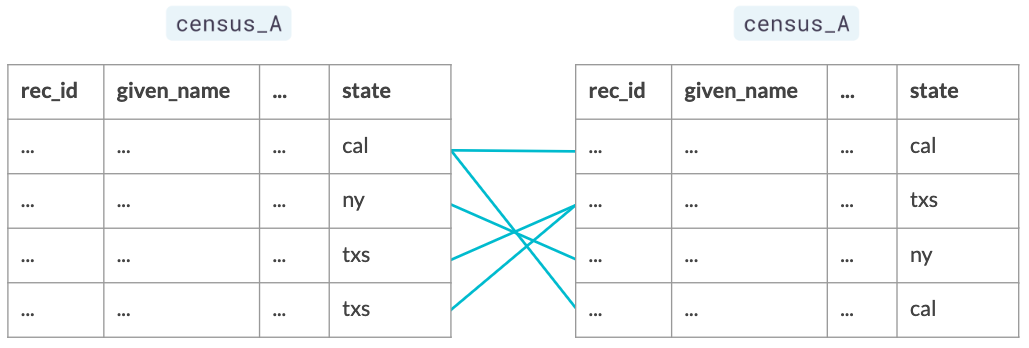
Generar pares
Limpieza de datos en Python

Adel Nehme
VP of AI Curriculum, DataCamp
Motivación
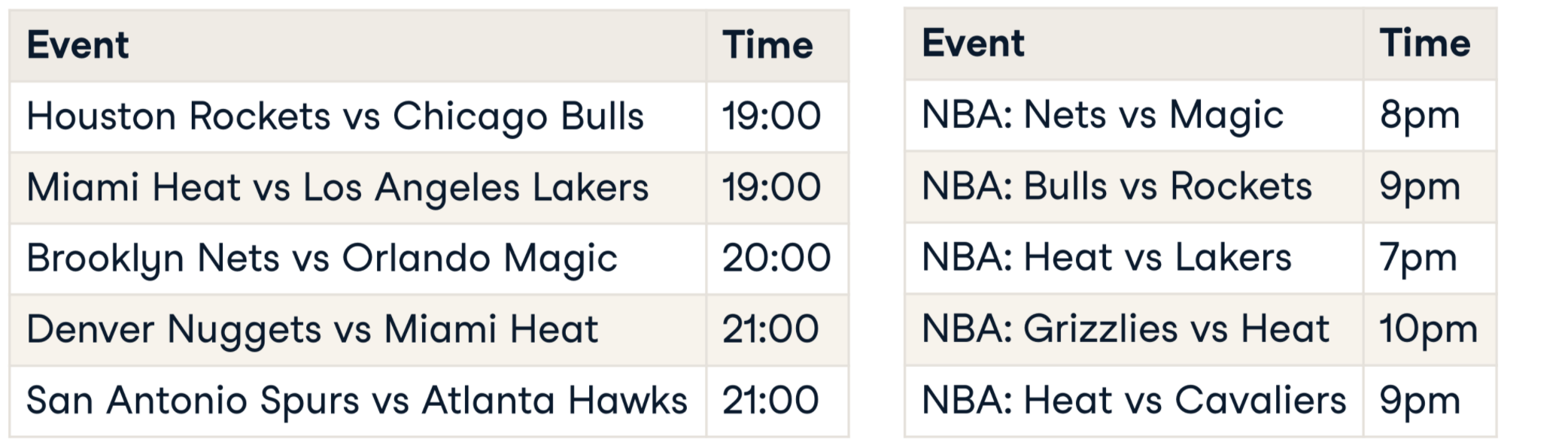
Vinculación de registros
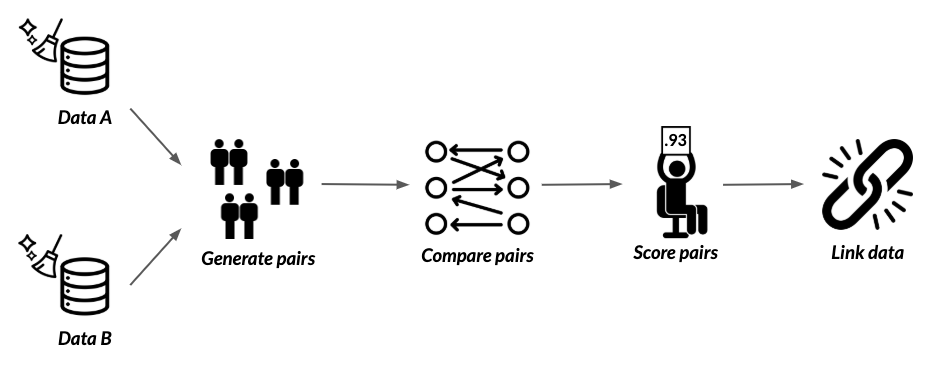
El paquete « recordlinkage »
Generar pares
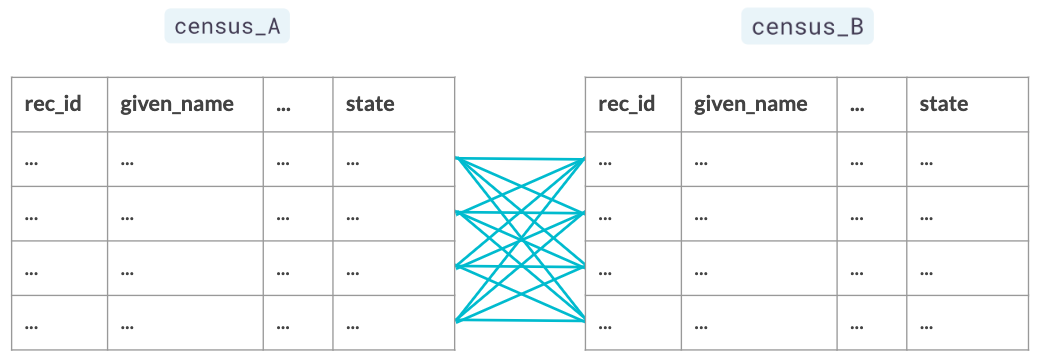
Generar pares
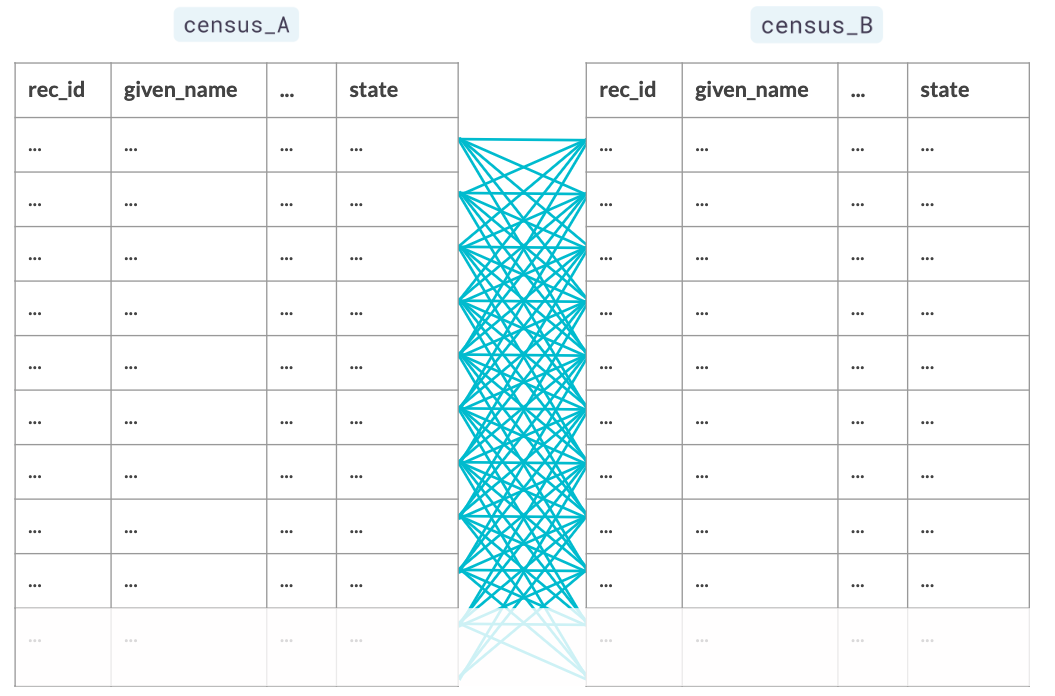
Bloqueo
Limpieza de datos en Python
Adel Nehme
VP of AI Curriculum, DataCamp
El paquete « recordlinkage »

