Ensembles
Machine learning con modelos basados en árboles en Python

Elie Kawerk
Data Scientist
Ventajas de los CART
Fácil de entender.
Fácil de interpretar.
Fácil de usar.
Flexible: puede capturar dependencias no lineales.
Preprocesado: no requiere estandarizar ni normalizar, ...
Limitaciones de los CART
Clasificación: solo produce fronteras ortogonales.
Sensible a pequeñas variaciones del entrenamiento.
Alta varianza: los CART sin restricciones pueden sobreajustar.
Solución: aprendizaje en ensamblado.
Ensembles
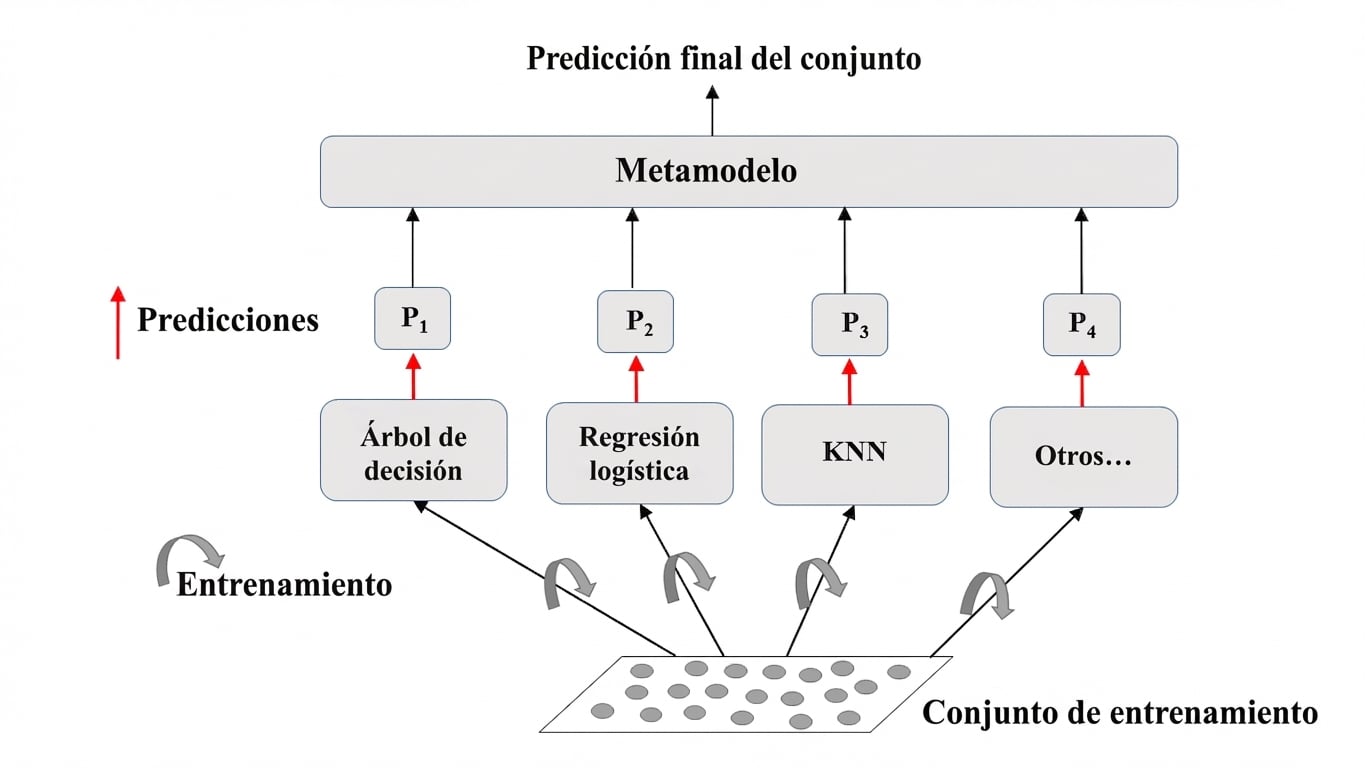
Entrena modelos distintos en el mismo dataset.
Deja que cada modelo haga sus predicciones.
Meta-modelo: agrega las predicciones individuales.
Predicción final: más robusta y menos propensa a errores.
Mejores resultados: modelos con habilidades complementarias.
Ensembles: explicación visual
Ensembles en práctica: VotingClassifier
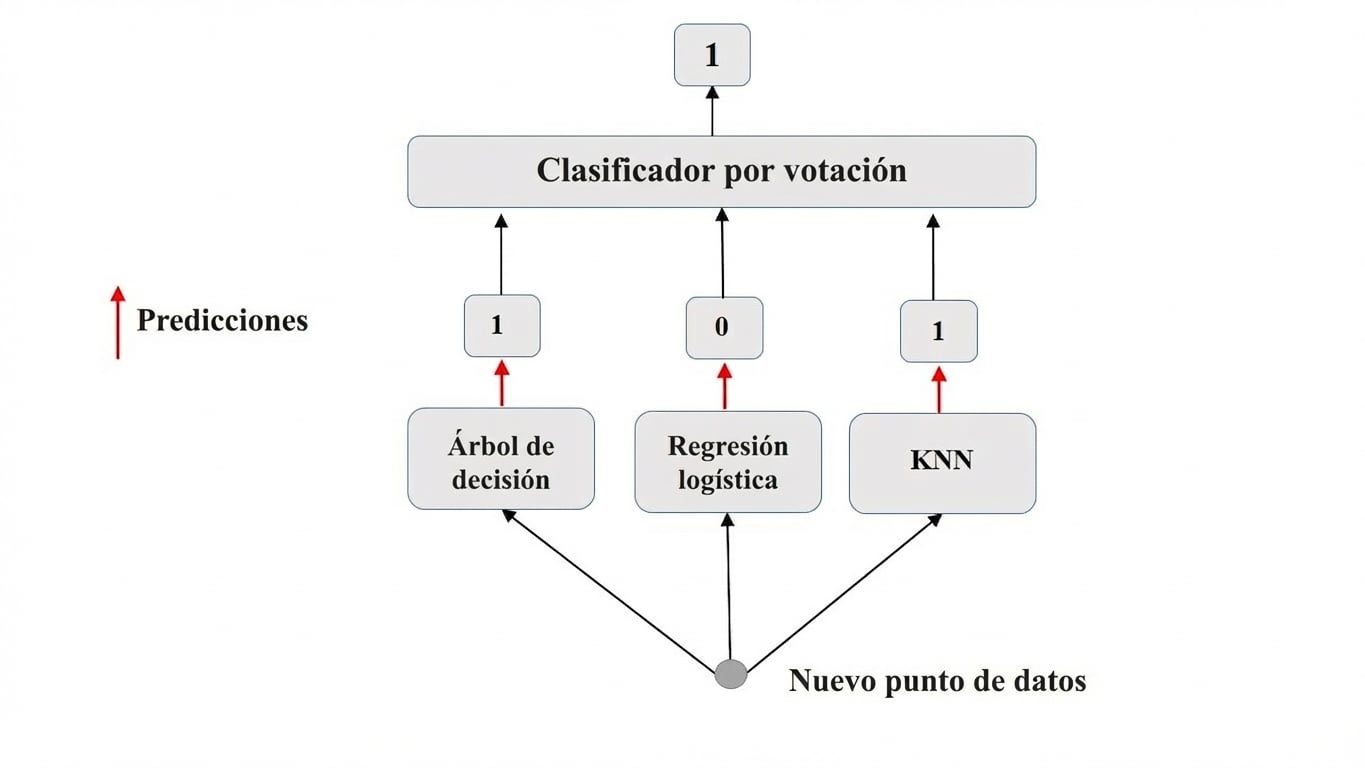
Tarea de clasificación binaria.
$N$ clasificadores predicen: $P_1$, $P_2$, ..., $P_N$ con $P_i$ = 0 o 1.
Predicción del meta-modelo: votación dura.
Votación dura
VotingClassifier en sklearn (Breast-Cancer)
# Importa funciones para calcular accuracy y dividir datos
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Importa modelos, incluido el meta-modelo VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.ensemble import VotingClassifier
# Fija semilla para reproducibilidad
SEED = 1
VotingClassifier en sklearn (Breast-Cancer)
# Divide datos: 70% train y 30% test X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.3, random_state= SEED) # Instancia clasificadores individuales lr = LogisticRegression(random_state=SEED) knn = KNN() dt = DecisionTreeClassifier(random_state=SEED)# Define una lista 'classifiers' con tuplas (nombre, clasificador) classifiers = [('Logistic Regression', lr), ('K Nearest Neighbours', knn), ('Classification Tree', dt)]
# Itera sobre la lista de tuplas con clasificadores
for clf_name, clf in classifiers:
# Ajusta clf al conjunto de entrenamiento
clf.fit(X_train, y_train)
# Predice etiquetas del test
y_pred = clf.predict(X_test)
# Evalúa la accuracy de clf en test
print('{:s} : {:.3f}'.format(clf_name, accuracy_score(y_test, y_pred)))
Logistic Regression: 0.947
K Nearest Neighbours: 0.930
Classification Tree: 0.930
VotingClassifier en sklearn (Breast-Cancer)
# Instancia un VotingClassifier 'vc'
vc = VotingClassifier(estimators=classifiers)
# Ajusta 'vc' al train y predice en test
vc.fit(X_train, y_train)
y_pred = vc.predict(X_test)
# Evalúa la accuracy en test de 'vc'
print('Voting Classifier: {.3f}'.format(accuracy_score(y_test, y_pred)))
Voting Classifier: 0.953
¡Vamos a practicar!
Machine learning con modelos basados en árboles en Python

