Ritmo de aprendizaje e impulso
Introducción al aprendizaje profundo con PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
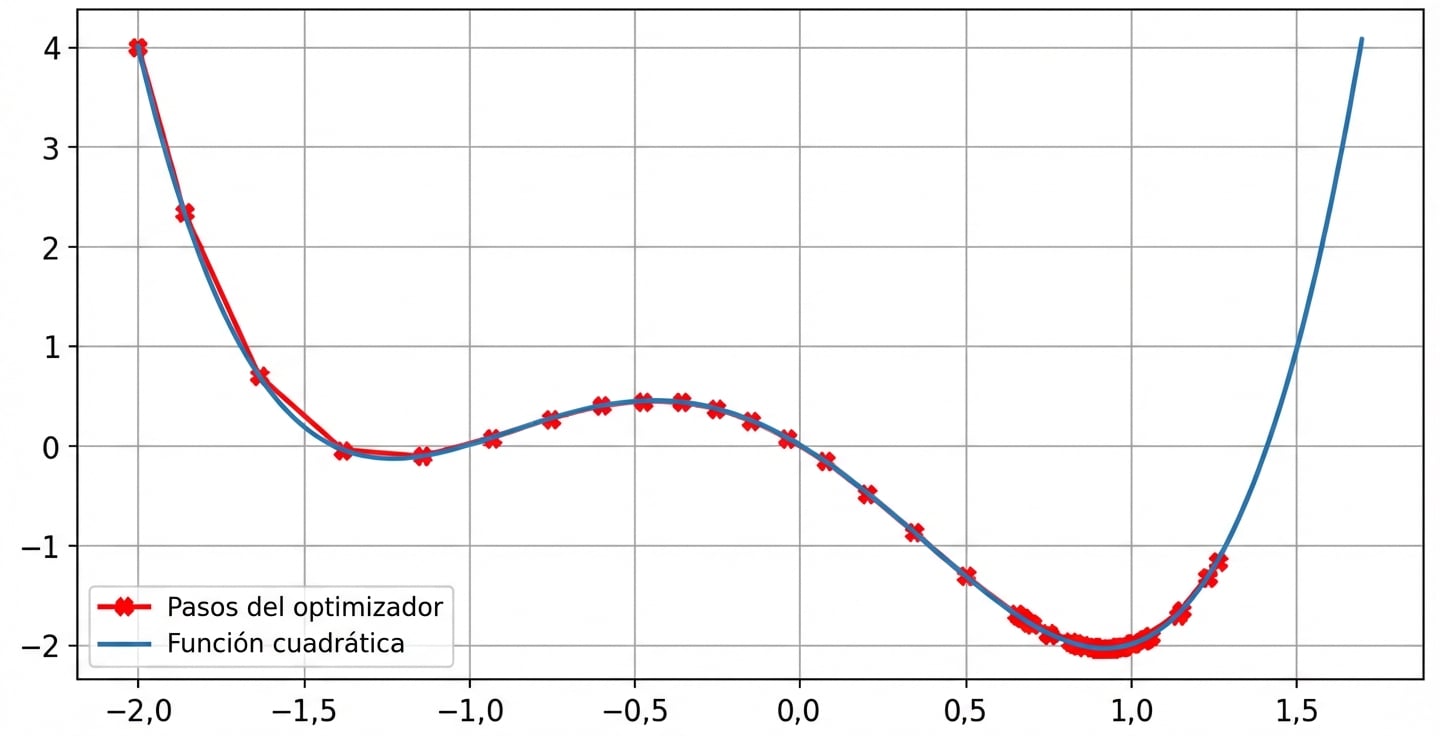
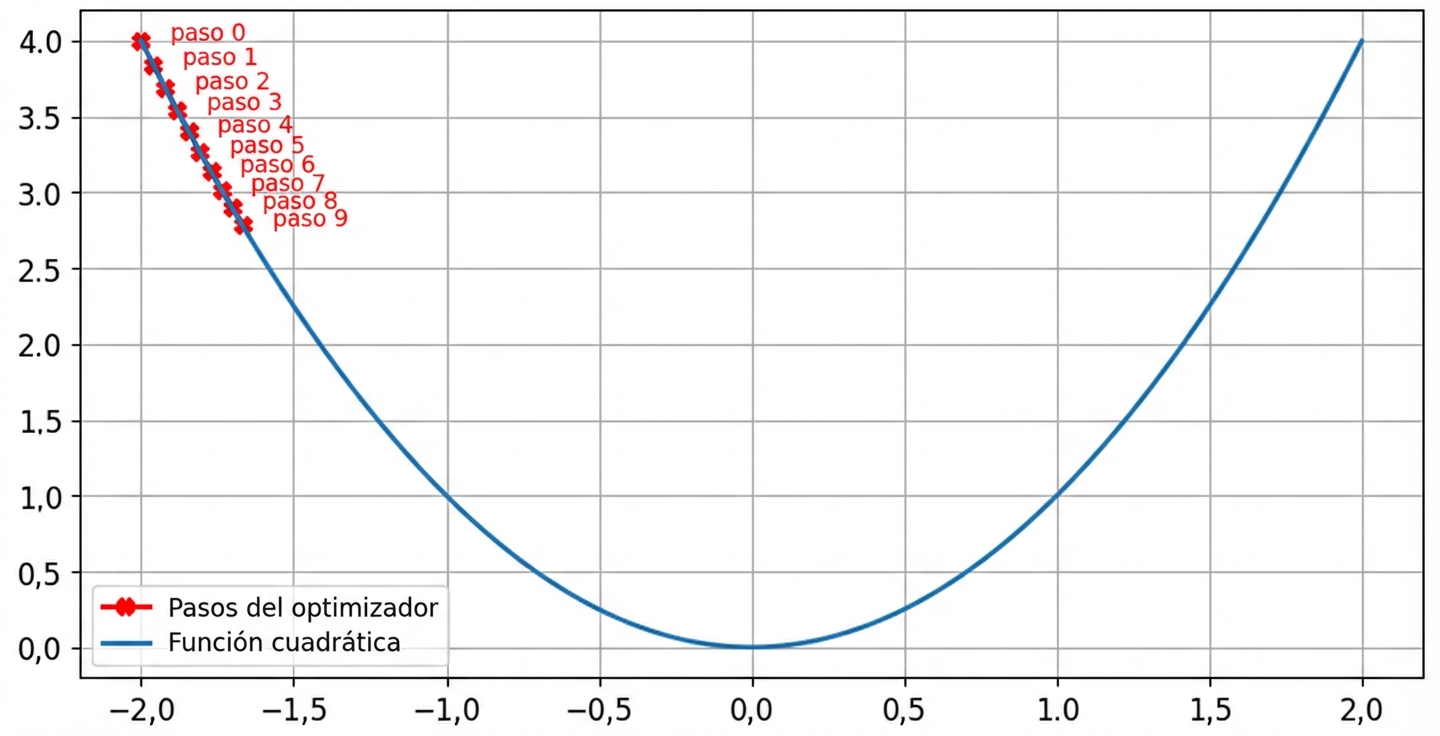
Impacto de la tasa de aprendizaje: ritmo de aprendizaje óptimo
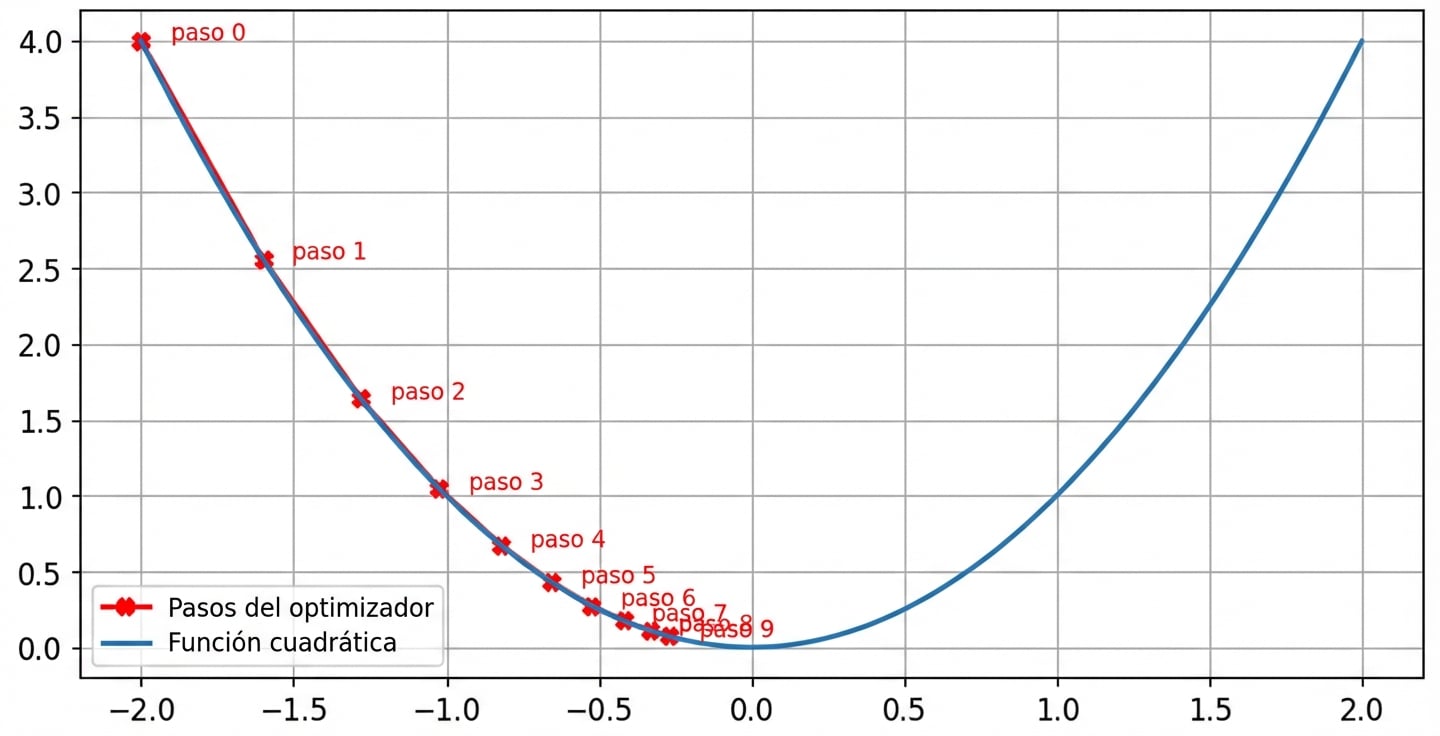
- El tamaño del paso disminuye casi a cero a medida que el gradiente se hace más pequeño
Impacto de la tasa de aprendizaje: ritmo de aprendizaje insuficiente
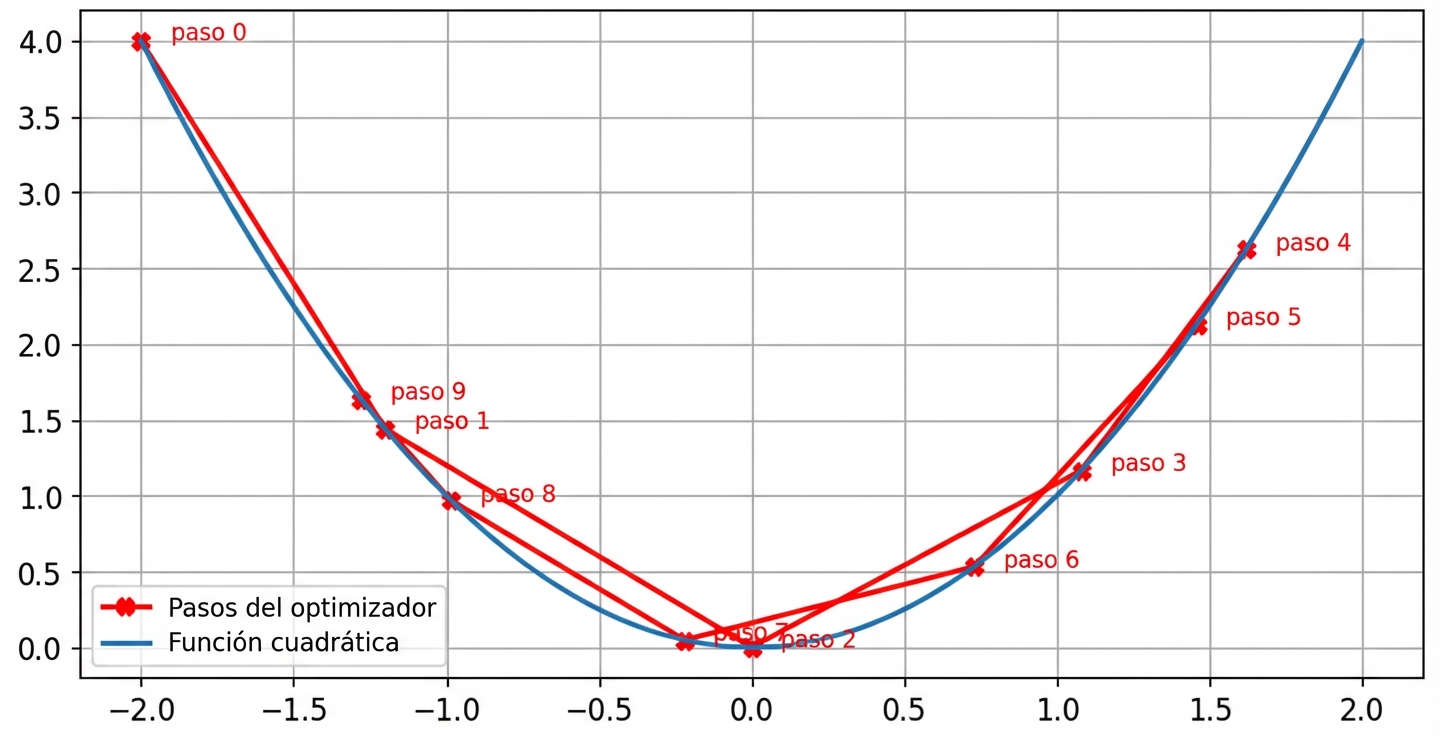
Impacto de la tasa de aprendizaje: elevado ritmo de aprendizaje
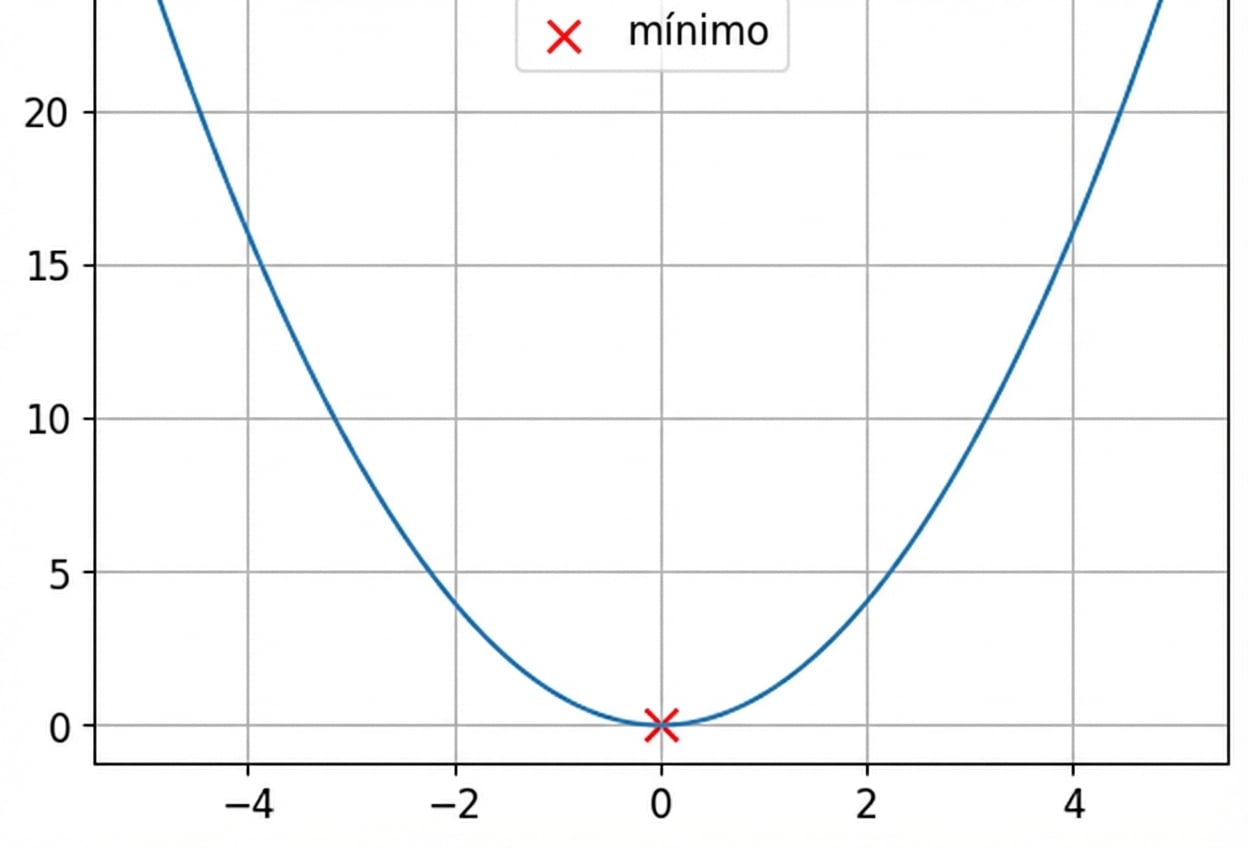
Funciones convexas y no convexas
Se trata de una función convexa.
Se trata de una función no convexa.
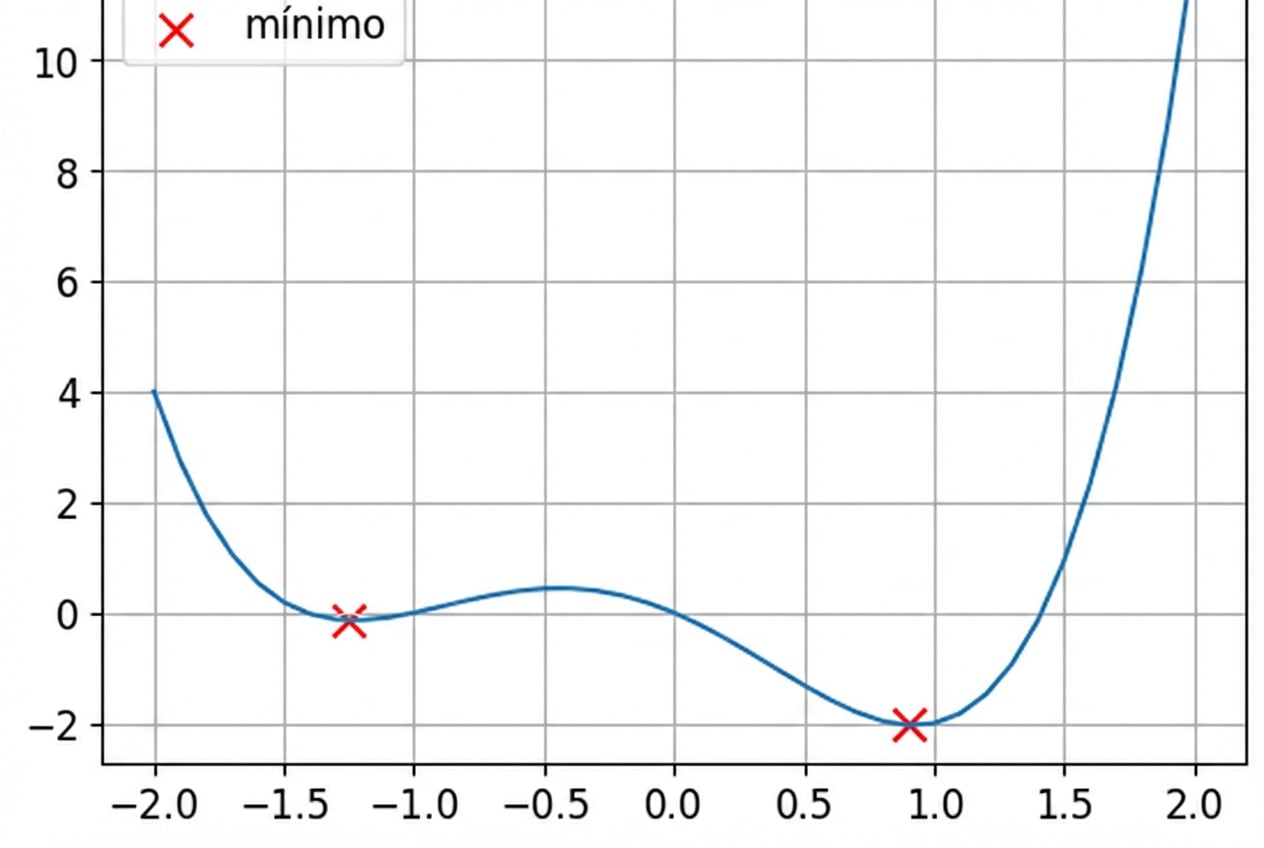
- Las funciones de pérdida no son convexas
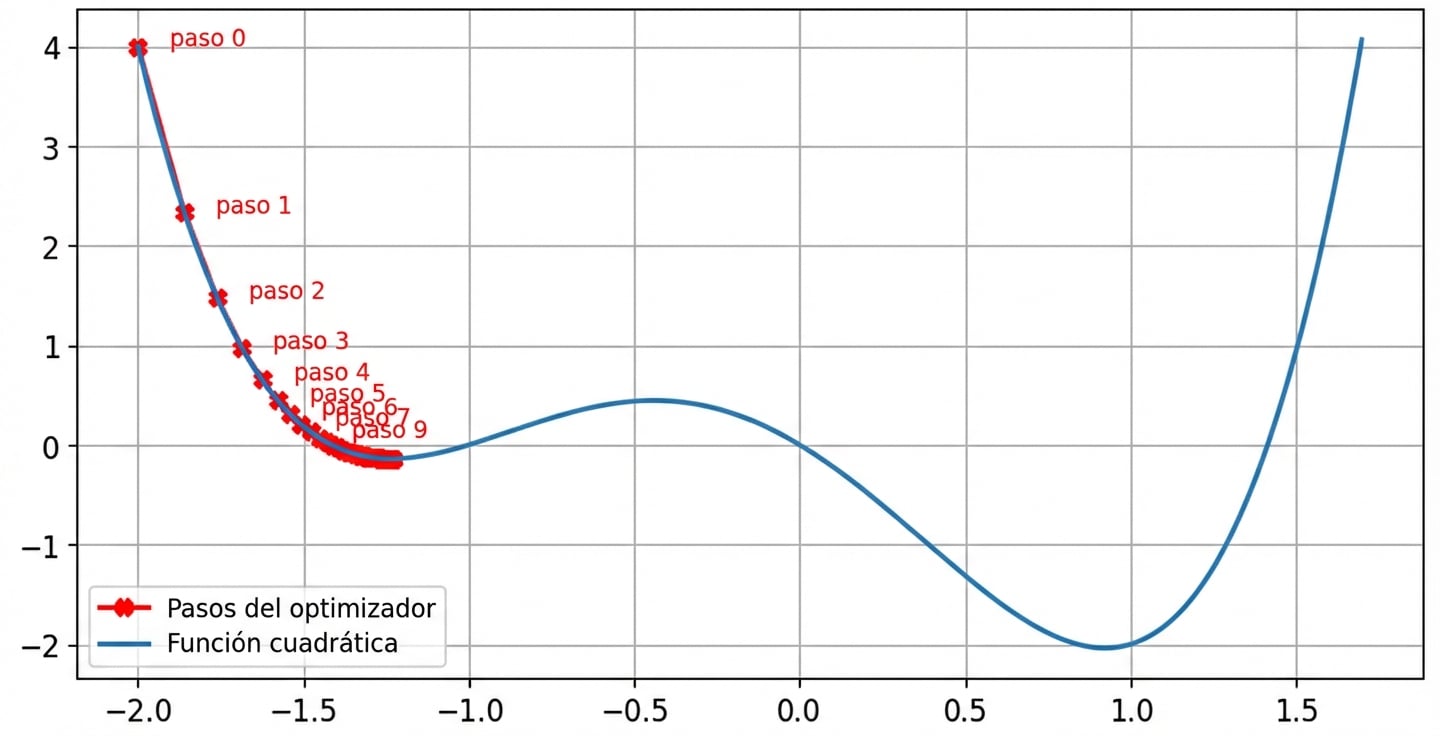
Sin impulso
lr = 0.01momentum = 0después de 100 pasos se ha encontrado el mínimo parax = -1.23yy = -0.14
Con impulso
lr = 0.01momentum = 0.9después de 100 pasos se ha encontrado el mínimo parax = 0.92yy = -2.04