Comparar cadenas
Limpieza de datos en Python

Adel Nehme
VP of AI Curriculum, DataCamp
Distancia mínima de edición
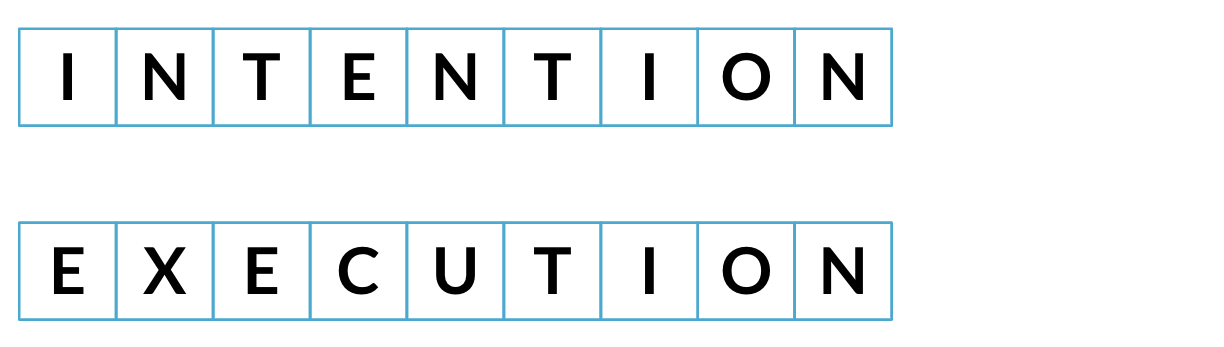
Menor cantidad posible de pasos necesarios para pasar de una cadena a otra.
Distancia mínima de edición
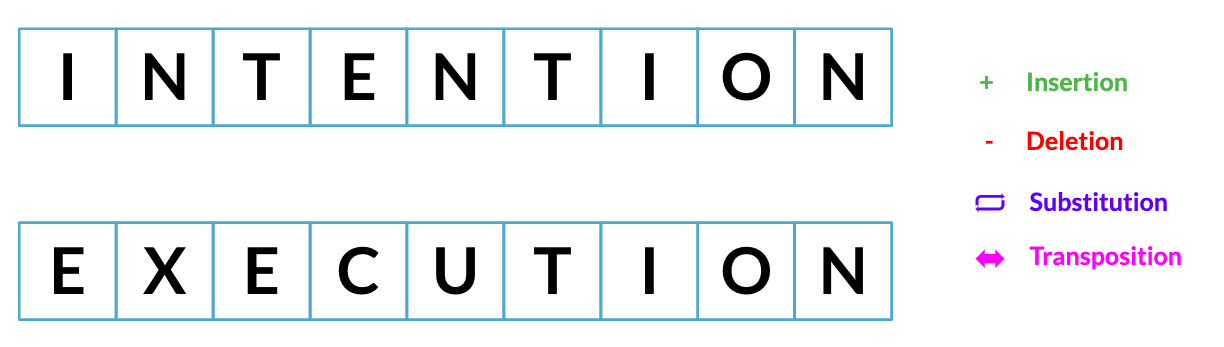
Menor cantidad posible de pasos necesarios para pasar de una cadena a otra.
Distancia mínima de edición

Distancia mínima de edición
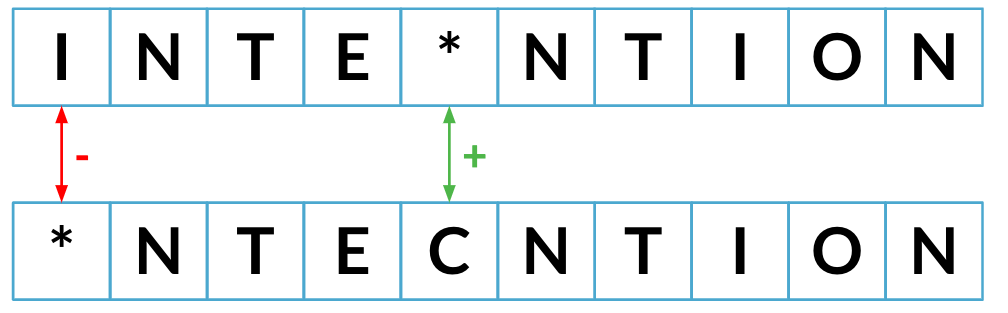
Distancia mínima de edición hasta ahora: 2
Distancia mínima de edición
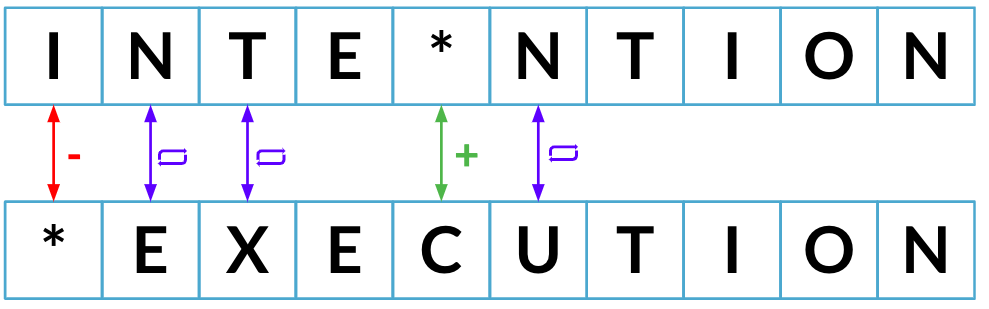
Distancia mínima de edición 5**
Distancia mínima de edición


