Mejorar el rendimiento del modelo
Introducción al aprendizaje profundo con PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
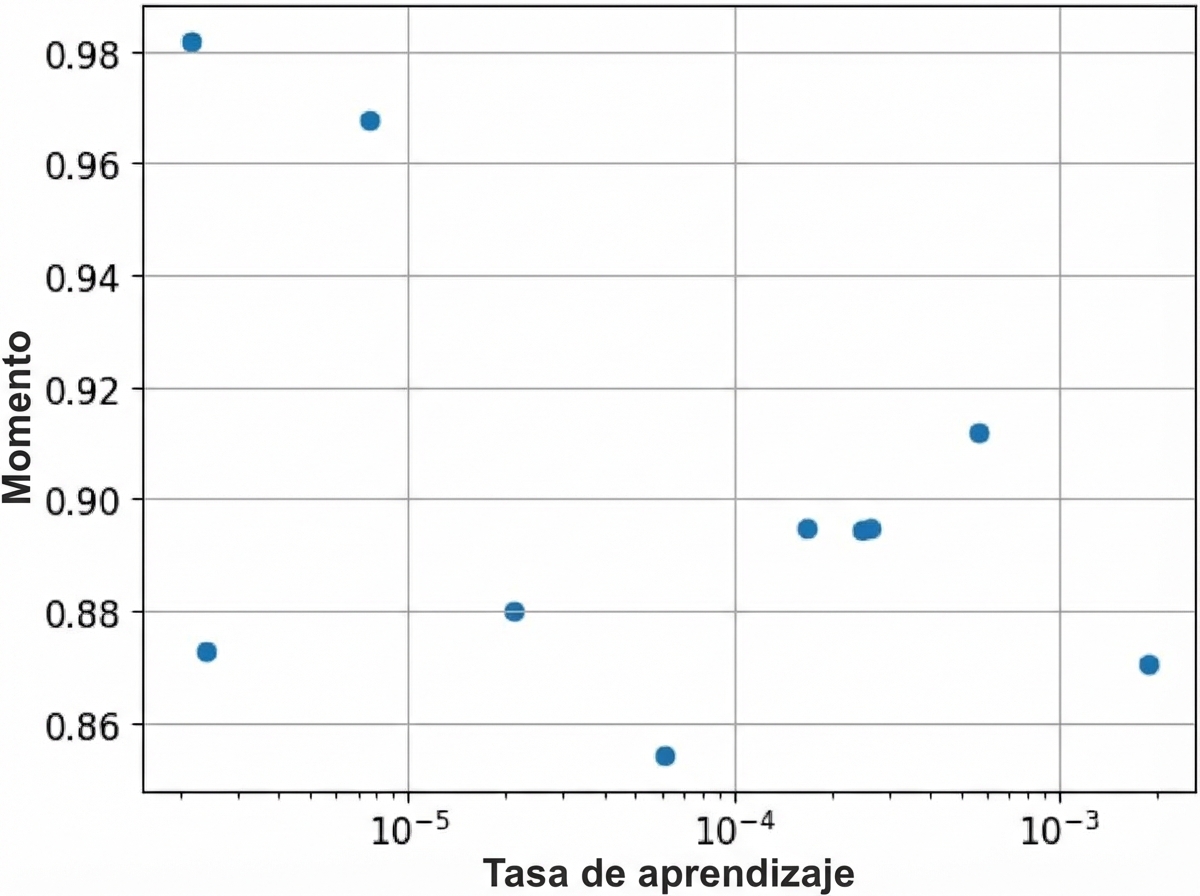
Pasos para maximizar el rendimiento



Paso 2: reducir el sobreajuste
Paso 2: reducir el sobreajuste
$$
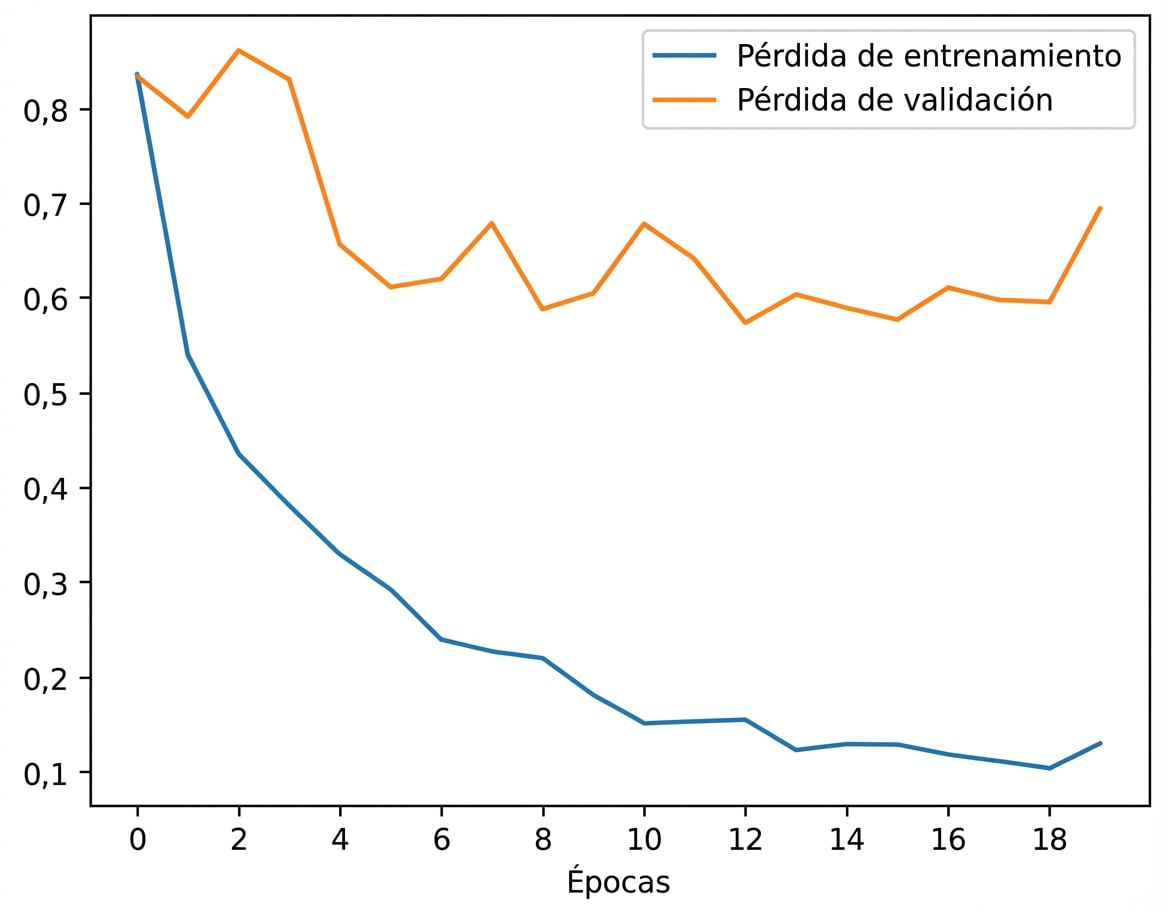
El modelo original se ajusta en exceso a los datos de entrenamiento
$$
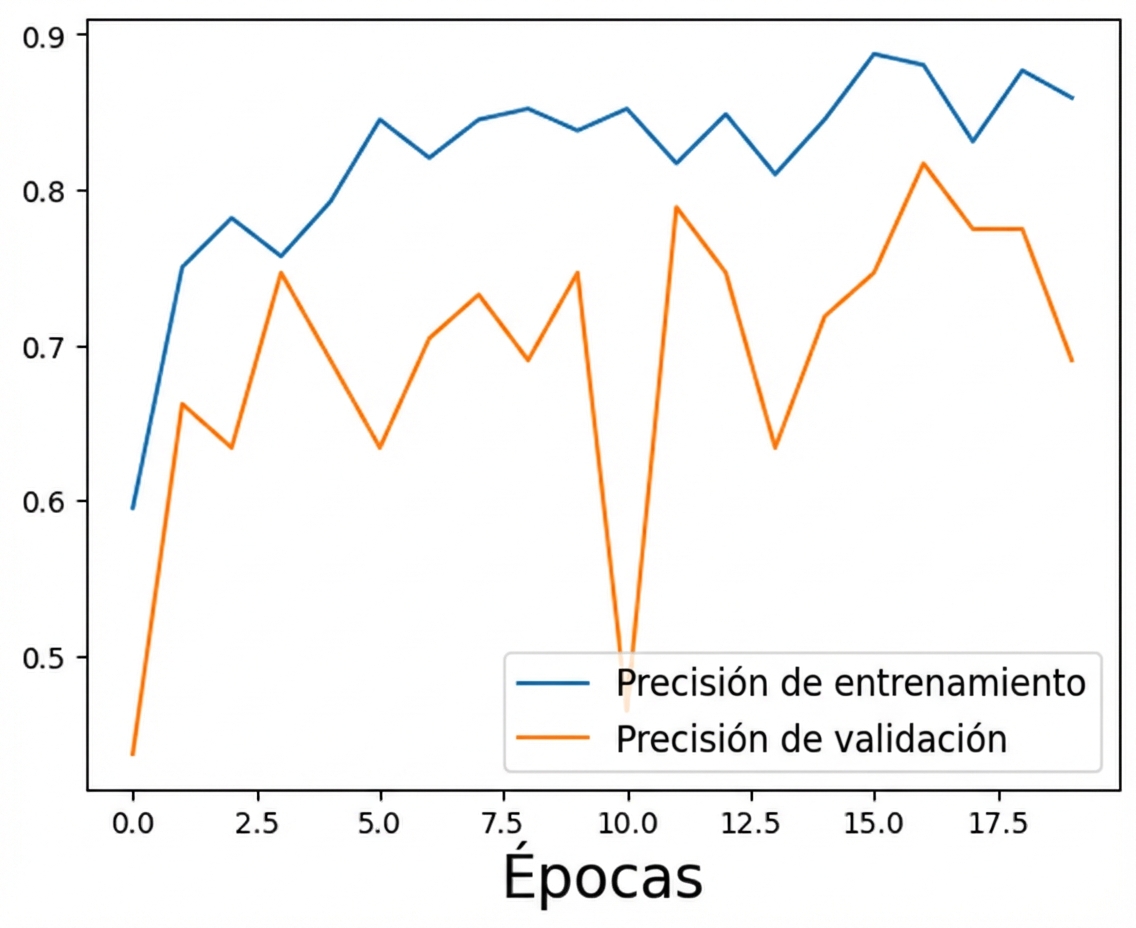
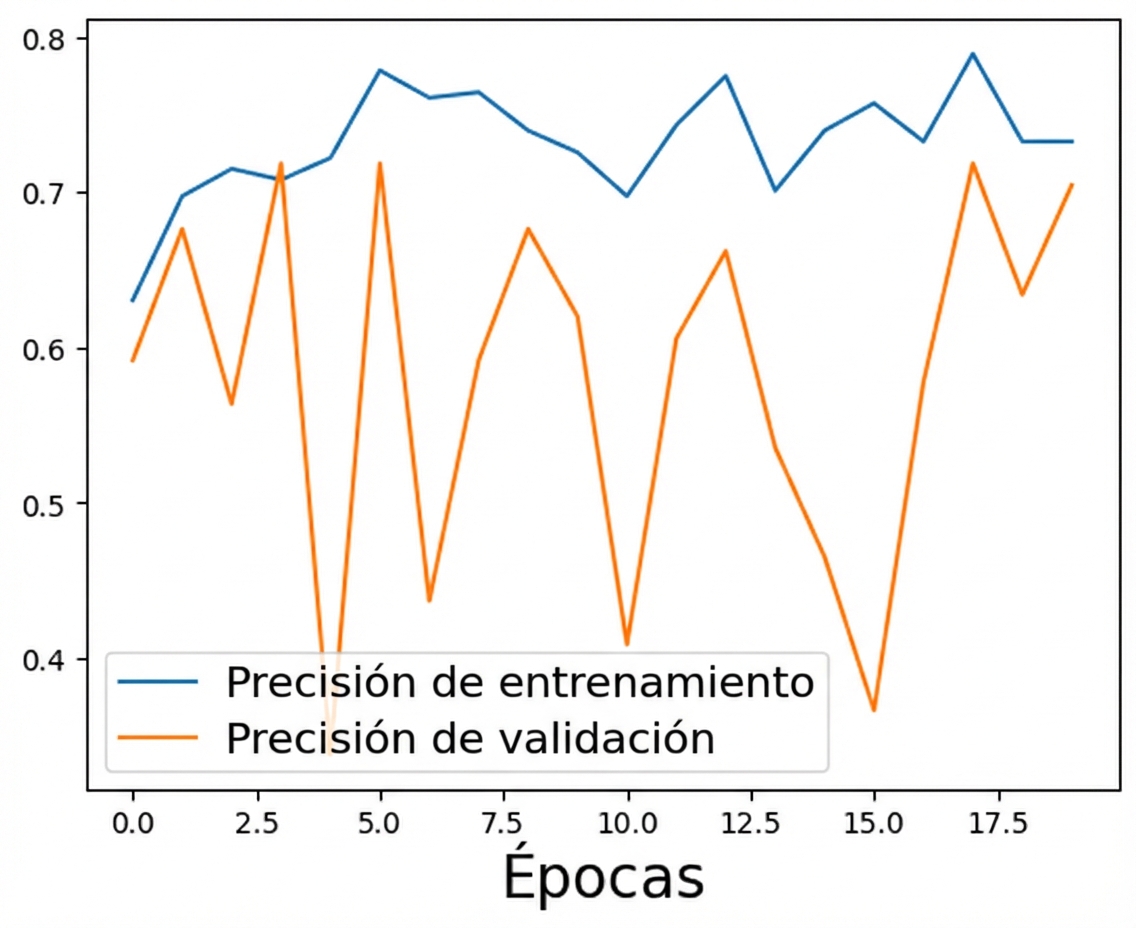
Modelo actualizado con demasiada regularización
Paso 3: afinar los hiperparámetros
- Búsqueda en la parrilla
for factor in range(2, 6):
lr = 10 ** -factor
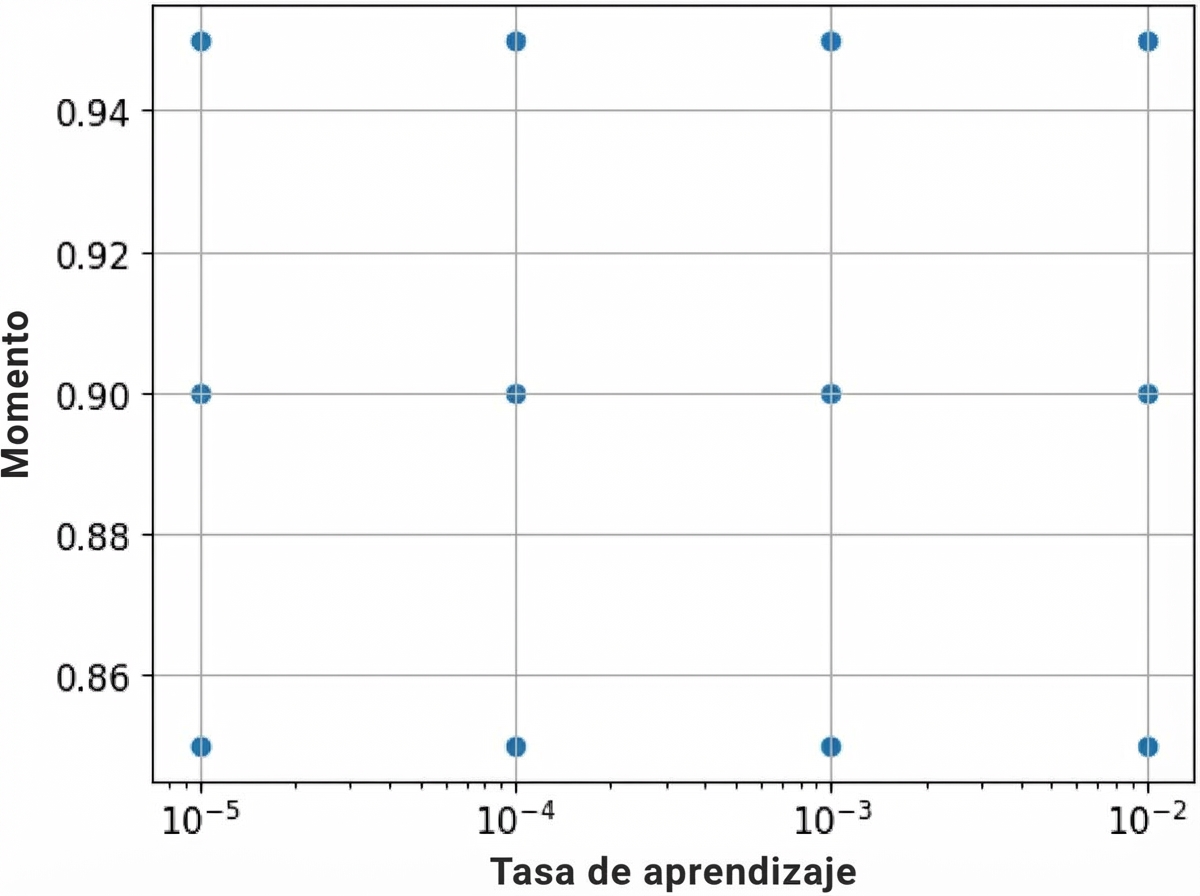
- Búsqueda aleatoria
factor = np.random.uniform(2, 6)
lr = 10 ** -factor