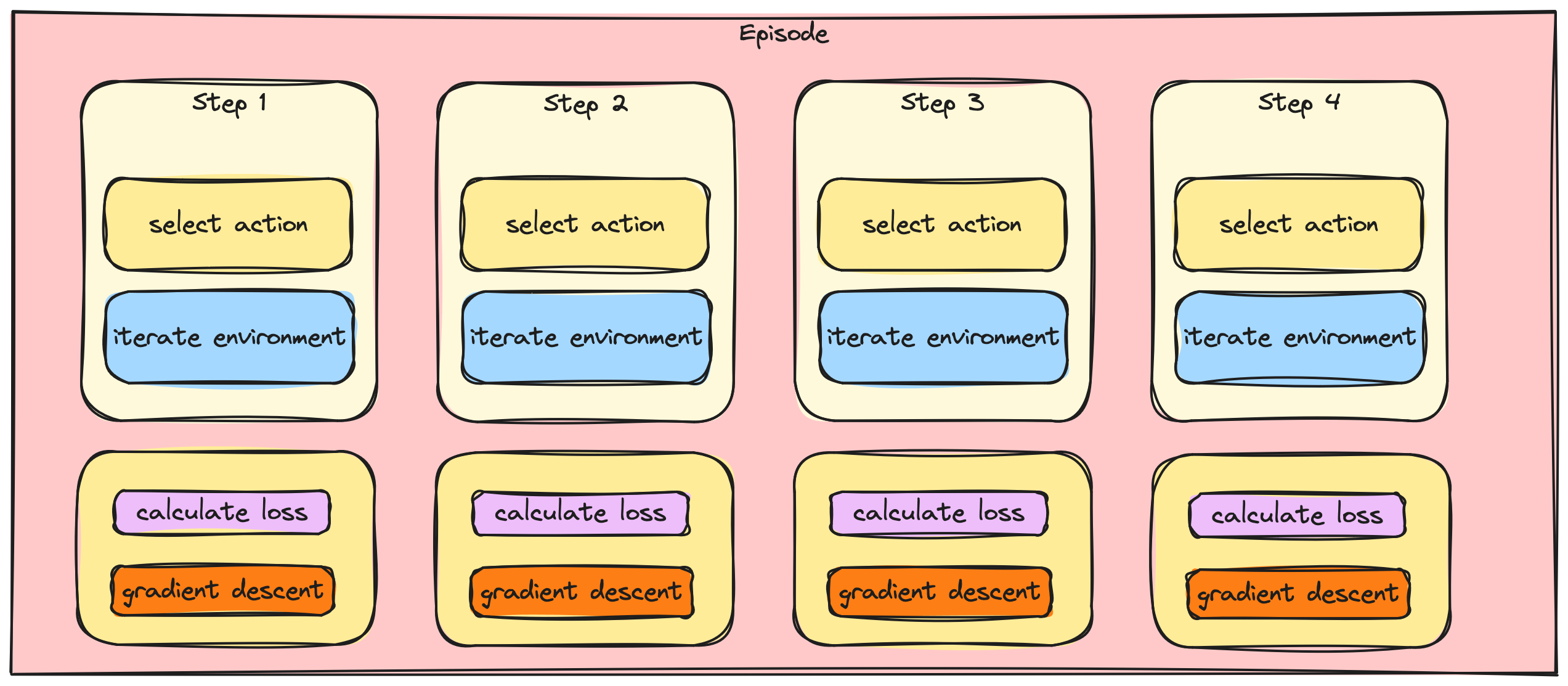
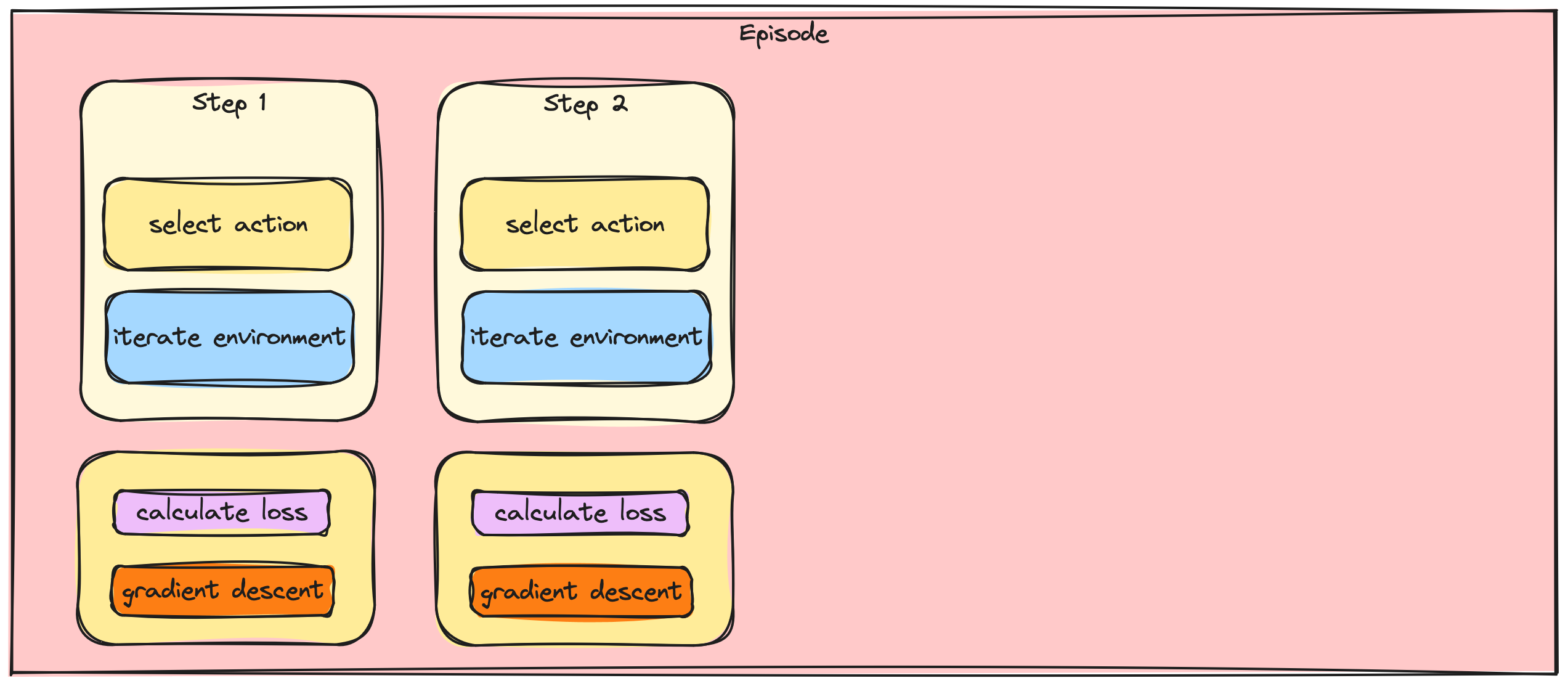
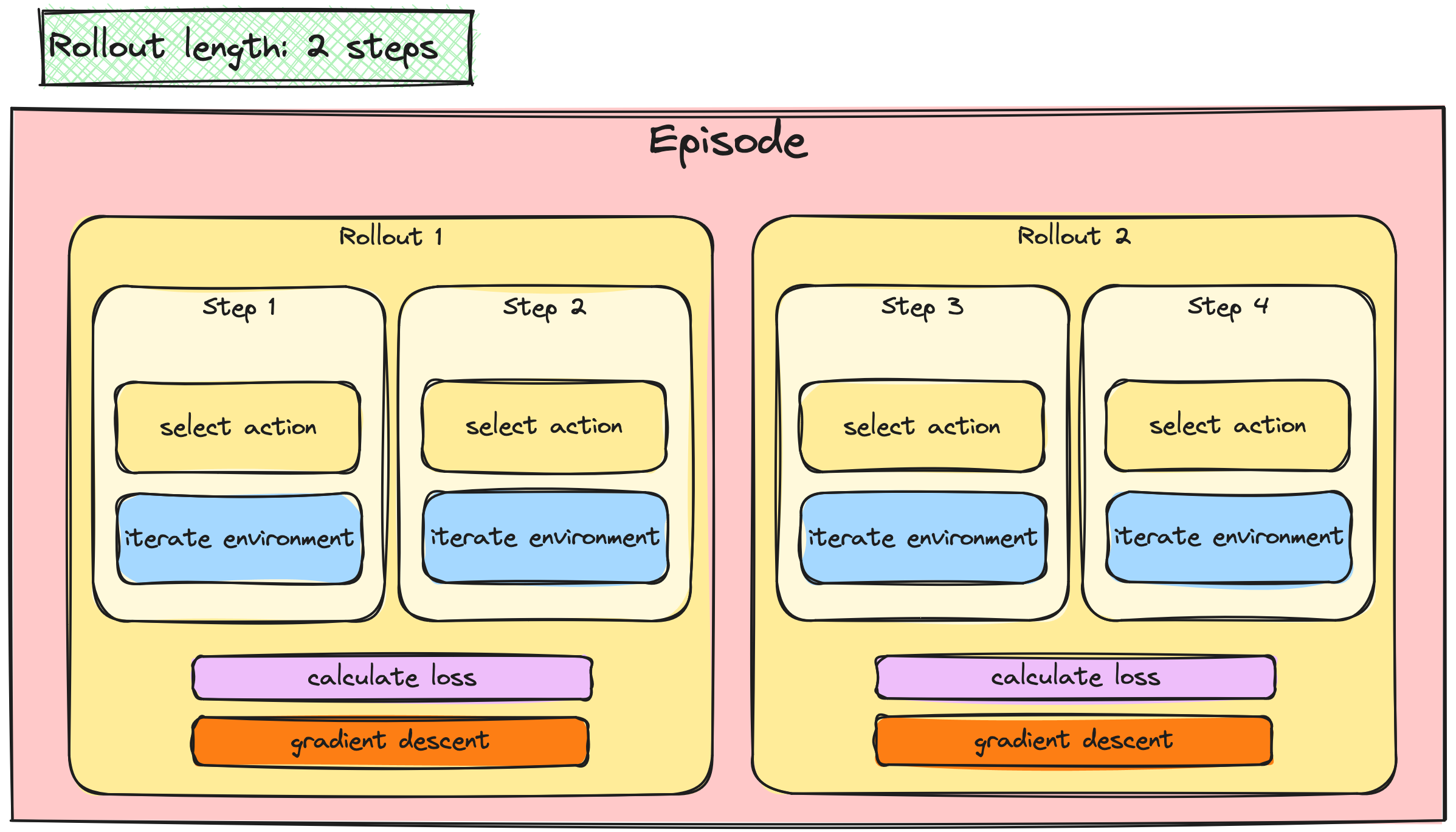
Batching the A2C / PPO updates
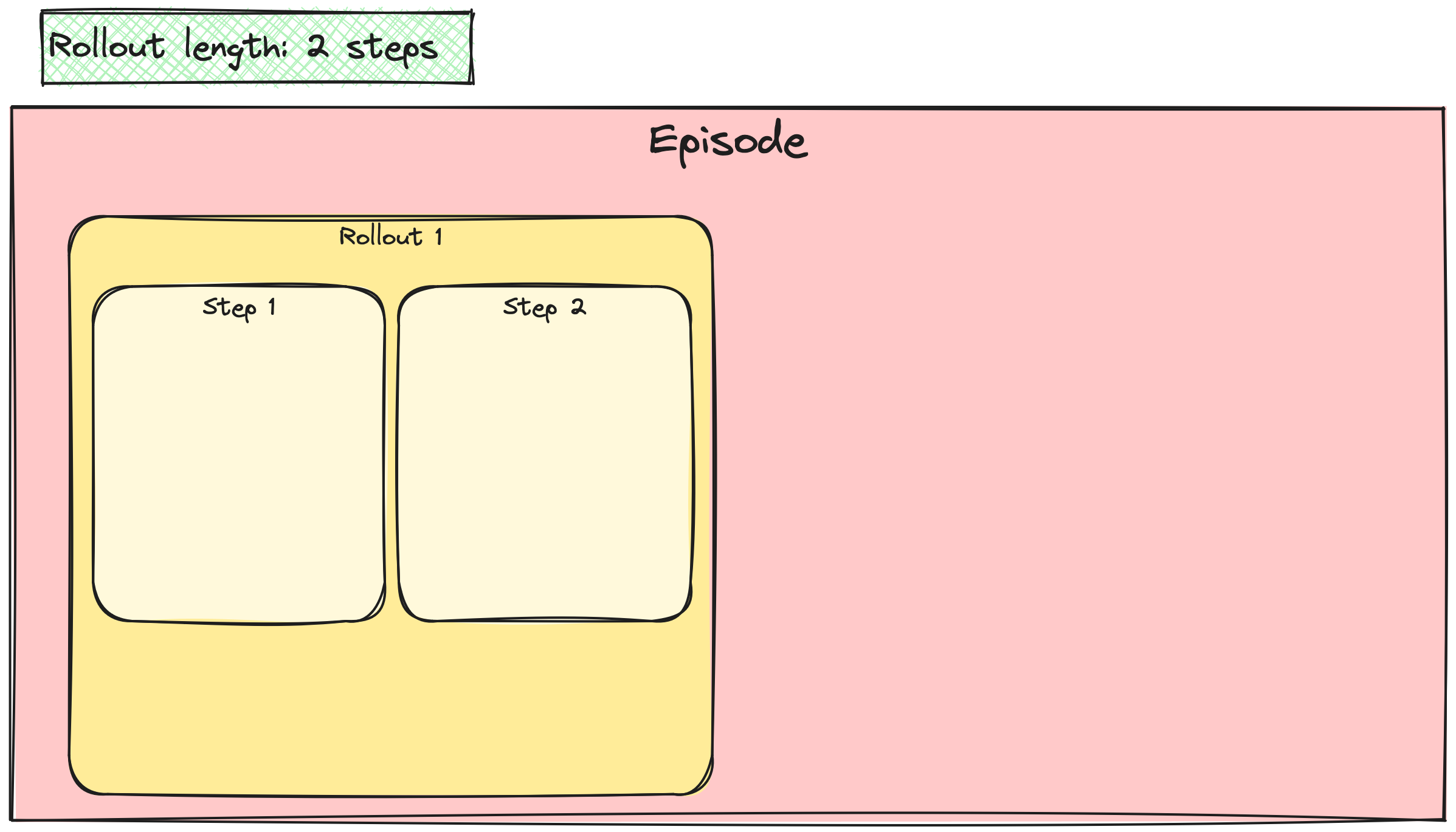
Batching the A2C / PPO updates
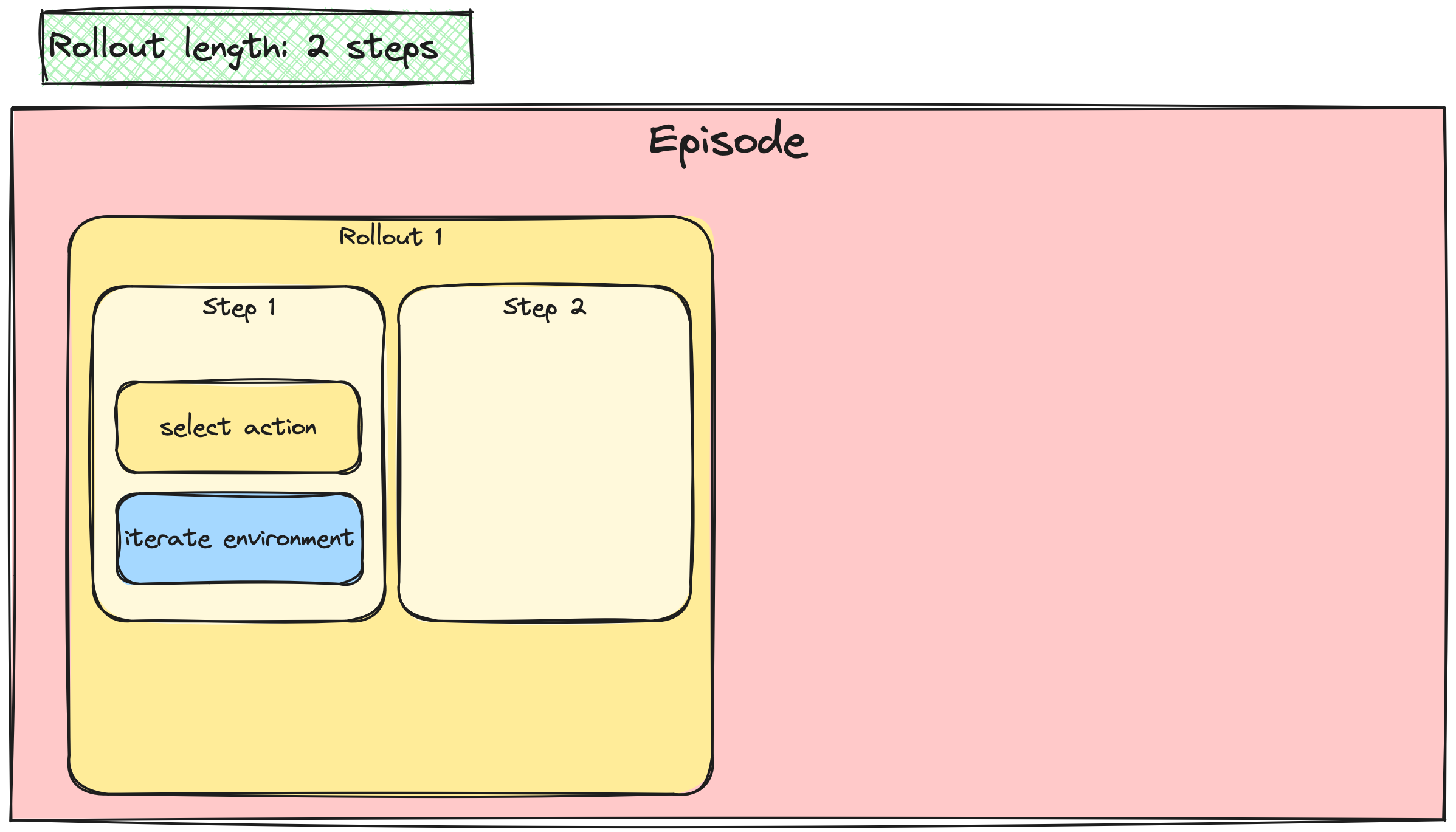
Batching the A2C / PPO updates
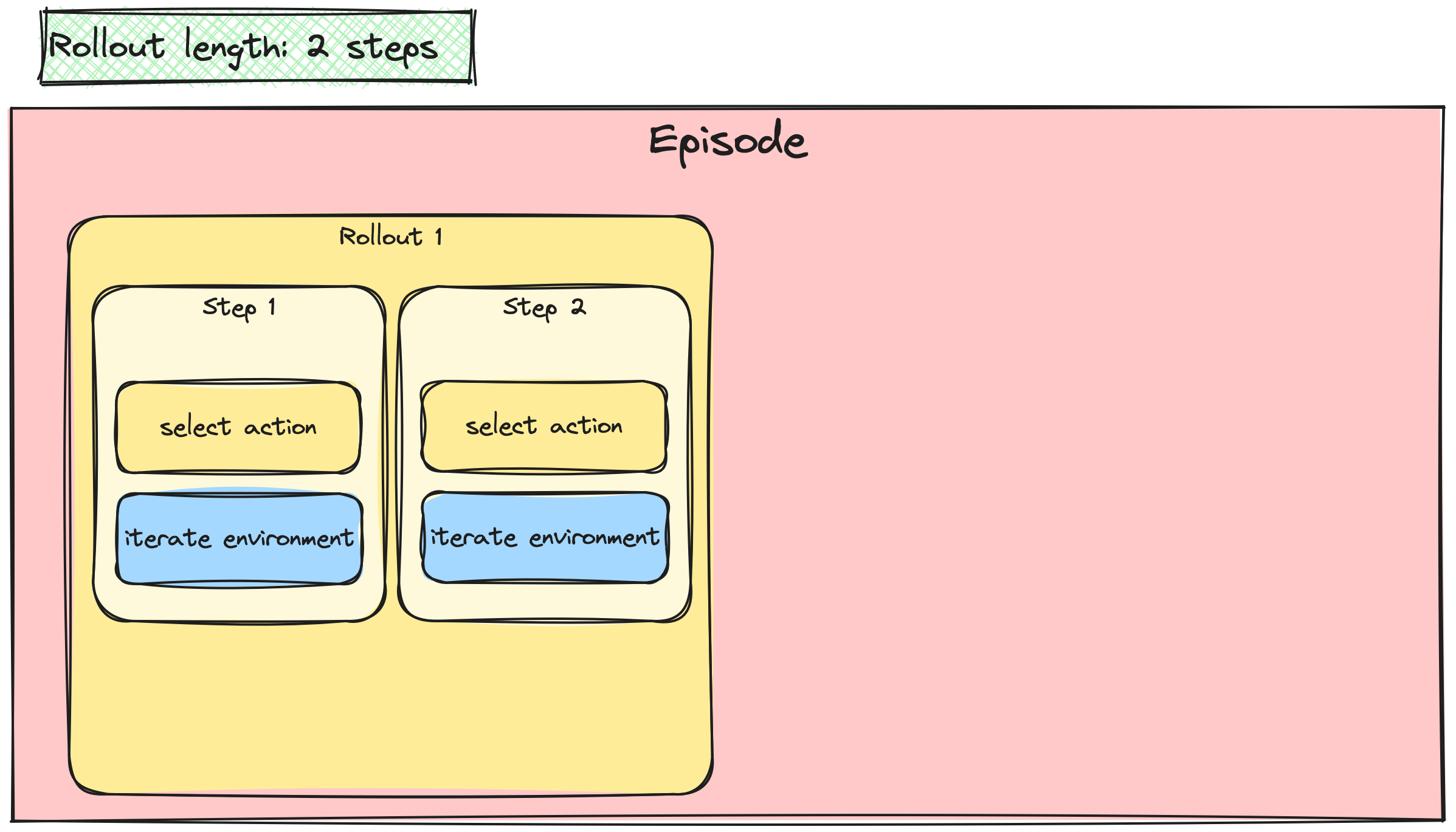
Batching the A2C / PPO updates
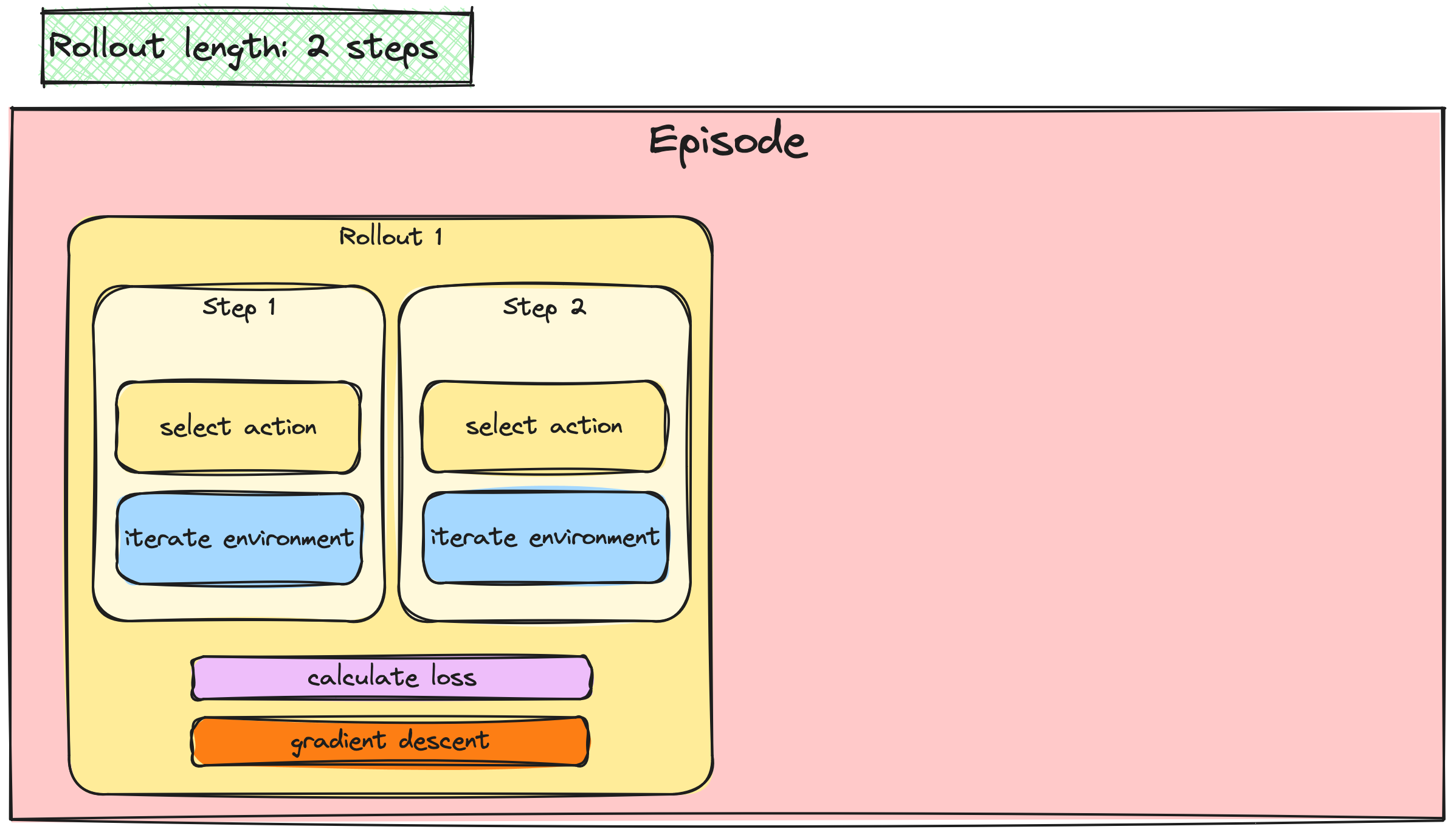
Batching the A2C / PPO updates
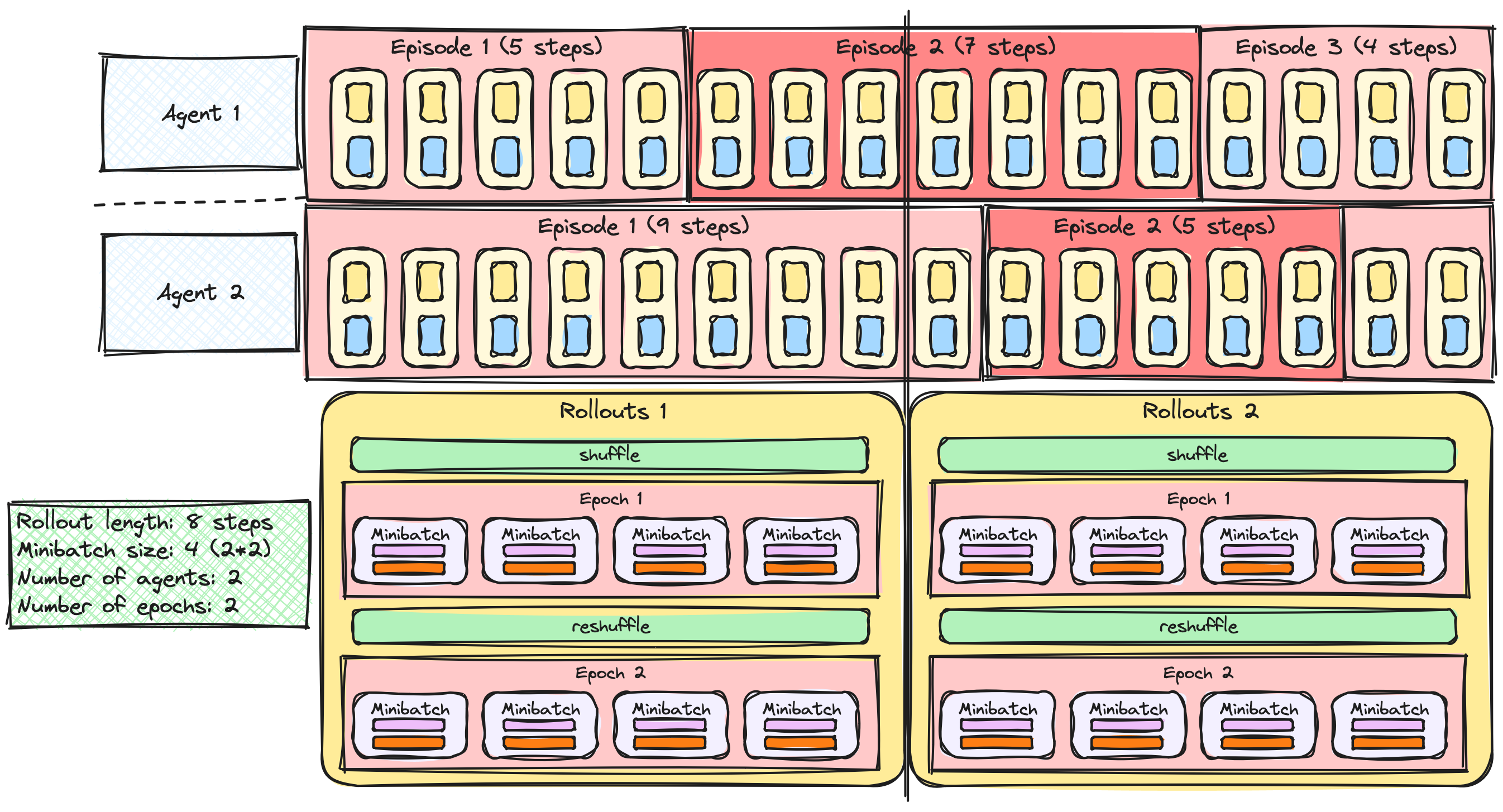
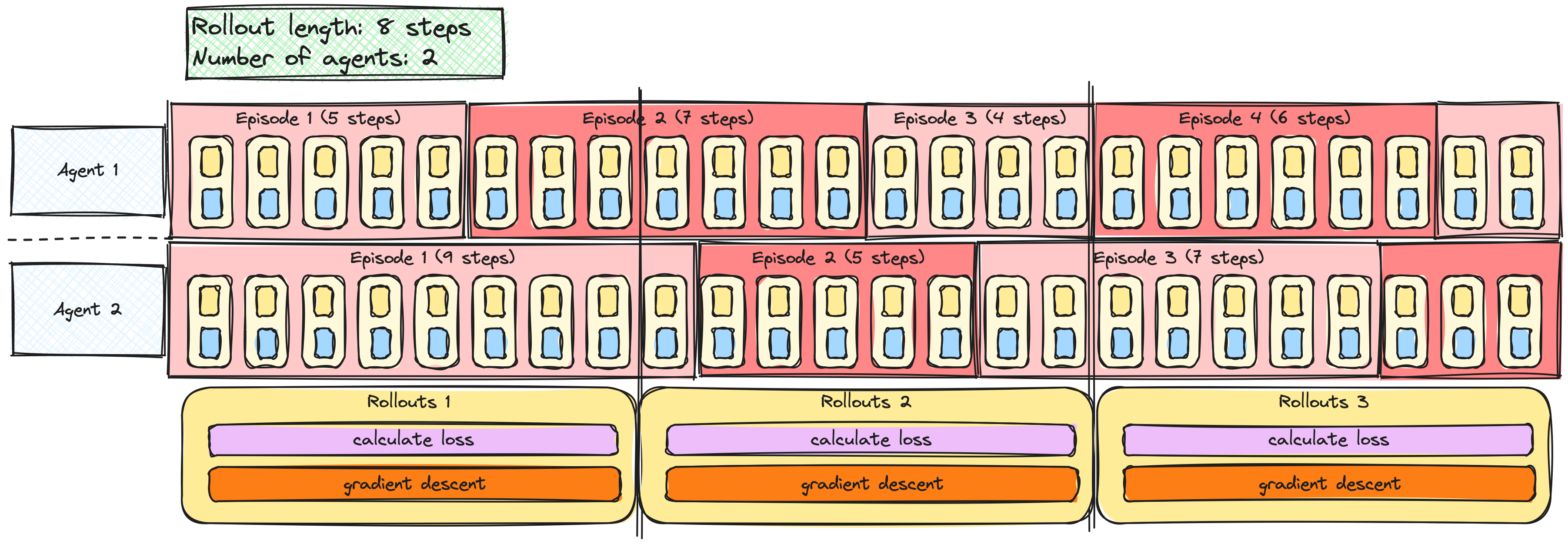
A2C / PPO with multiple agents
Rollouts and minibatches
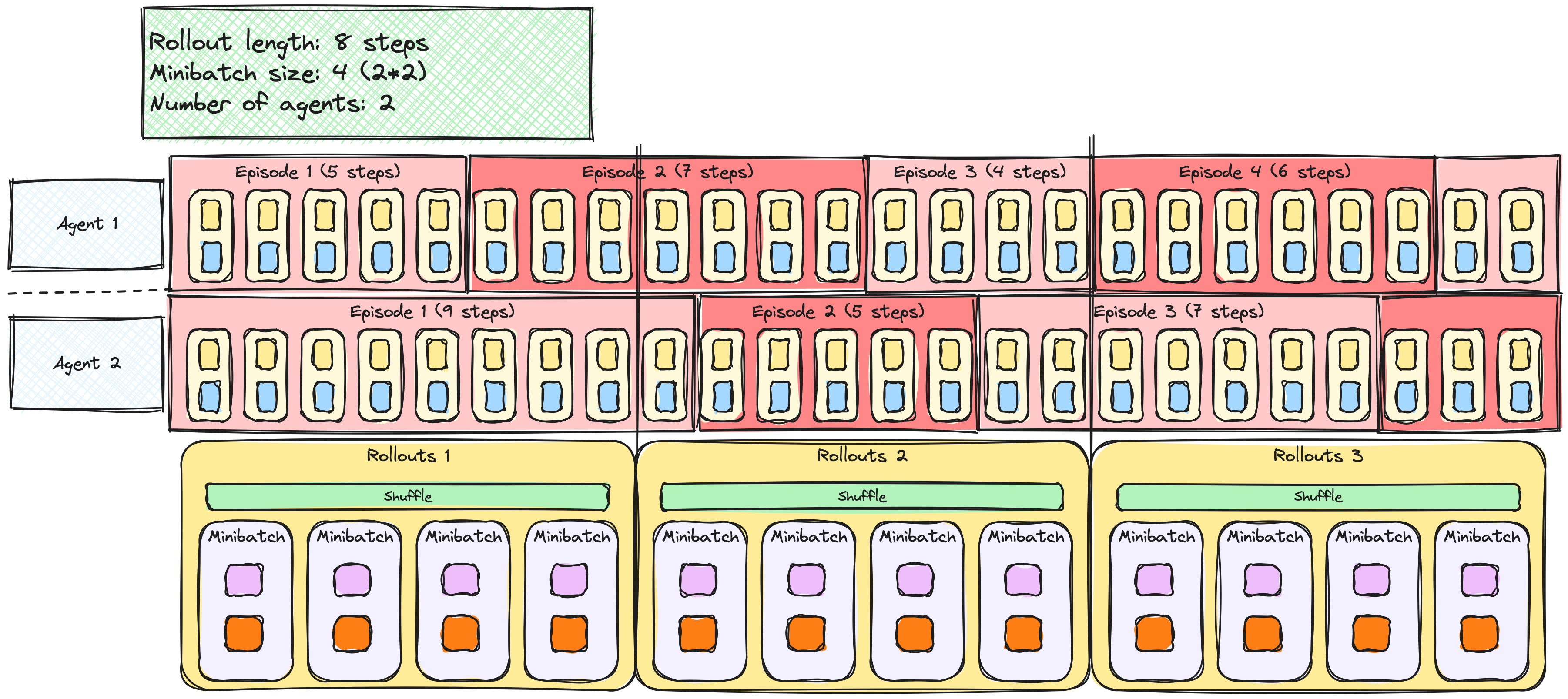
PPO with multiple epochs