Advantage Actor Critic
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Why actor critic?
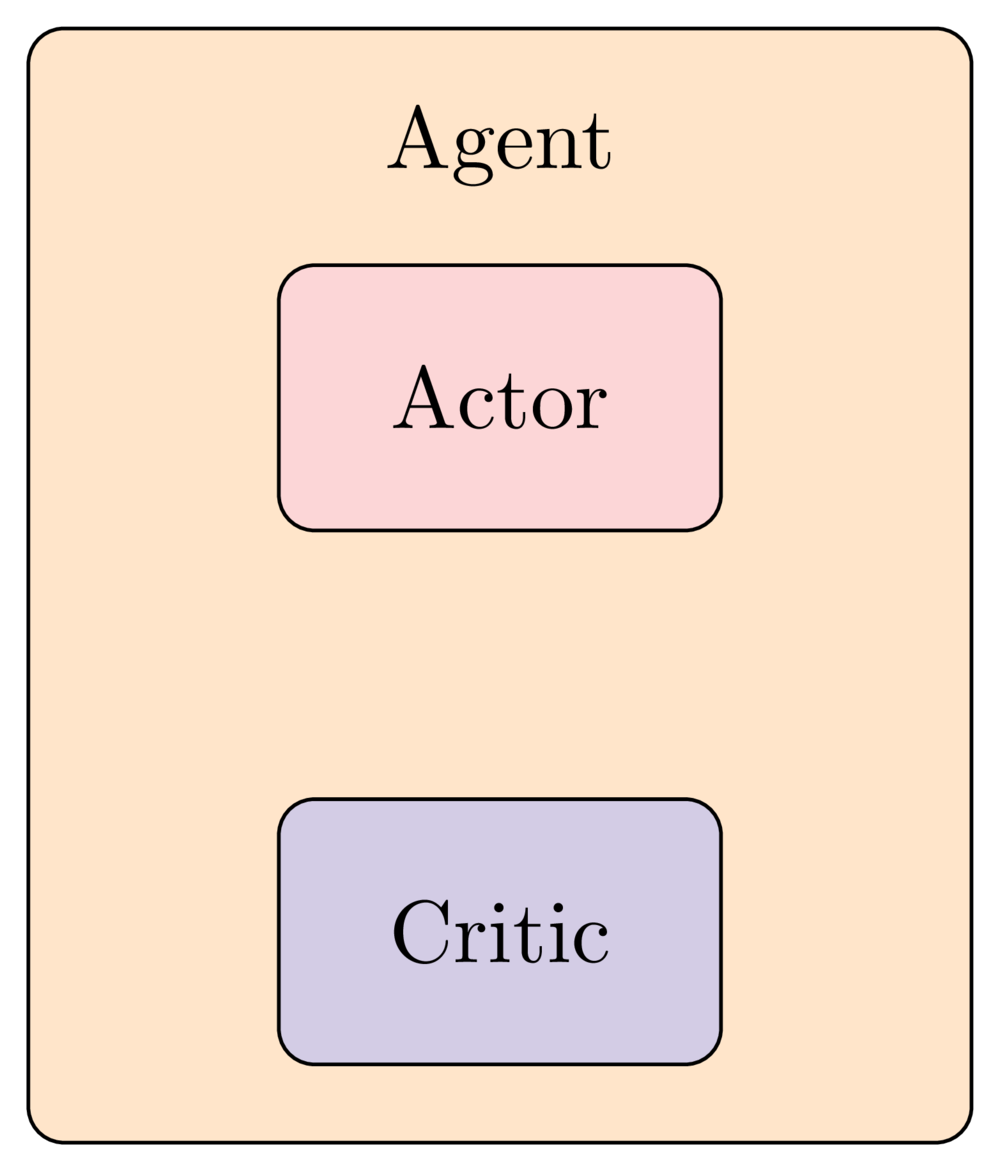
The intuition behind Actor Critic methods

The Critic network
- Critic approximates the state value function
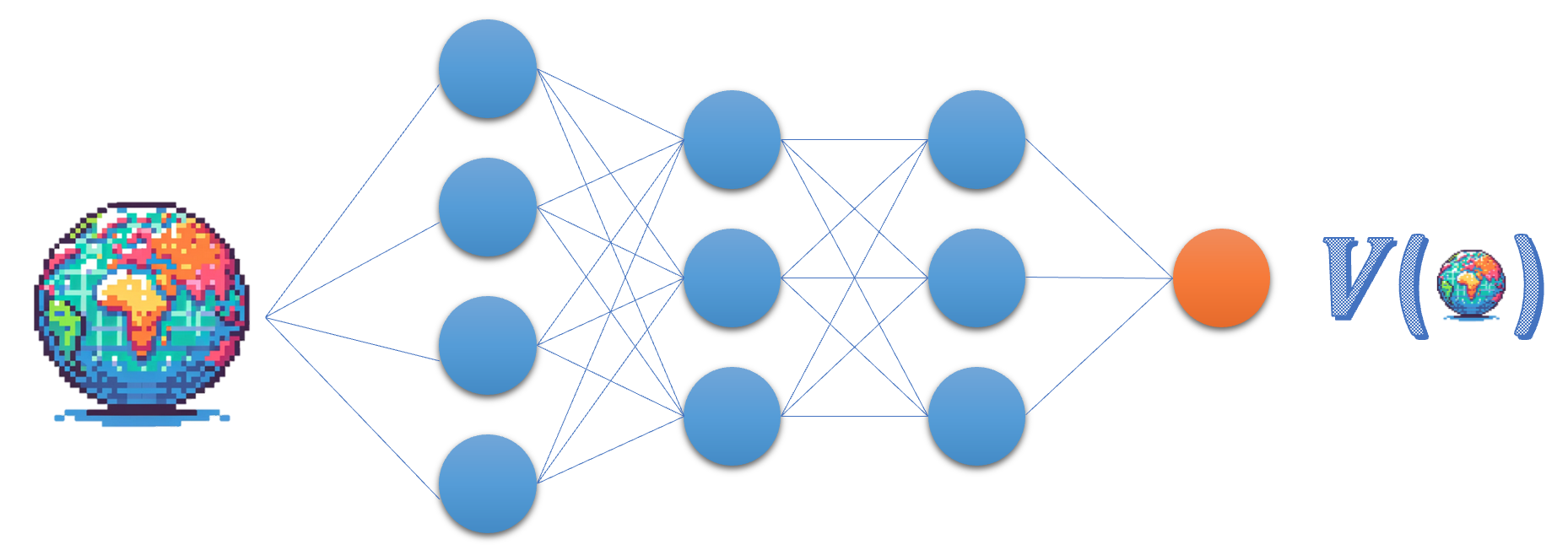
- Judges action $a_t$ based on the advantage or TD-error
The Actor Critic dynamics
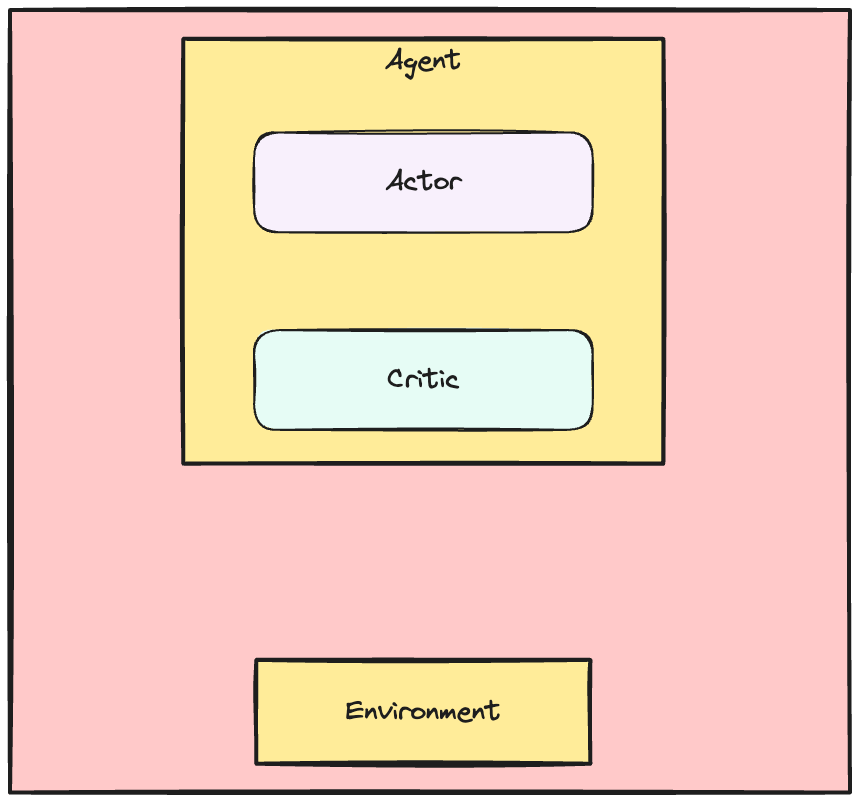
The Actor Critic dynamics
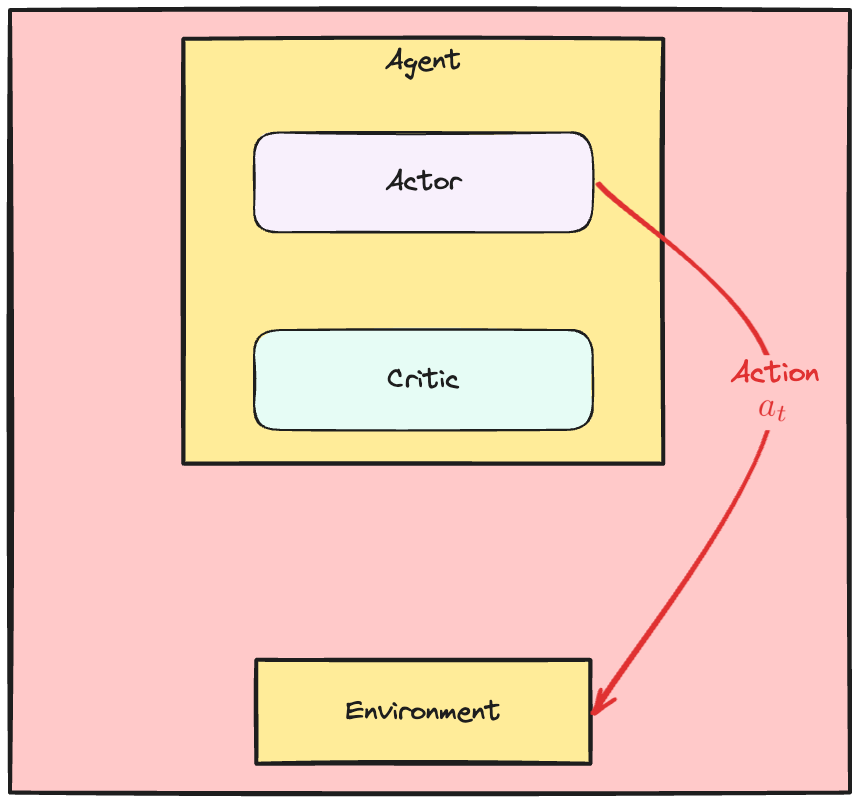
The Actor Critic dynamics
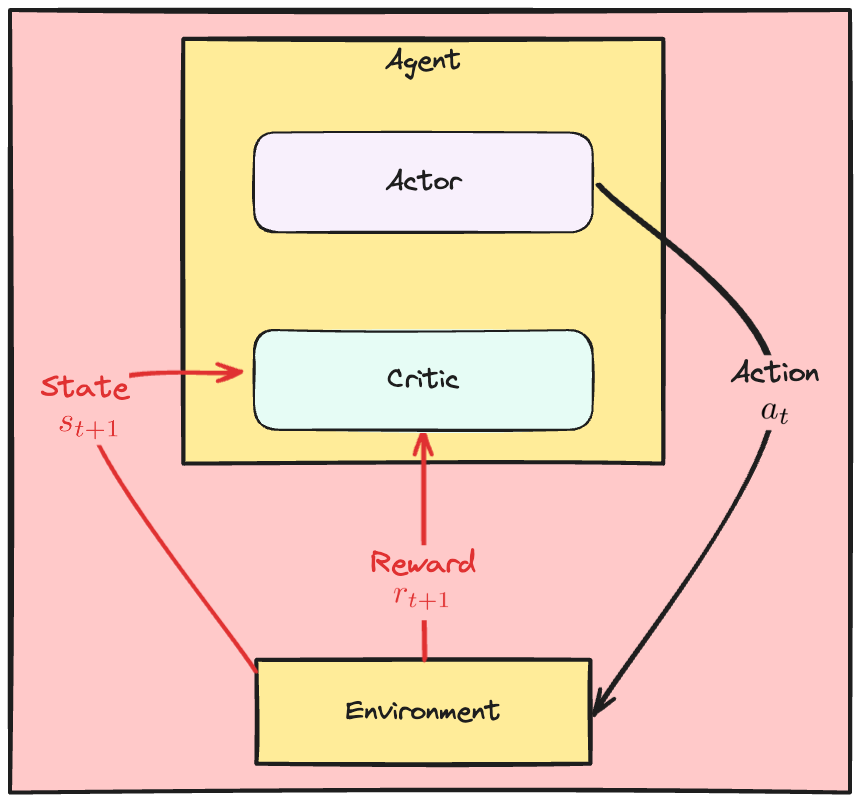
The Actor Critic dynamics
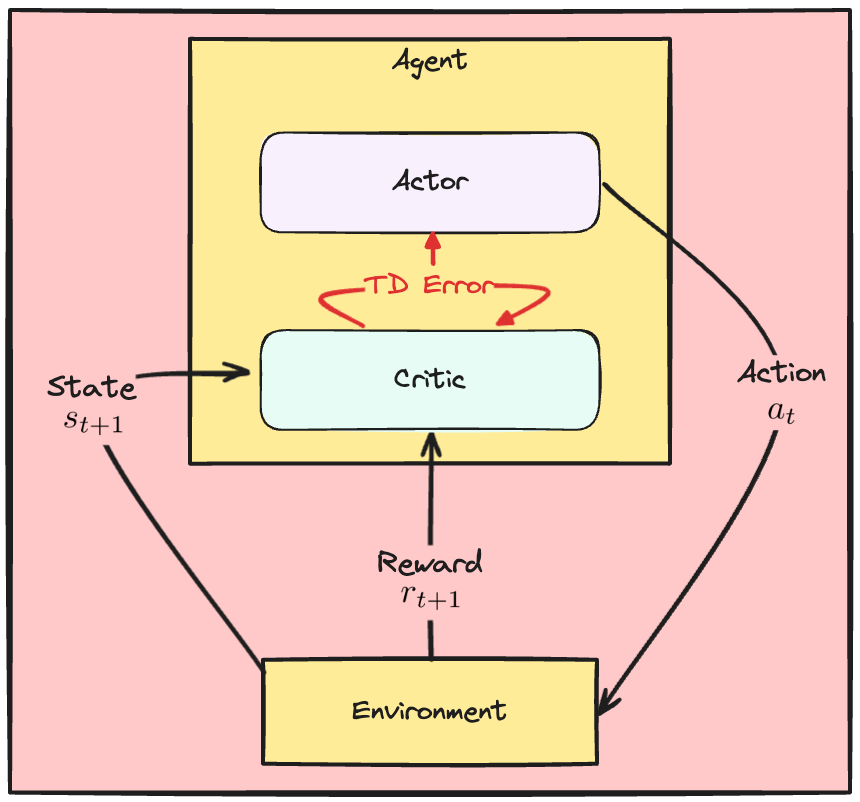
The Actor Critic dynamics
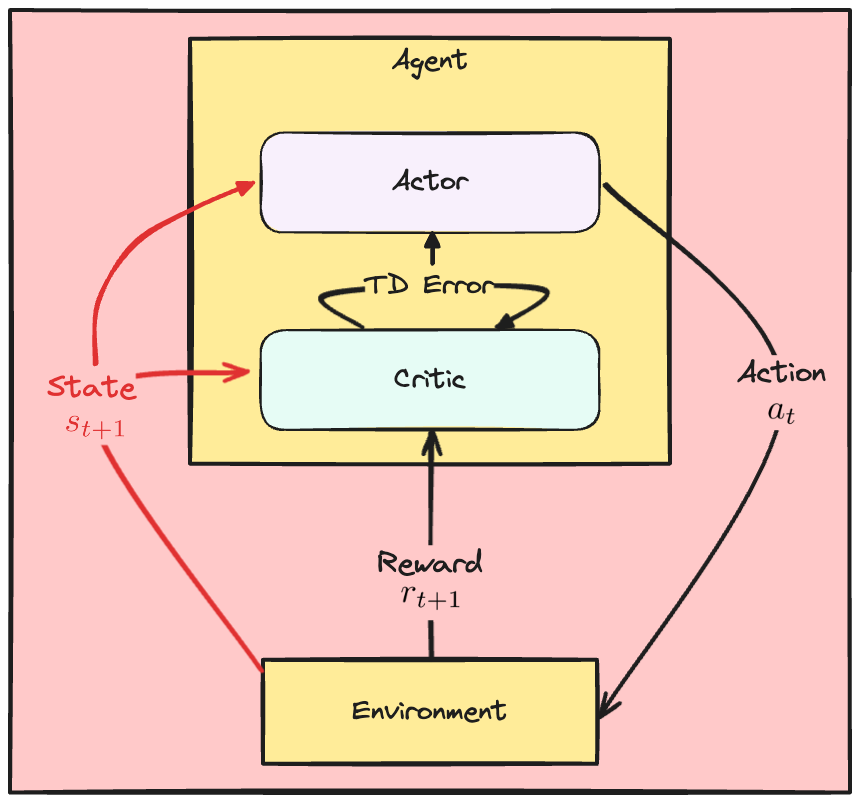
The A2C losses
Critic

- Critic loss: squared TD error
Actor

- TD error captures critic rating
- Increase probability of actions with positive TD error

