Evaluación del rendimiento de los modelos
Introducción al aprendizaje profundo con PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
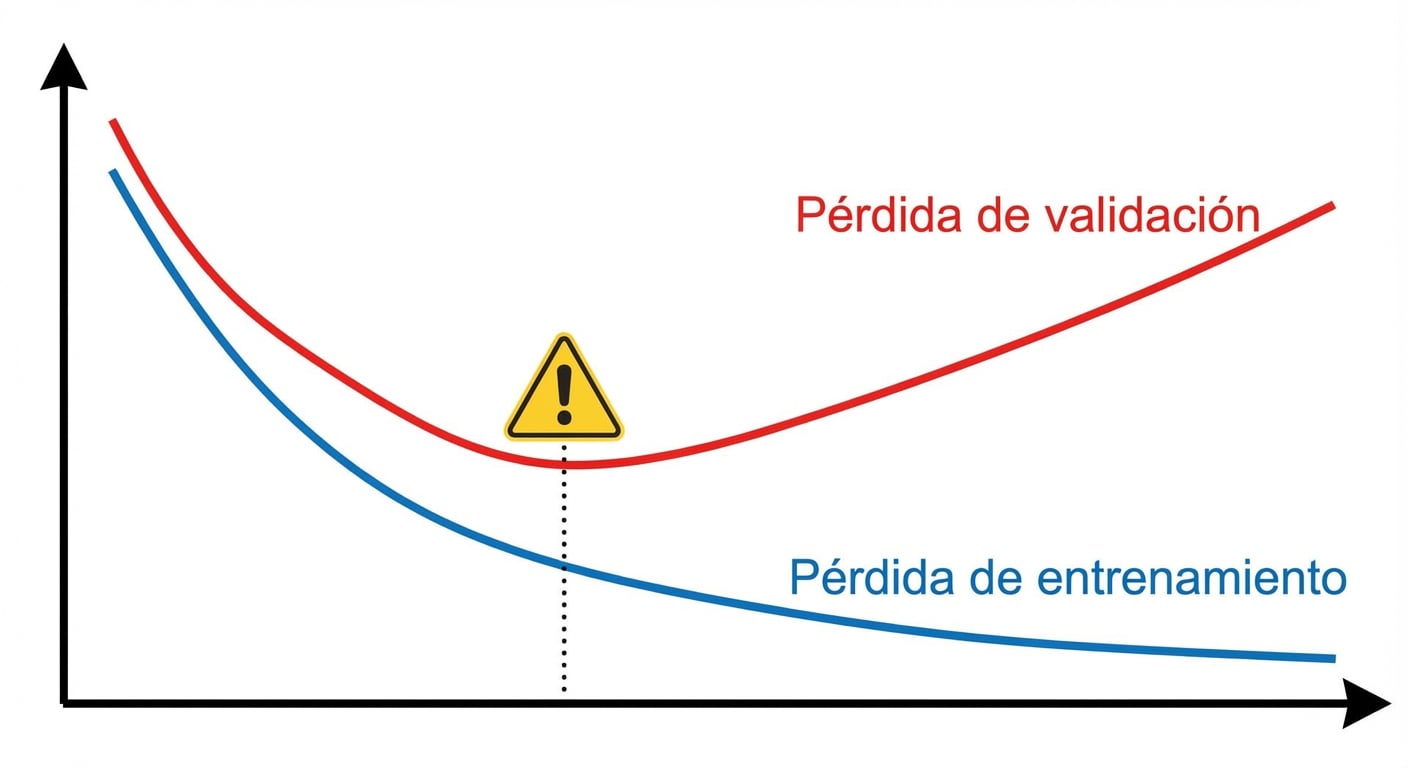
Sobreajuste
Introducción al aprendizaje profundo con PyTorch
Jasmin Ludolf
Senior Data Science Content Developer, DataCamp

