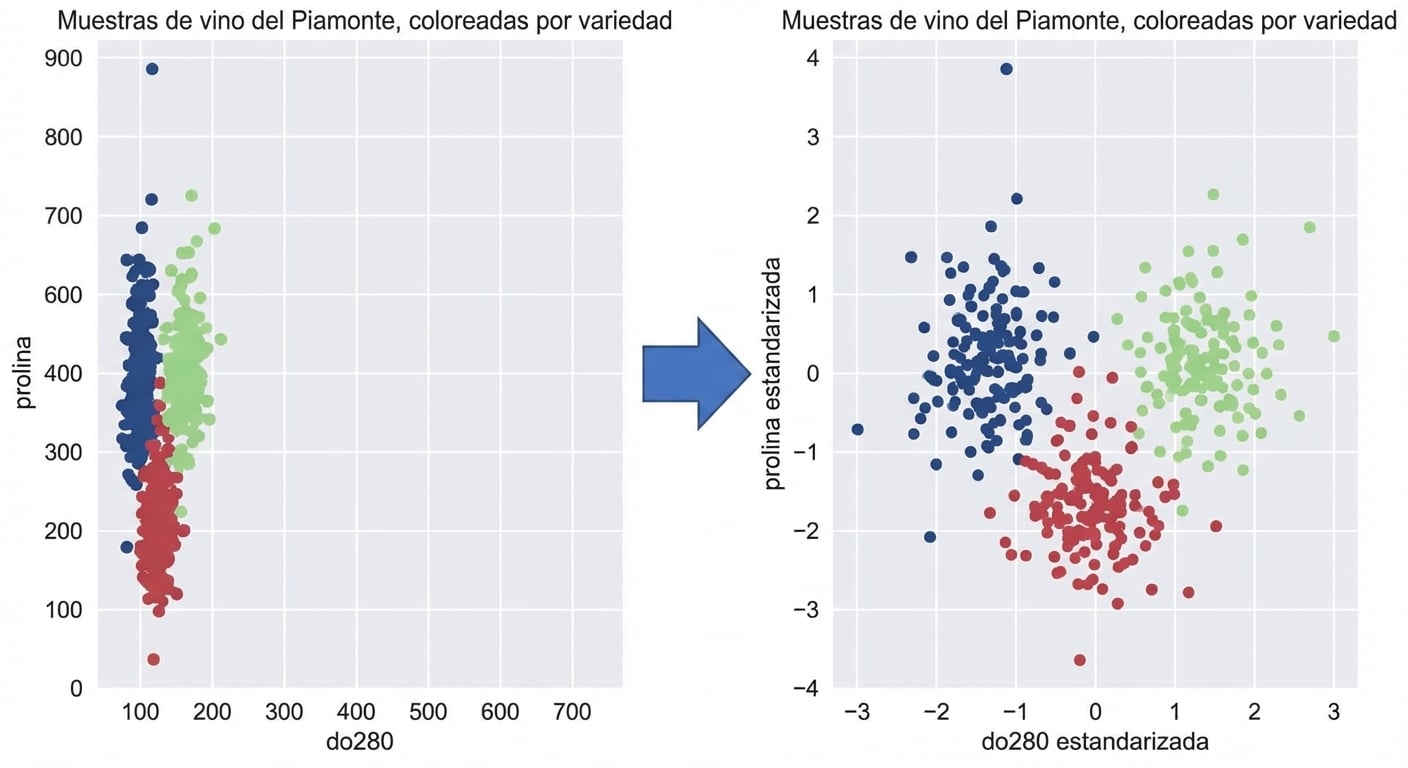
Transformar características para mejores clústeres
Aprendizaje no supervisado en Python

Benjamin Wilson
Director of Research at lateral.io
Varianza de características
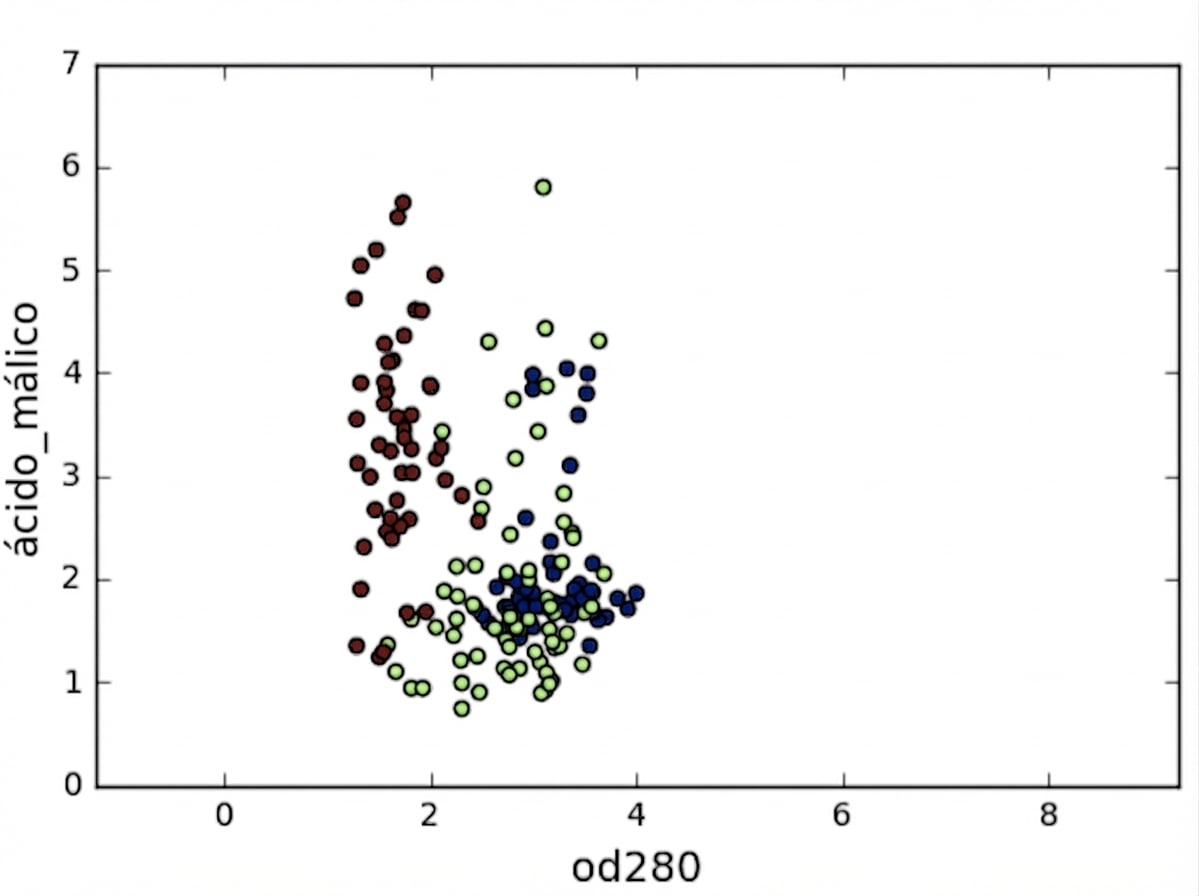
Varianza de características
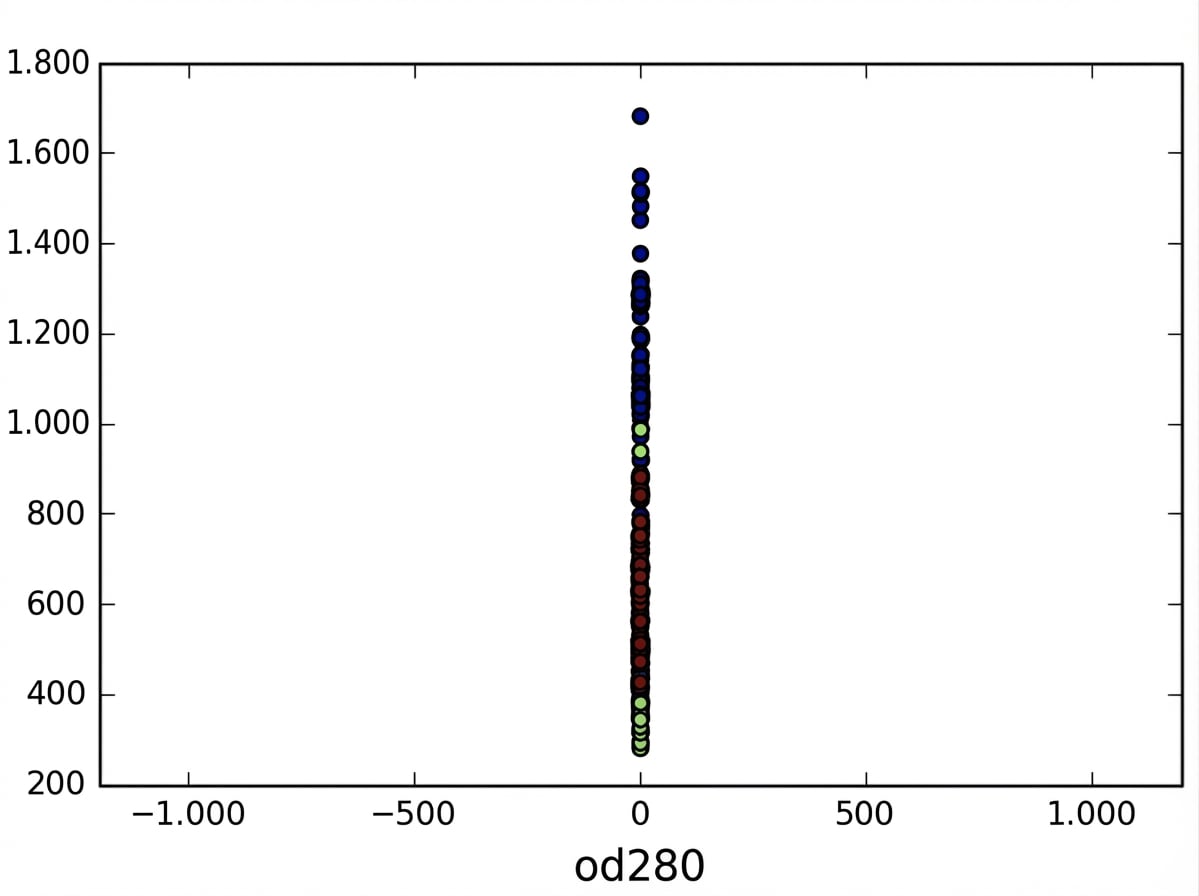
StandardScaler
En k-means: mayor varianza ⇒ mayor influencia
StandardScalertransforma cada característica a media 0 y varianza 1Se dice que las características quedan «estandarizadas»