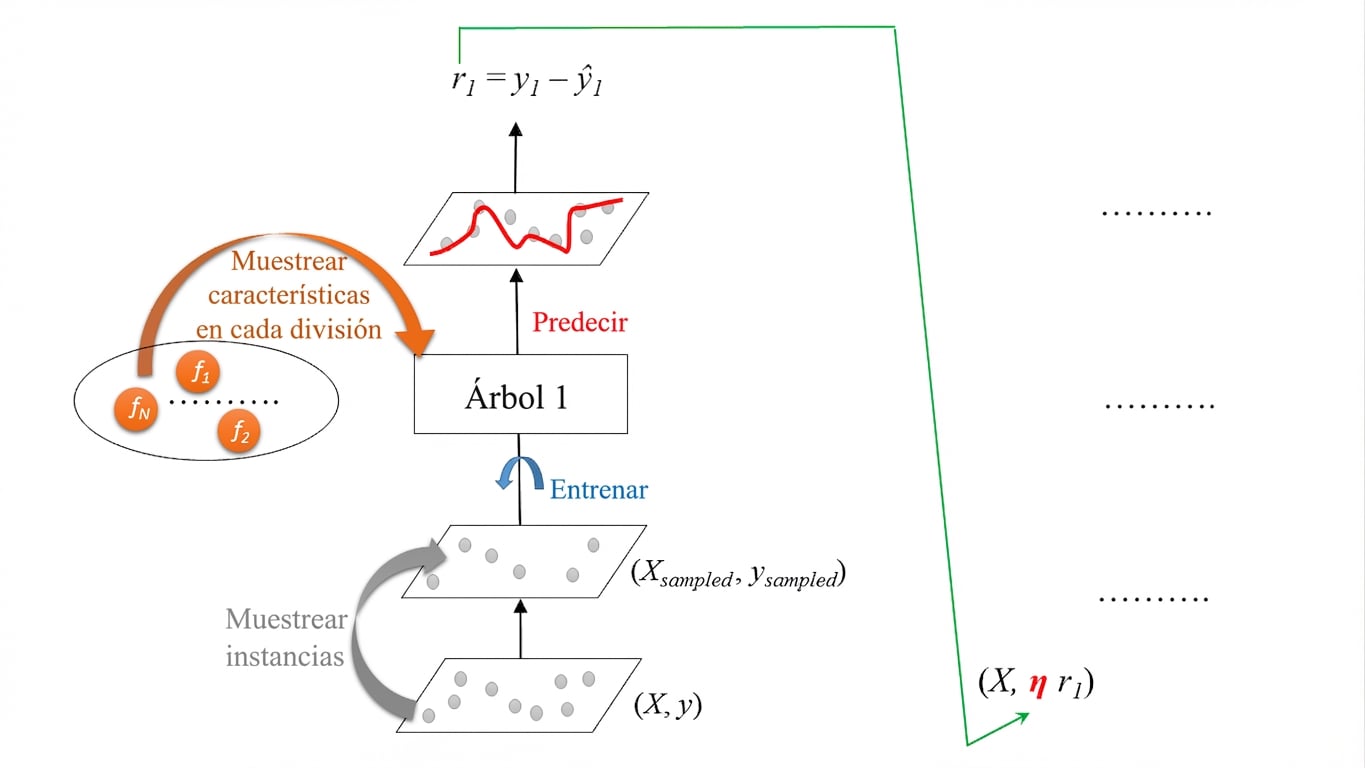
Gradient Boosting estocástico (SGB)
Machine learning con modelos basados en árboles en Python

Elie Kawerk
Data Scientist
Gradient Boosting estocástico: Entrenamiento
Machine learning con modelos basados en árboles en Python
Elie Kawerk
Data Scientist

