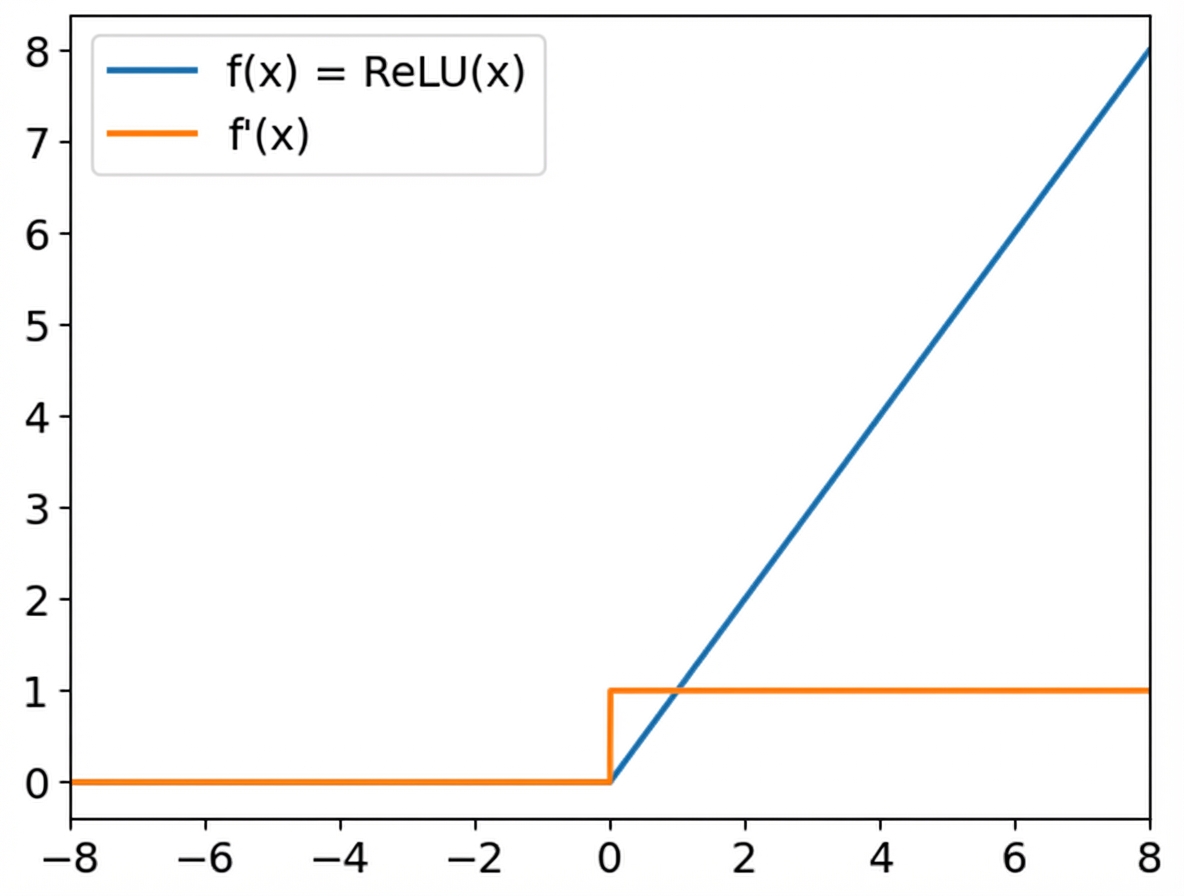
Funciones de activación ReLU
Introducción al aprendizaje profundo con PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
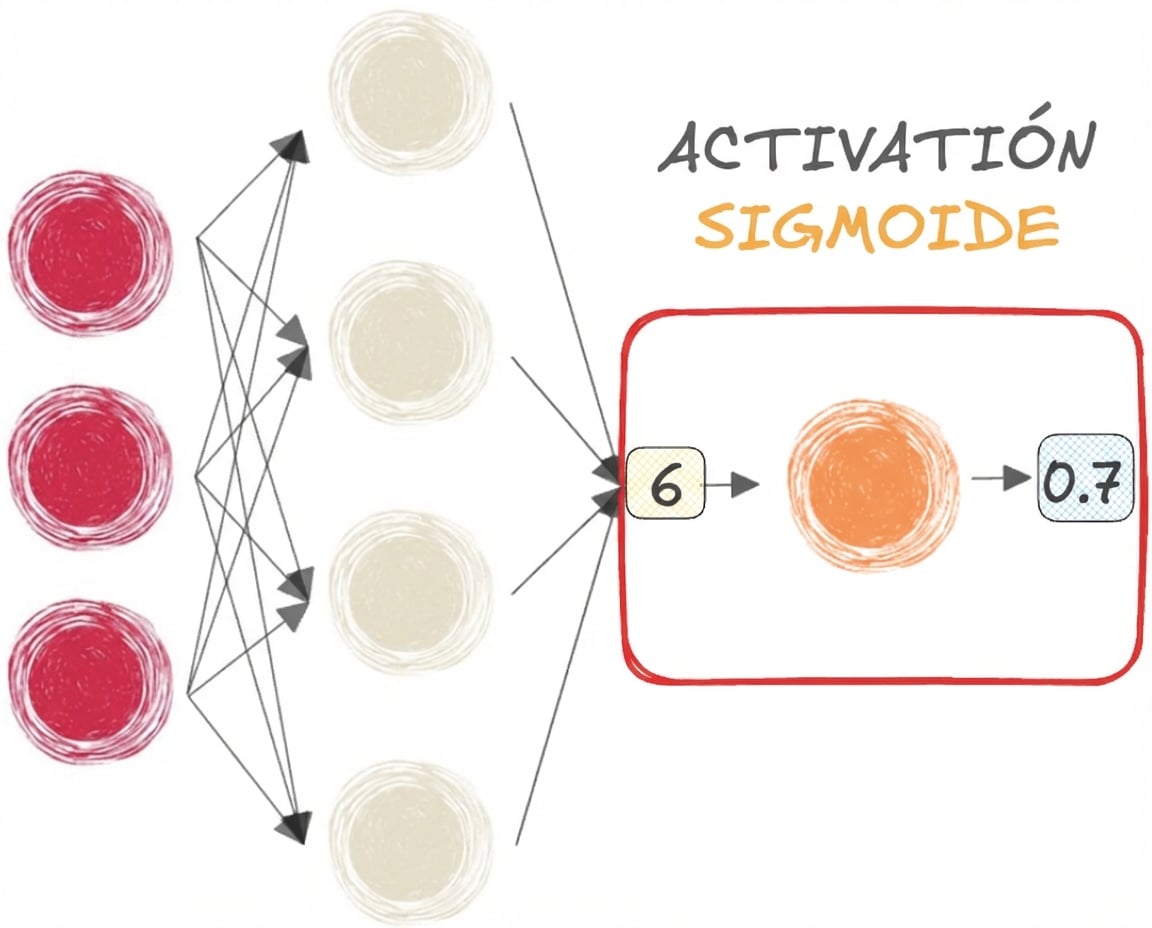
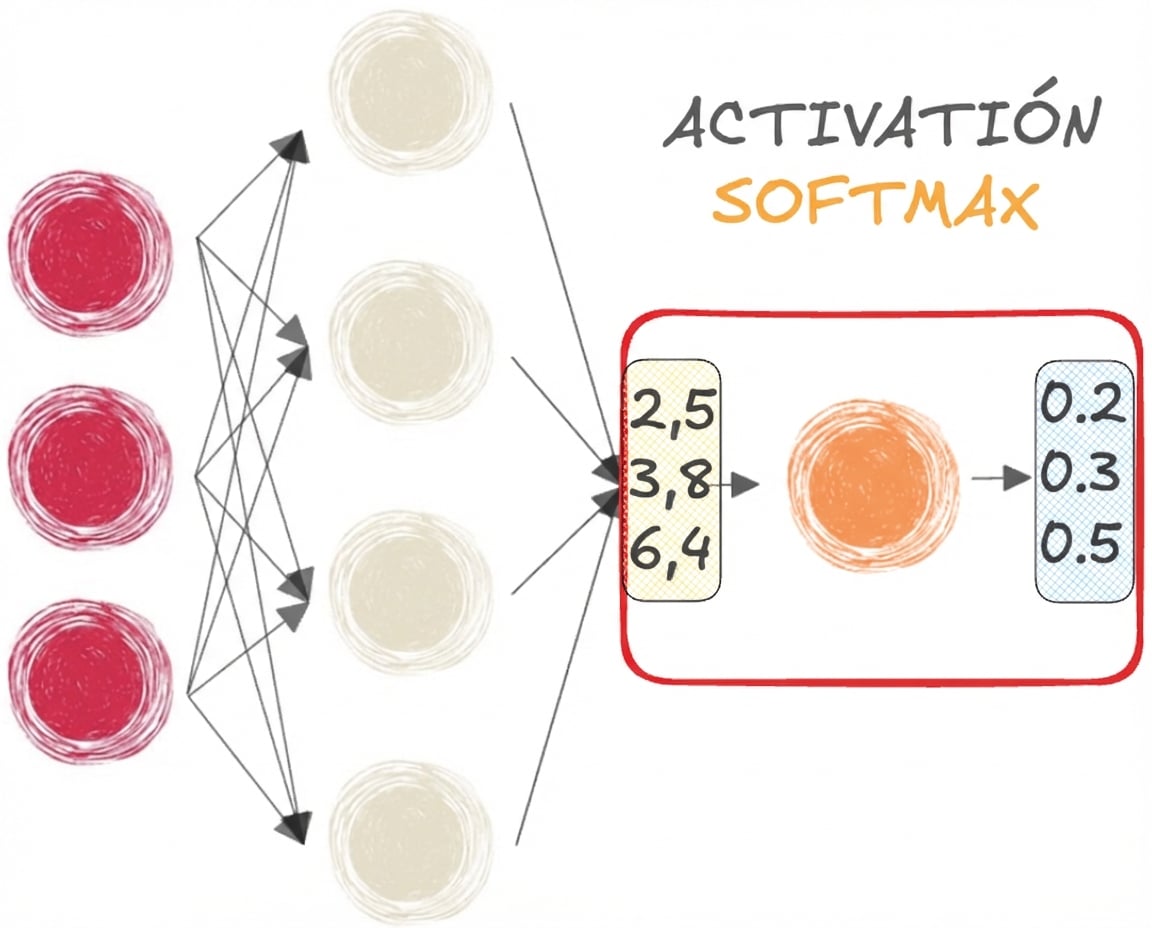
Funciones sigmoide y softmax
$$
- SIGMOID para BINARY clasificación
$$
- SOFTMAX para clasificación MULTICLASE
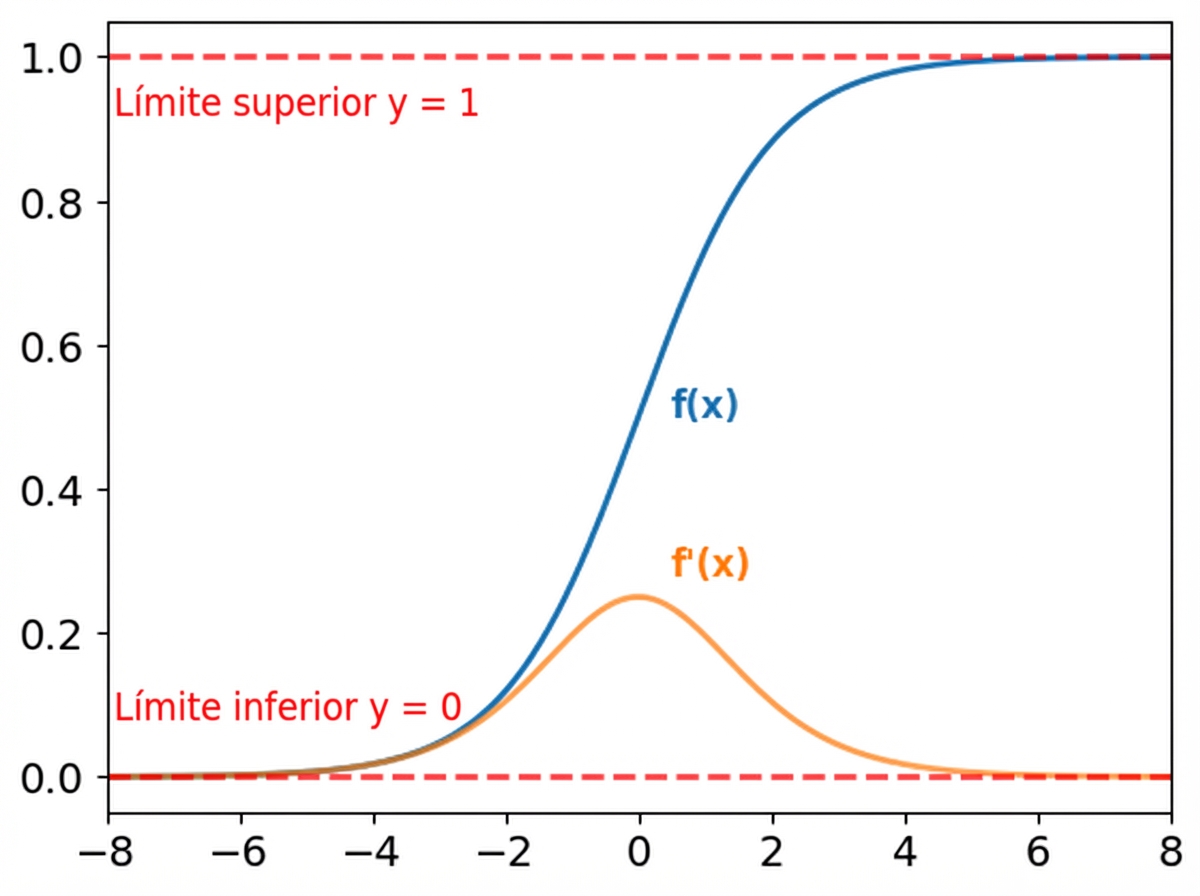
Limitaciones de la función sigmoide y softmax
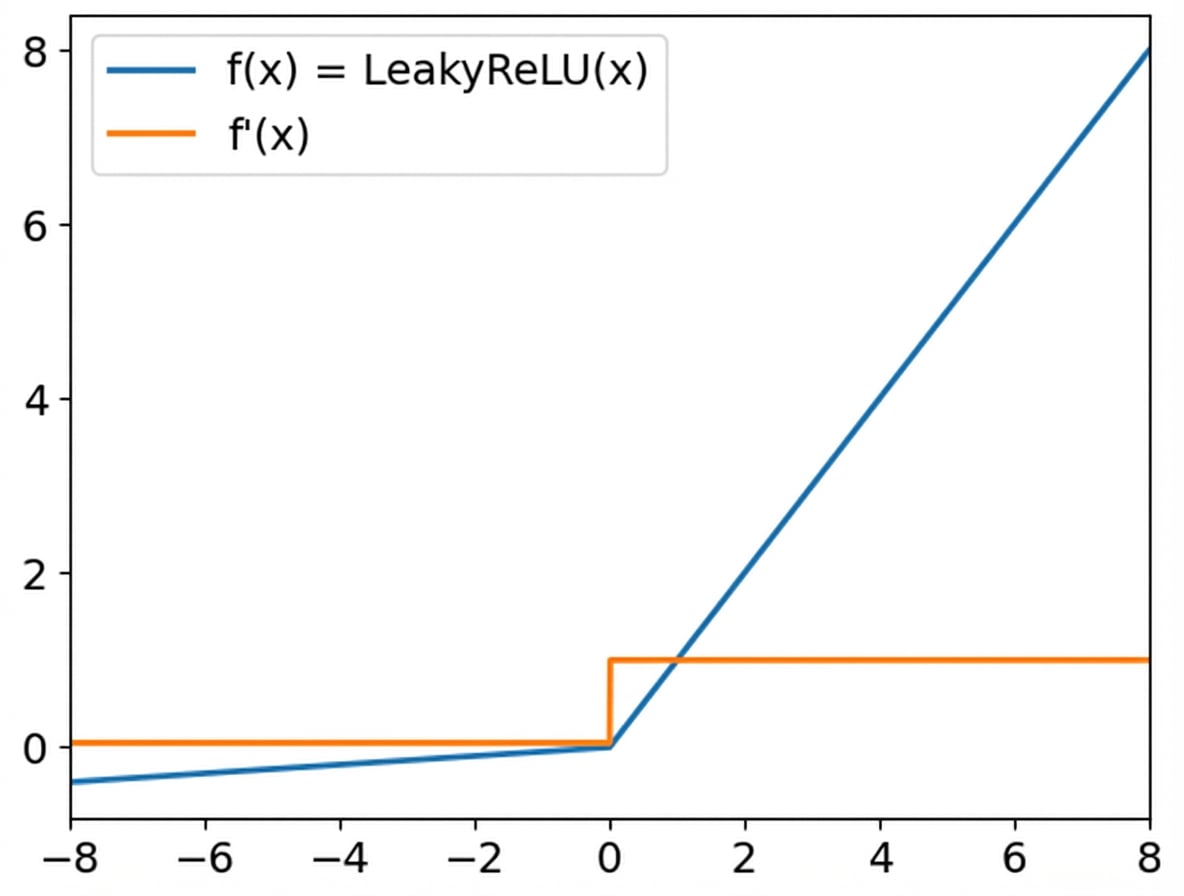
ReLU
Leaky ReLu