Policy gradient and REINFORCE
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Differences with DQN

Loss Calculation
Recall the policy gradient theorem:
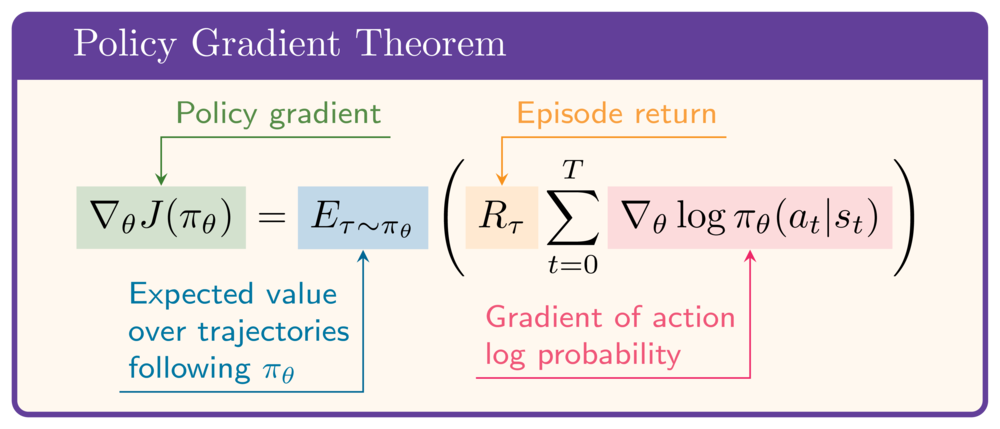

In Python:
- $R_{\tau}$ as
episode_return - Vector of $\log\pi_\theta(a_t|s_t)$ as
episode_log_probs
loss = -episode_return * episode_log_probs.sum()

