Creating features over time
Machine Learning for Time Series Data in Python

Chris Holdgraf
Fellow, Berkeley Institute for Data Science
Extracting features with windows
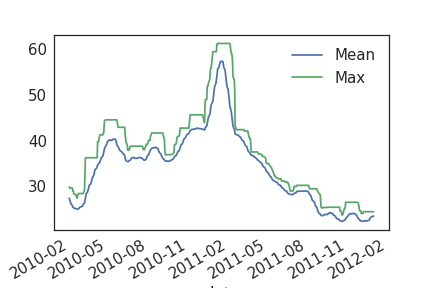
Check the properties of your features!
Machine Learning for Time Series Data in Python
Chris Holdgraf
Fellow, Berkeley Institute for Data Science

