Árbol de decisión para clasificación
Machine learning con modelos basados en árboles en Python

Elie Kawerk
Data Scientist
Dataset de cáncer de mama en 2D
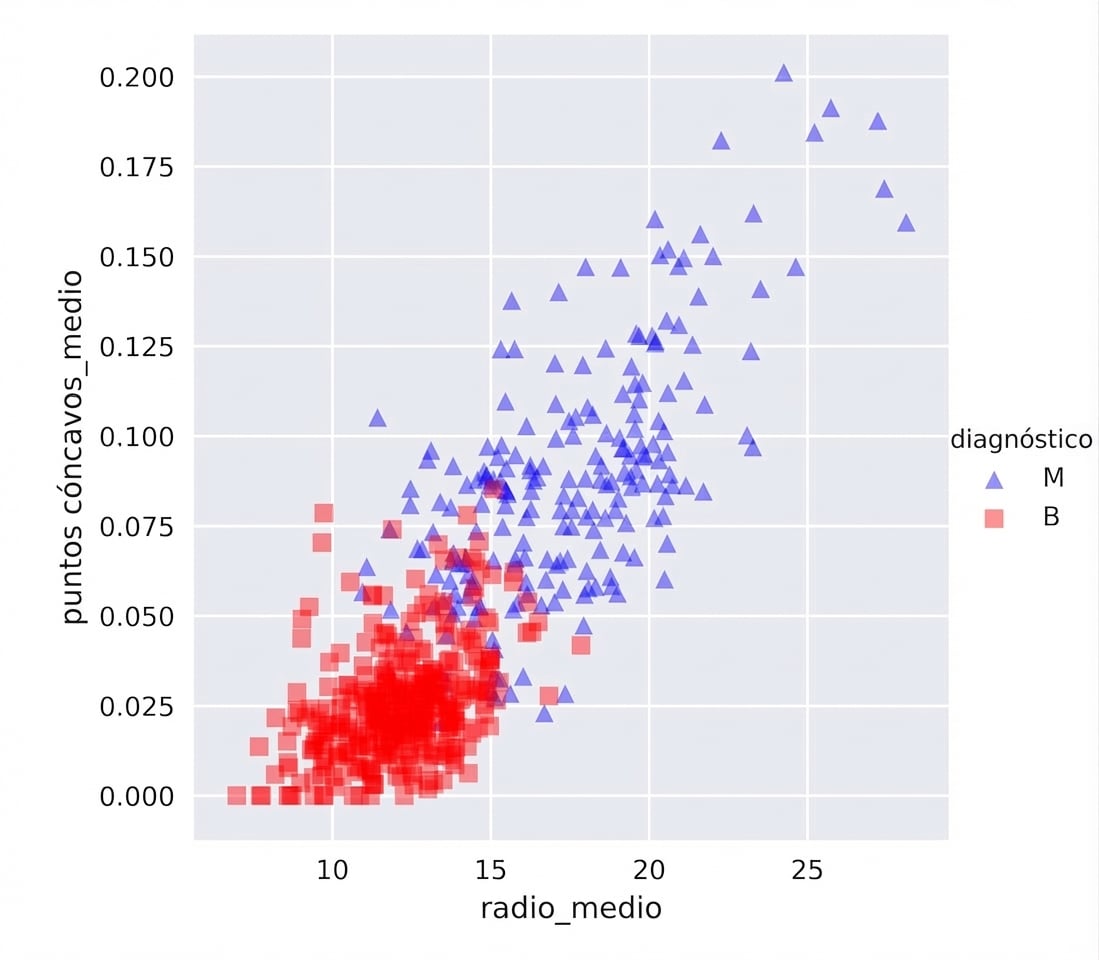
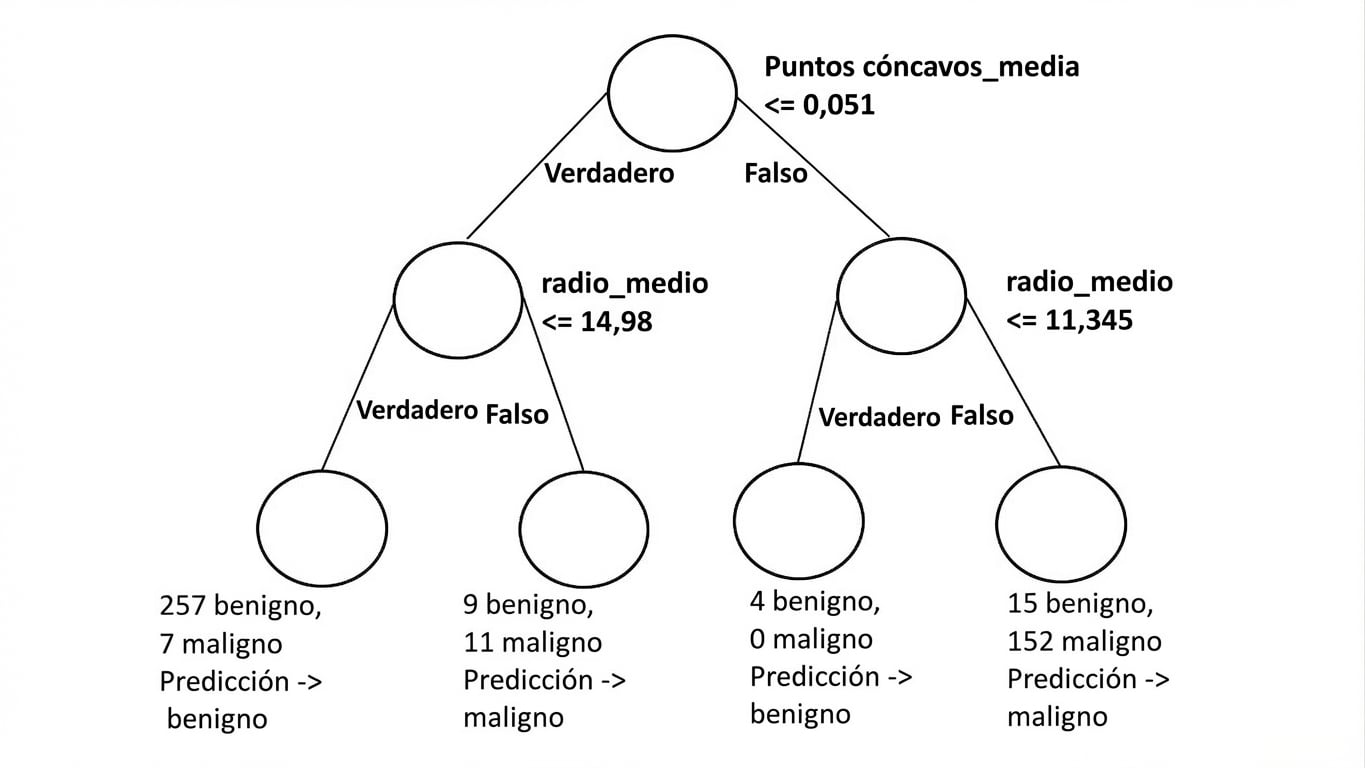
Diagrama de árbol de decisión
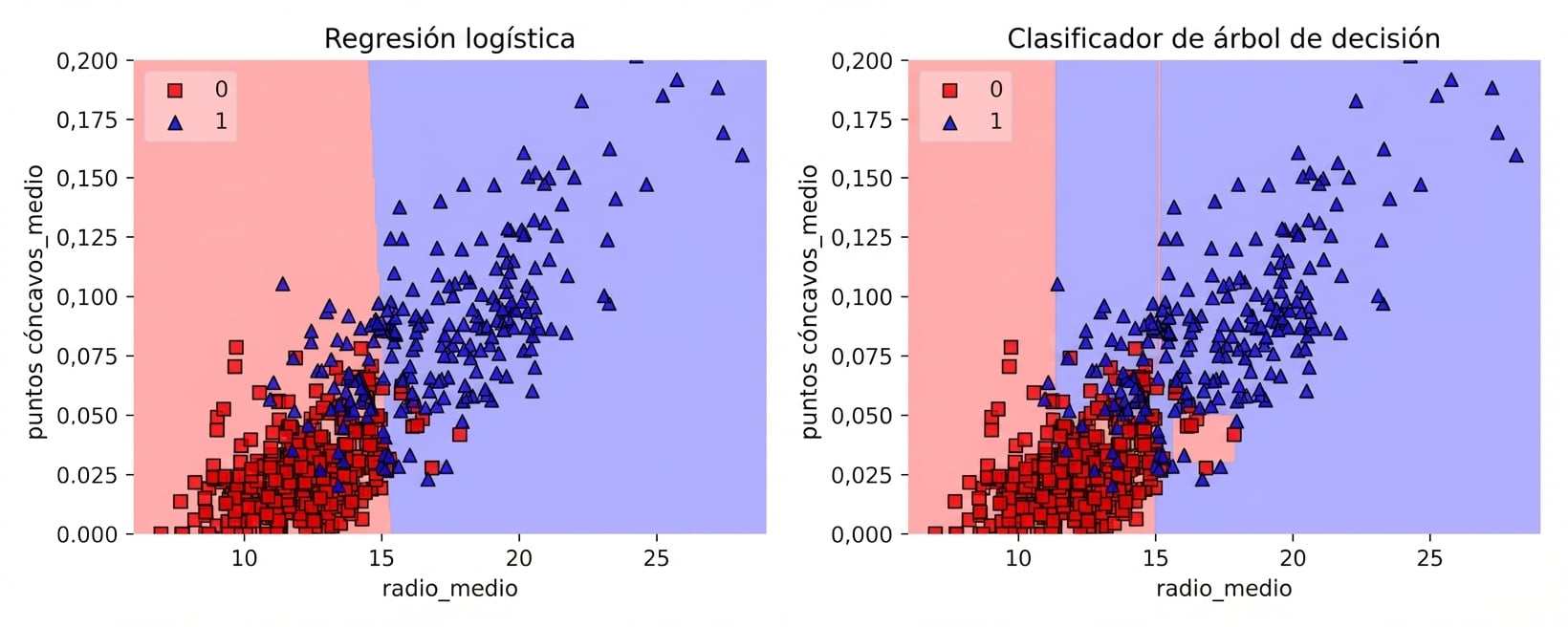
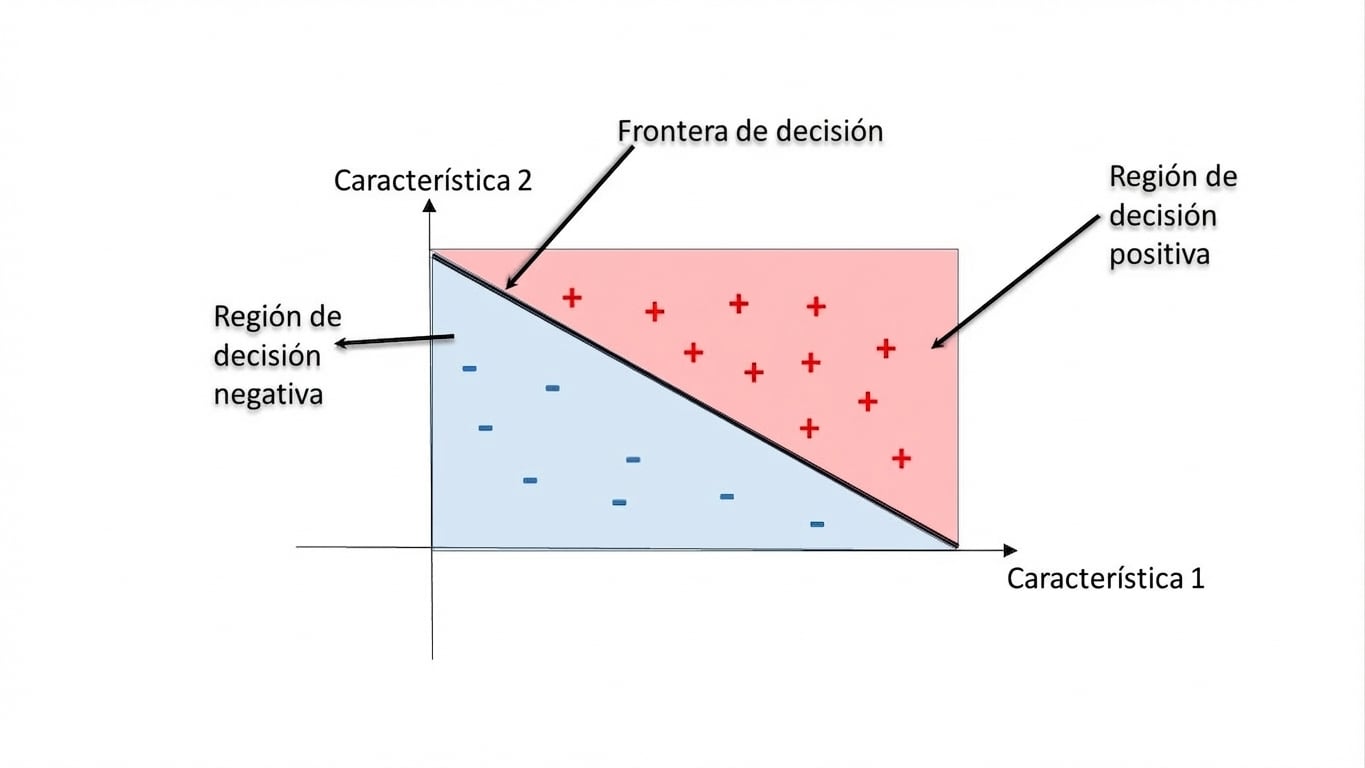
Regiones de decisión
Región de decisión: zona del espacio de atributos donde todas las instancias reciben la misma clase.
Frontera de decisión: superficie que separa distintas regiones de decisión.
Regiones de decisión: CART vs. modelo lineal