Pipeline
Machine Learning with PySpark

Andrew Collier
Data Scientist, Fathom Data
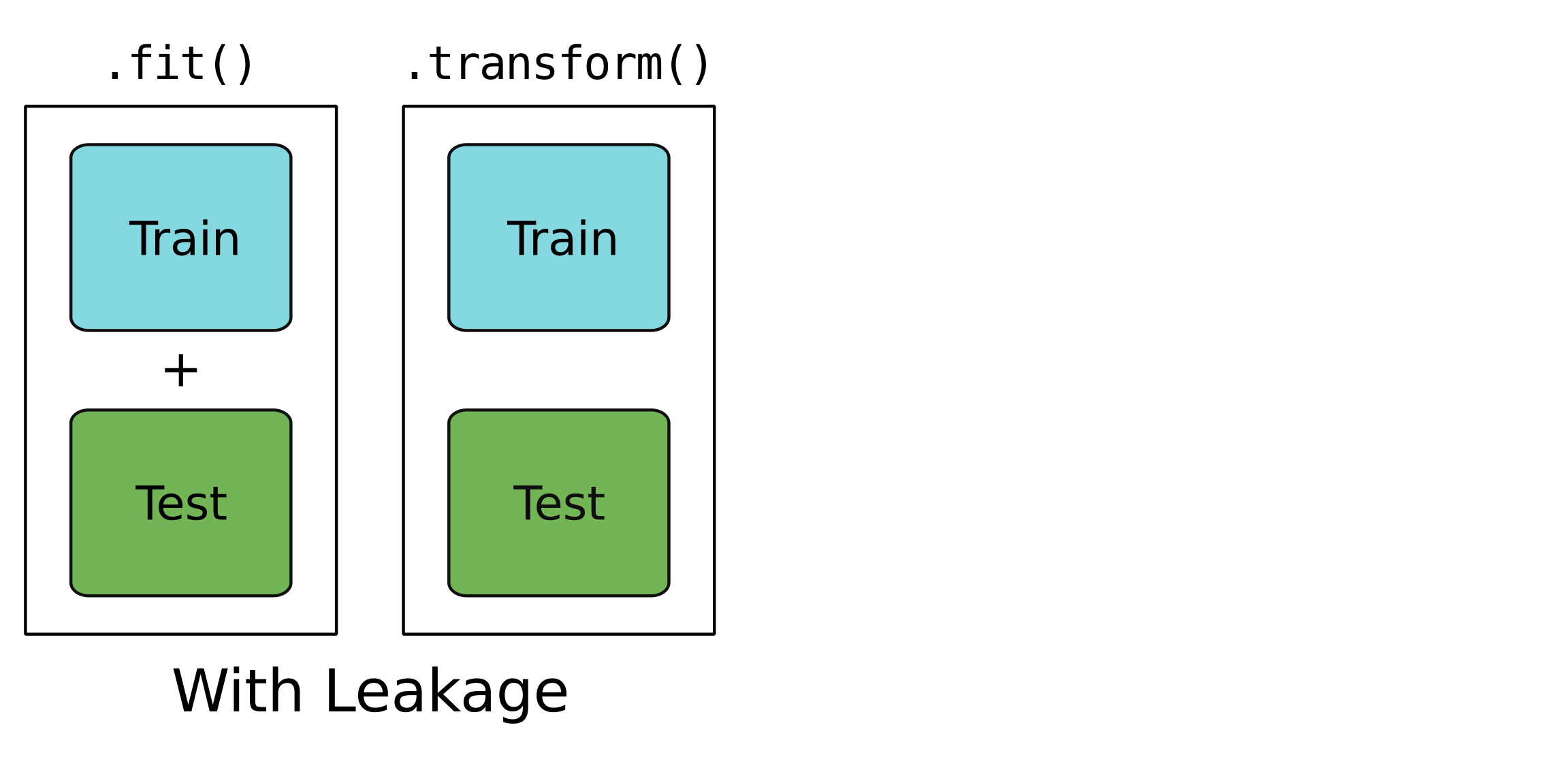
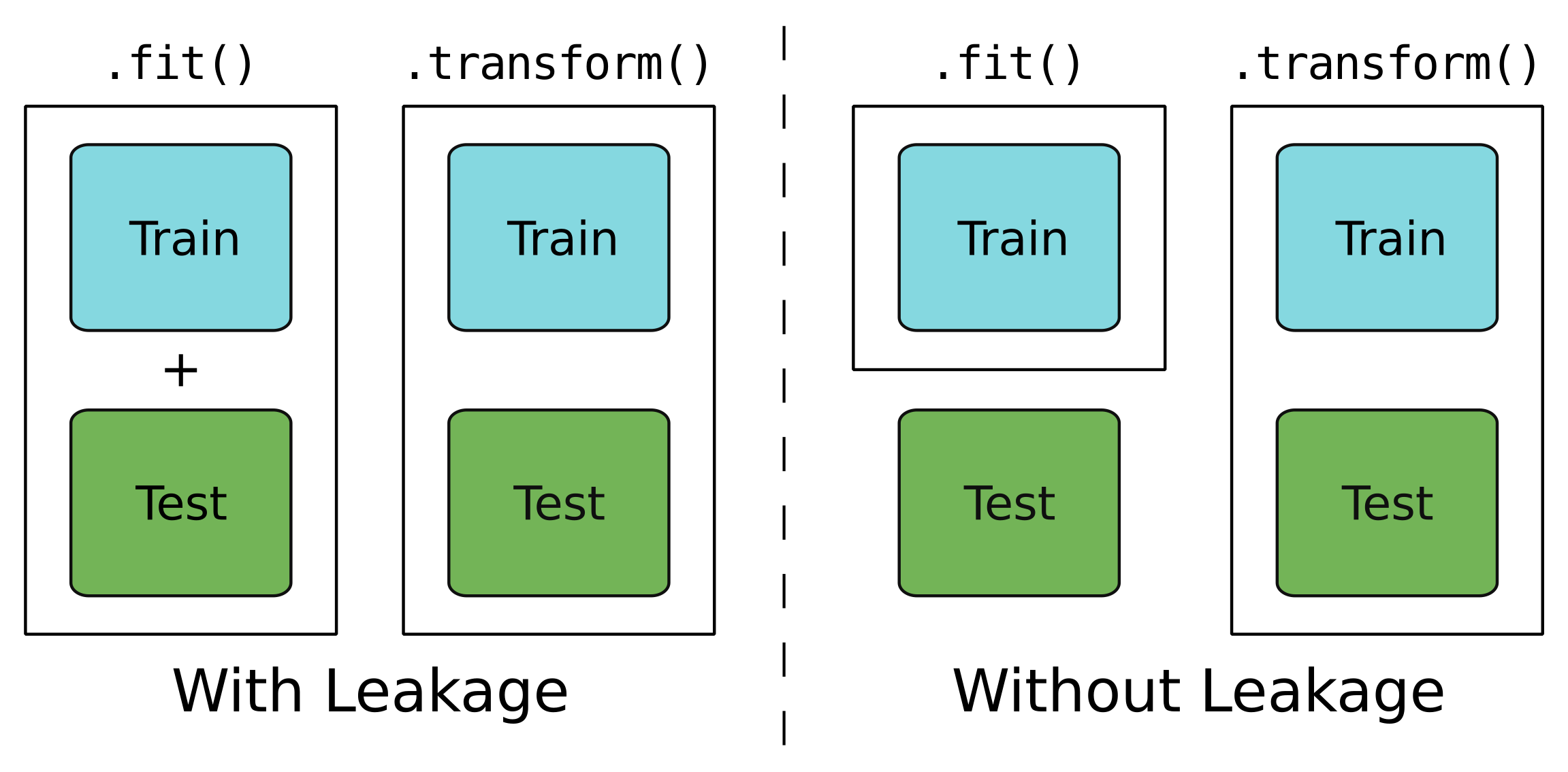
Leakage?

Only for training data.

For testing and training data.
A leaky model
A watertight model
Pipeline
A pipeline consists of a series of operations.

You could apply each operation individually... or you could just apply the pipeline!

