Crear sistemas de recomendación con NMF
Aprendizaje no supervisado en Python

Benjamin Wilson
Director of Research at lateral.io
Versiones de artículos
- Distintas versiones del mismo documento tienen las mismas proporciones de temas
- ... pero los valores exactos de las features pueden variar

Versiones de artículos
- Distintas versiones del mismo documento tienen las mismas proporciones de temas
- ... pero los valores exactos de las features pueden variar
- P. ej., si una versión usa muchas palabras sin sentido

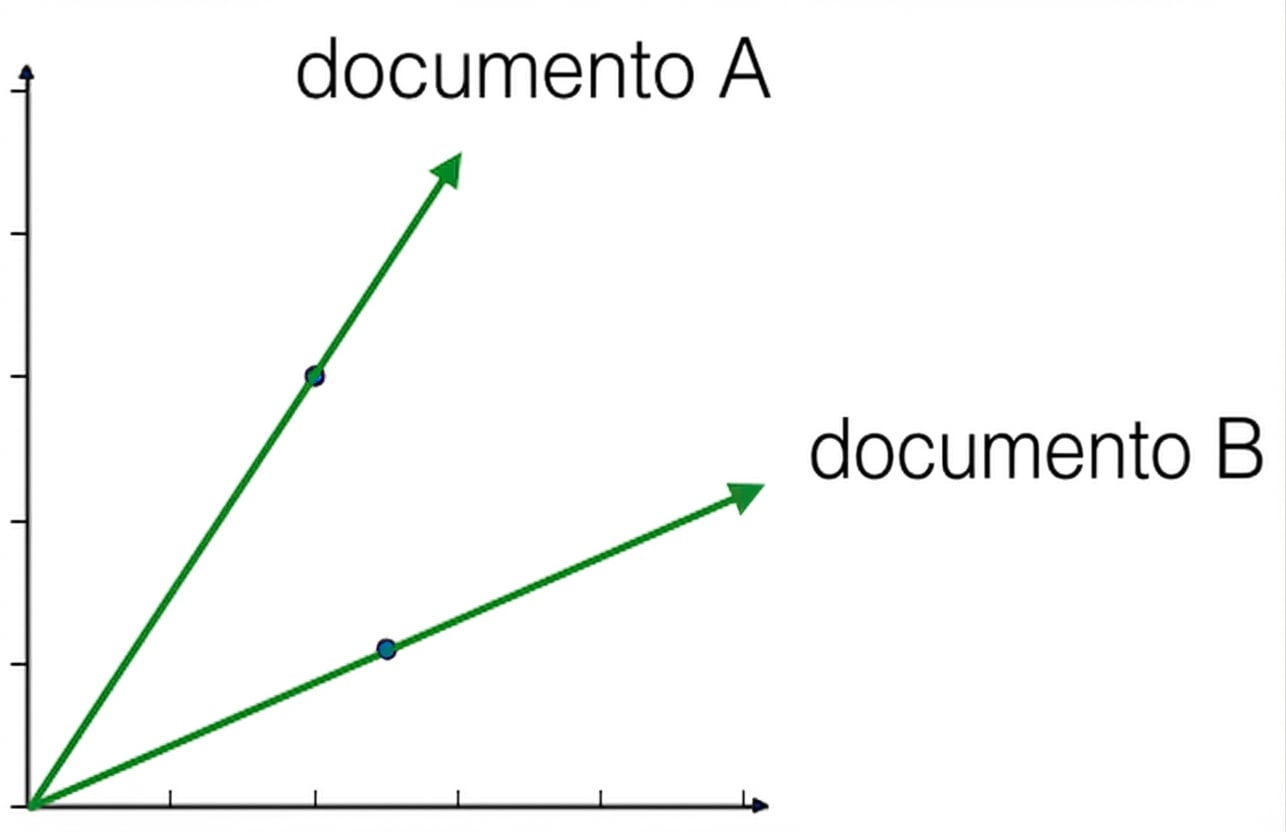
Versiones de artículos
- Distintas versiones del mismo documento tienen las mismas proporciones de temas
- ... pero los valores exactos de las features pueden variar
- P. ej., si una versión usa muchas palabras sin sentido
- Pero todas las versiones caen en la misma recta desde el origen

Similitud coseno
- Usa el ángulo entre las rectas
- Valores más altos = más similitud
- Máximo 1 cuando el ángulo es 0°