Diagnosticar problemas de sesgo y varianza
Machine learning con modelos basados en árboles en Python

Elie Kawerk
Data Scientist
Estimar el error de generalización
¿Cómo estimar el error de generalización de un modelo?
No se puede directamente porque:
$f$ es desconocida,
normalmente solo tienes un dataset,
el ruido es impredecible.
Estimar el error de generalización
Solución:
- divide los datos en entrenamiento y prueba,
- ajusta $\hat{f}$ al conjunto de entrenamiento,
- evalúa el error de $\hat{f}$ en el conjunto de prueba no visto.
- error de generalización de $\hat{f} \approx$ error en prueba de $\hat{f}$.
Mejor evaluación con validación cruzada
No toques el conjunto de prueba hasta estar seguro del rendimiento de $\hat{f}$.
Evaluar $\hat{f}$ en entrenamiento: estimación sesgada; $\hat{f}$ ya vio todos los puntos.
Solución → Validación cruzada (CV):
K-Fold CV,
Hold-Out CV.
K-Fold CV
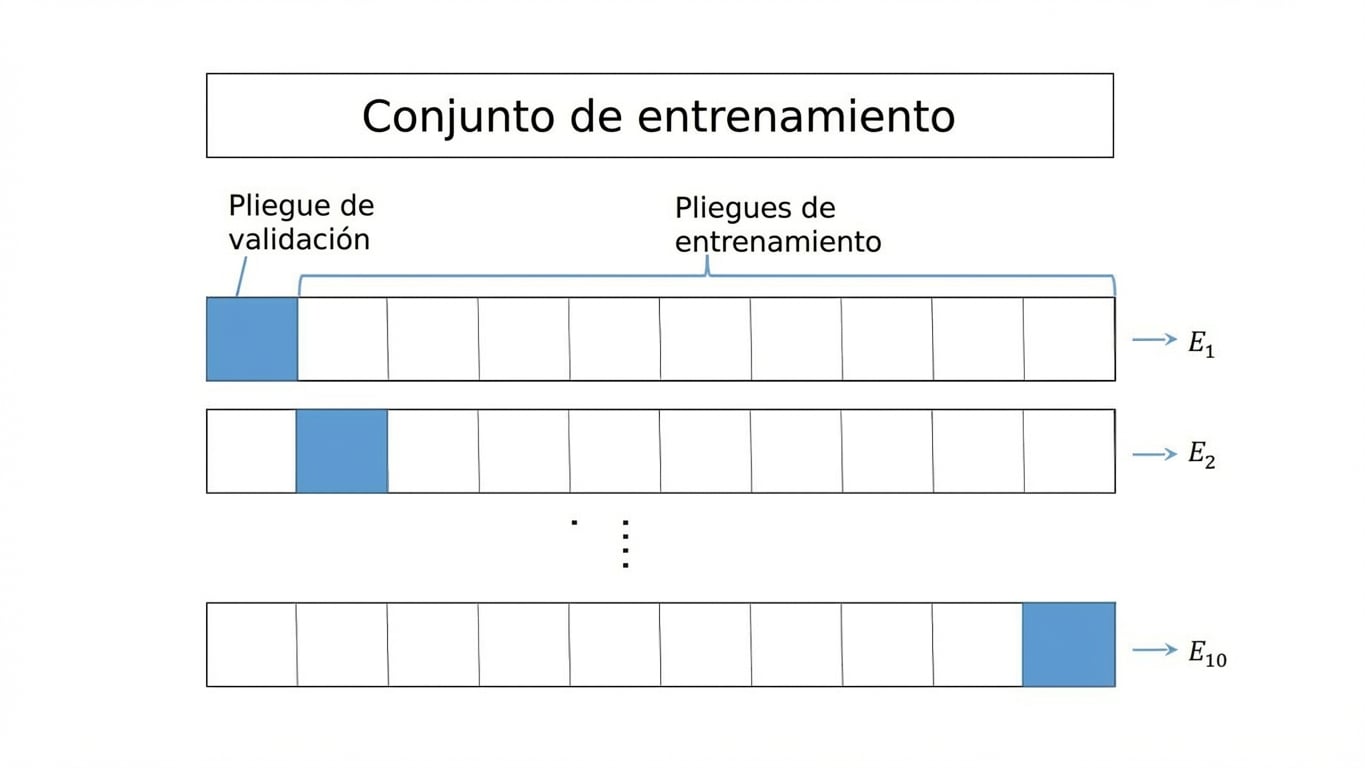
K-Fold CV
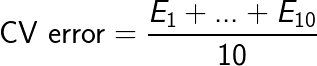
Diagnosticar problemas de varianza
Si $\hat{f}$ tiene alta varianza:
El error de CV de $\hat{f}$ > el error en entrenamiento de $\hat{f}$.
- $\hat{f}$ sobreajusta el entrenamiento. Para corregirlo:
- reduce la complejidad del modelo,
- p. ej.: reduce la prof. máx., aumenta mín. muestras por hoja, ...
- reúne más datos, ...
Diagnosticar problemas de sesgo
Si $\hat{f}$ tiene alto sesgo:
Error de CV de $\hat{f} \approx$ error en entrenamiento de $\hat{f} >>$ error deseado.
$\hat{f}$ infraajusta el entrenamiento. Para corregirlo:
- aumenta la complejidad del modelo
- p. ej.: aumenta la prof. máx., reduce mín. muestras por hoja, ...
- incorpora más variables relevantes
K-Fold CV en sklearn con el conjunto Auto
from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error as MSE from sklearn.model_selection import cross_val_score# Set seed for reproducibility SEED = 123 # Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=SEED)# Instantiate decision tree regressor and assign it to 'dt' dt = DecisionTreeRegressor(max_depth=4, min_samples_leaf=0.14, random_state=SEED)
K-Fold CV en sklearn con el conjunto Auto
# Evaluate the list of MSE ontained by 10-fold CV # Set n_jobs to -1 in order to exploit all CPU cores in computation MSE_CV = - cross_val_score(dt, X_train, y_train, cv= 10, scoring='neg_mean_squared_error', n_jobs = -1)# Fit 'dt' to the training set dt.fit(X_train, y_train) # Predict the labels of training set y_predict_train = dt.predict(X_train) # Predict the labels of test set y_predict_test = dt.predict(X_test)
# CV MSE
print('CV MSE: {:.2f}'.format(MSE_CV.mean()))
CV MSE: 20.51
# Training set MSE
print('Train MSE: {:.2f}'.format(MSE(y_train, y_predict_train)))
Train MSE: 15.30
# Test set MSE
print('Test MSE: {:.2f}'.format(MSE(y_test, y_predict_test)))
Test MSE: 20.92
¡Vamos a practicar!
Machine learning con modelos basados en árboles en Python

