Random Forests
Machine learning con modelos basados en árboles en Python

Elie Kawerk
Data Scientist
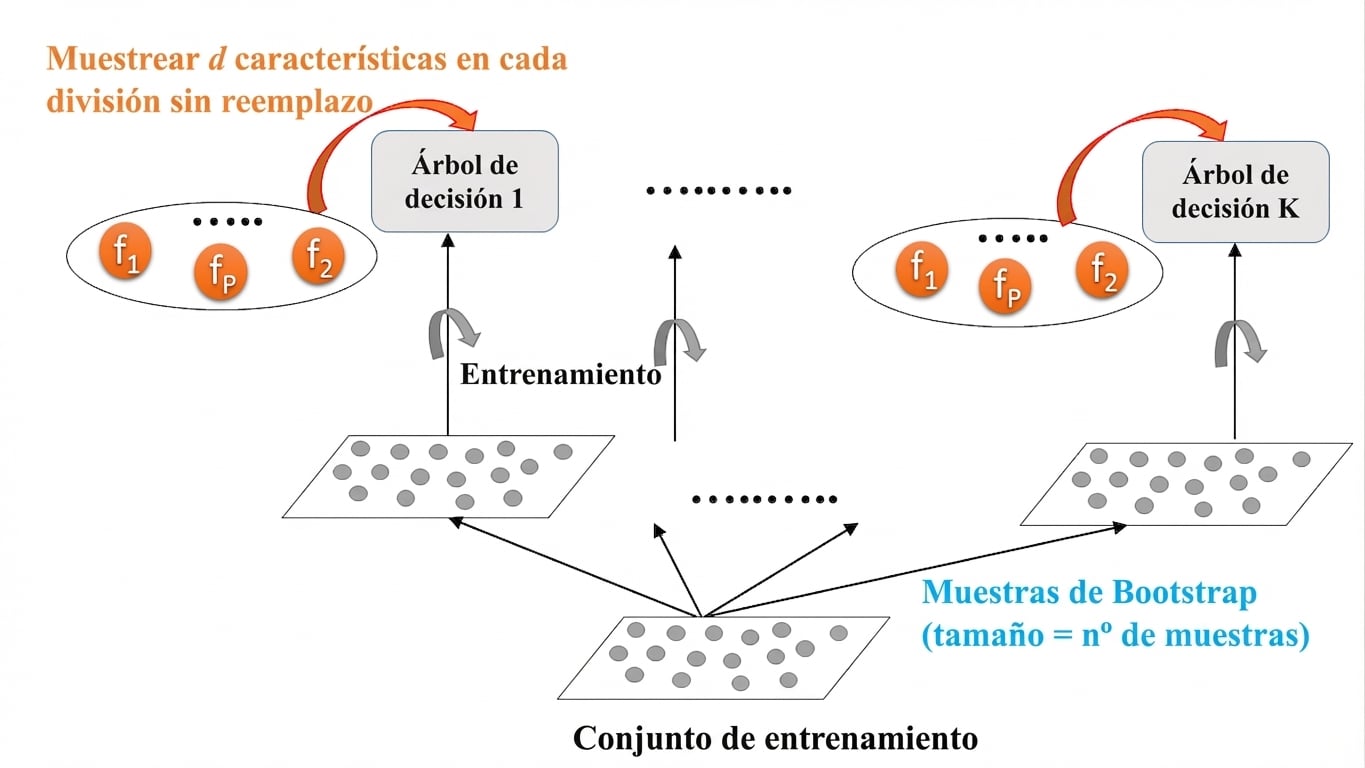
Random Forests: Entrenamiento
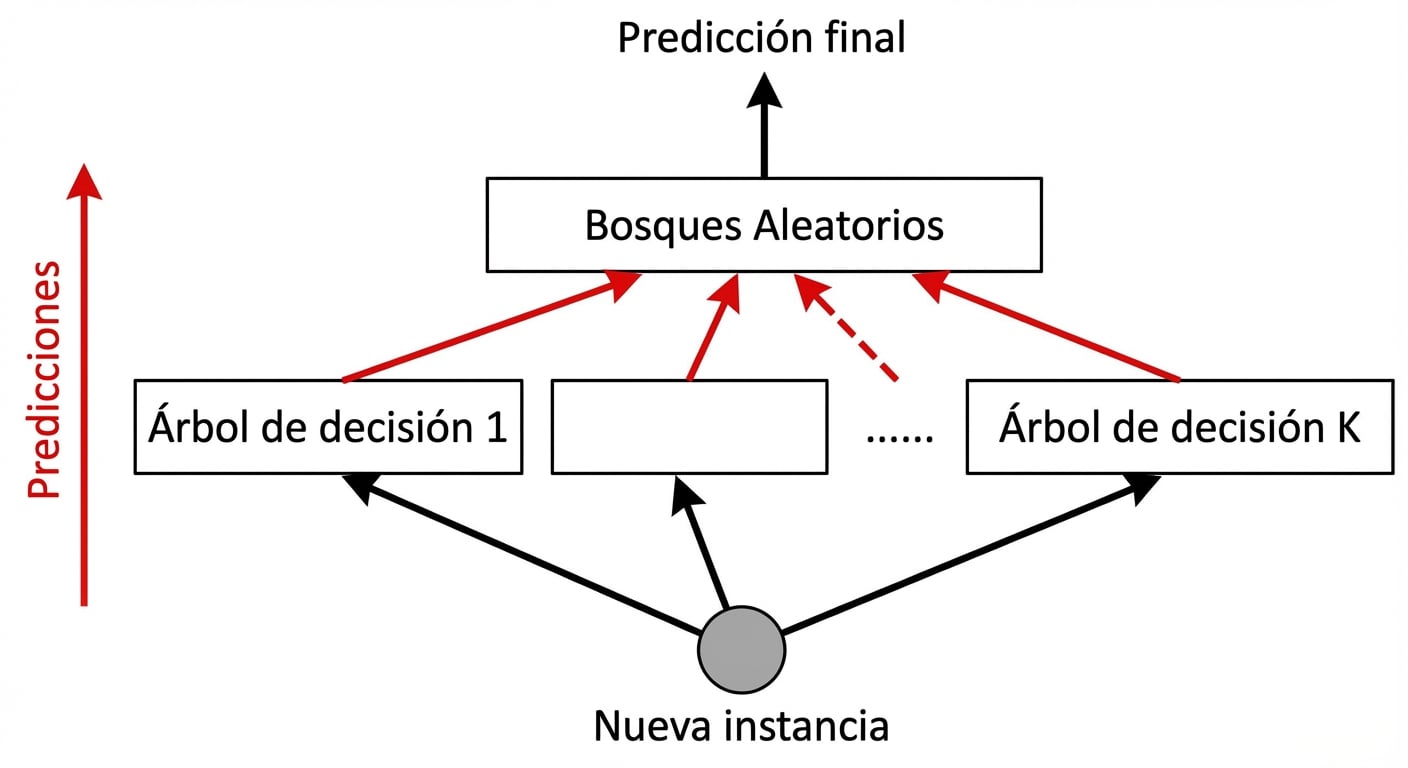
Random Forests: Predicción
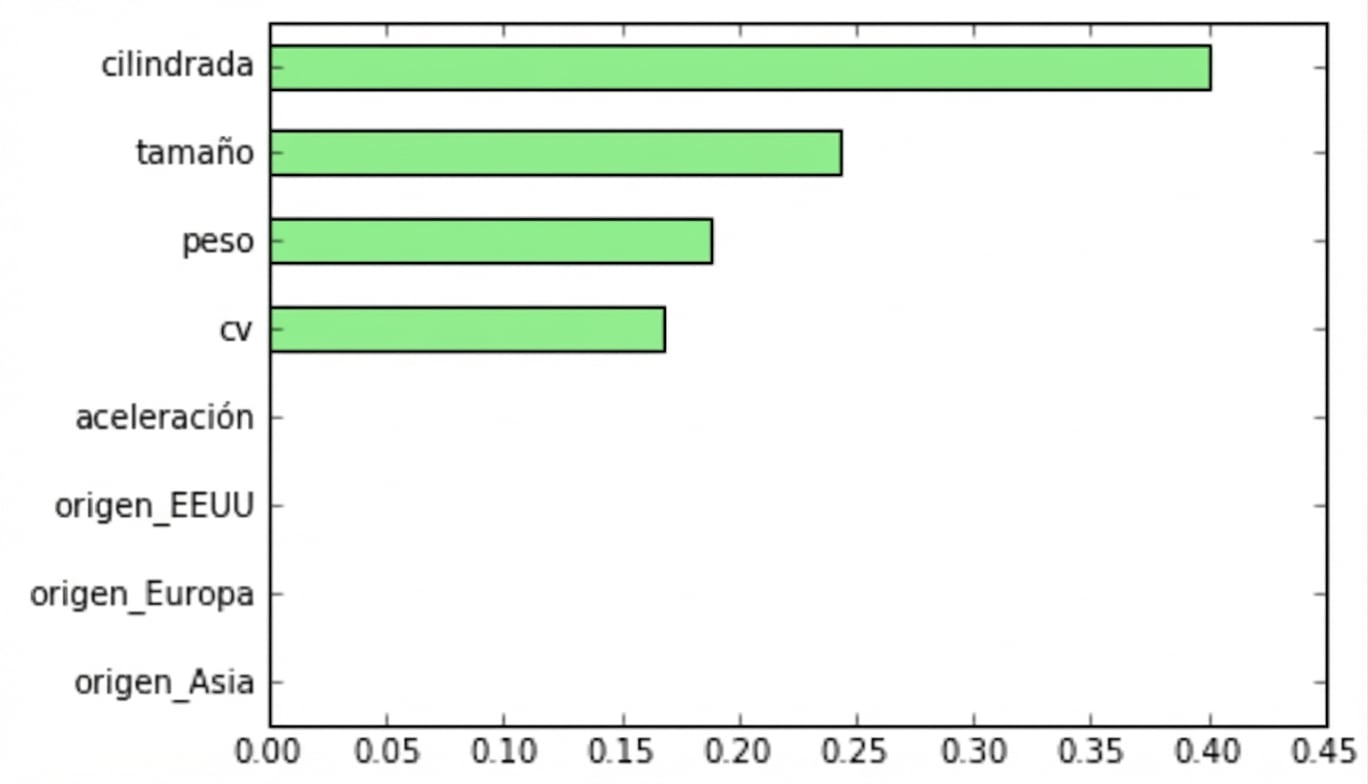
Importancia de variables en sklearn
Machine learning con modelos basados en árboles en Python
Elie Kawerk
Data Scientist

