Convertir y analizar datos categóricos
Análisis exploratorio de datos en Python

George Boorman
Curriculum Manager, DataCamp
Previsualizar los datos
print(salaries.select_dtypes("object").head())
Designation Experience Employment_Status Employee_Location Company_Size
0 Data Scientist Mid FT DE L
1 Machine Learning Scientist Senior FT JP S
2 Big Data Engineer Senior FT GB M
3 Product Data Analyst Mid FT HN S
4 Machine Learning Engineer Senior FT US L
Puestos
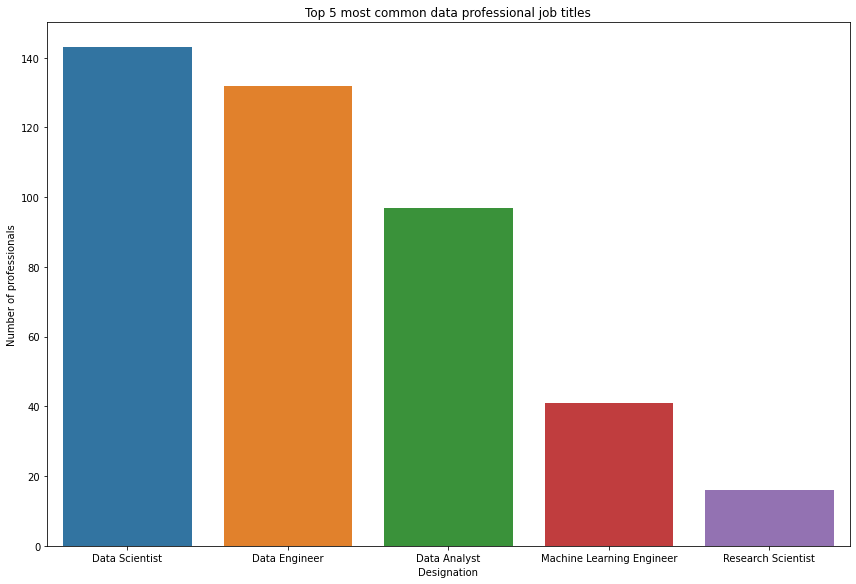
print(salaries["Designation"].value_counts())
Data Scientist 143
Data Engineer 132
Data Analyst 97
Machine Learning Engineer 41
Research Scientist 16
Data Science Manager 12
Data Architect 11
Big Data Engineer 8
Machine Learning Scientist 8
...
Puestos
print(salaries["Designation"].nunique())
50
Puestos
Obtener valor de las categorías
El formato actual limita nuestra capacidad para generar conocimientos.
pandas.Series.str.contains()- Buscar una cadena específica o varias cadenas en una columna
salaries["Designation"].str.contains("Scientist")
0 True
1 True
2 False
3 False
...
604 False
605 False
606 True
Name: Designation, Length: 607, dtype: bool
Buscar varias frases en cadenas
- Palabras de interés: Machine learning o IA
salaries["Designation"].str.contains("Machine Learning|AI")
0 False
1 True
2 False
3 False
...
604 False
605 False
606 True
Name: Designation, Length: 607, dtype: bool
Buscar varias frases en cadenas
- Palabras de interés: Cualquiera que comience con Data
salaries["Designation"].str.contains("^Data")
0 True
1 False
2 False
3 False
...
604 True
605 True
606 False
Name: Designation, Length: 607, dtype: bool
Buscar varias frases en cadenas
job_categories = ["Data Science", "Data Analytics",
"Data Engineering", "Machine Learning",
"Managerial", "Consultant"]
Buscar varias frases en cadenas
data_science = "Data Scientist|NLP"data_analyst = "Analyst|Analytics"data_engineer = "Data Engineer|ETL|Architect|Infrastructure"ml_engineer = "Machine Learning|ML|Big Data|AI"manager = "Manager|Head|Director|Lead|Principal|Staff"consultant = "Consultant|Freelance"
Buscar varias frases en cadenas
conditions = [ (salaries["Designation"].str.contains(data_science)),(salaries["Designation"].str.contains(data_analyst)),(salaries["Designation"].str.contains(data_engineer)),(salaries["Designation"].str.contains(ml_engineer)),(salaries["Designation"].str.contains(manager)),(salaries["Designation"].str.contains(consultant)) ]
Crear la columna categórica
salaries["Job_Category"] =
Crear la columna categórica
salaries["Job_Category"] = np.select(conditions,
Crear la columna categórica
salaries["Job_Category"] = np.select(conditions,
job_categories,
Crear la columna categórica
salaries["Job_Category"] = np.select(conditions,
job_categories,
default="Other")
Previsualizar las categorías de trabajo
print(salaries[["Designation", "Job_Category"]].head())
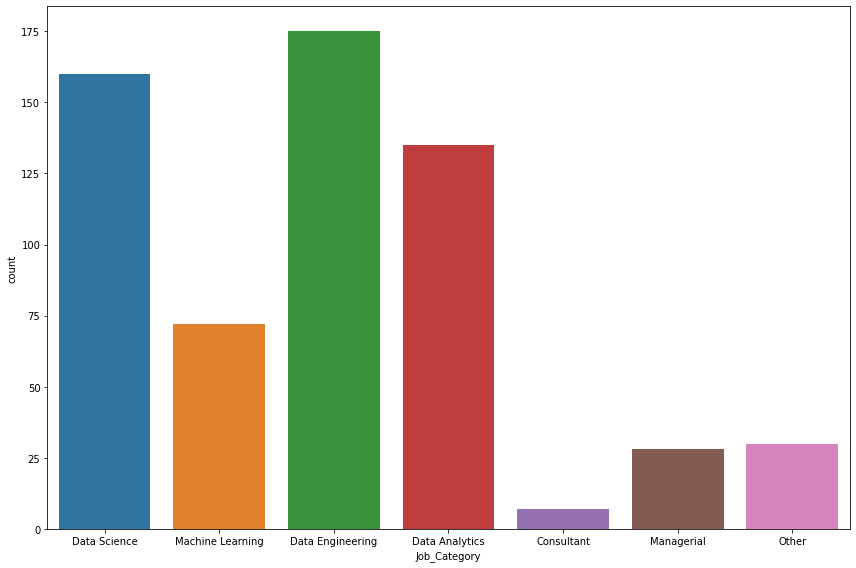
Designation Job_Category
0 Data Scientist Data Science
1 Machine Learning Scientist Machine Learning
2 Big Data Engineer Data Engineering
3 Product Data Analyst Data Analytics
4 Machine Learning Engineer Machine Learning
Visualizar la frecuencia de las categorías laborales
sns.countplot(data=salaries, x="Job_Category")plt.show()
¡Vamos a practicar!
Análisis exploratorio de datos en Python

