Qual é o desempenho de seu modelo?
Aprendizado Supervisionado com o scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
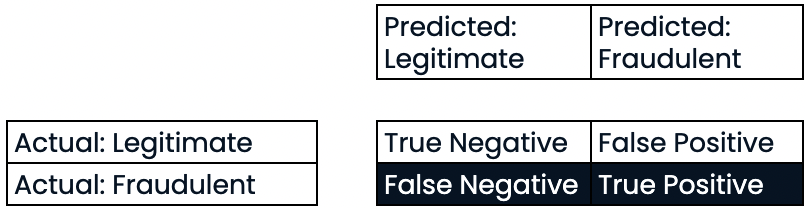
Matriz de confusão para avaliação do desempenho da classificação
- Matriz de confusão
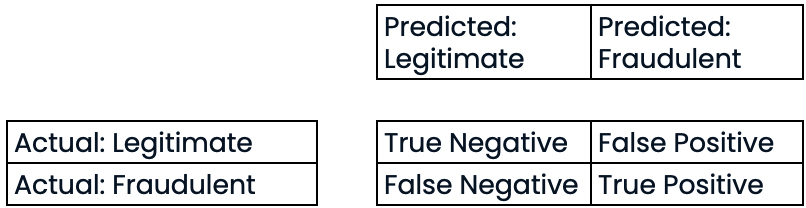
Avaliação do desempenho da classificação
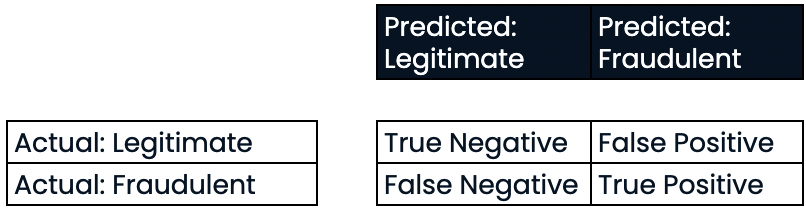
Avaliação do desempenho da classificação

Avaliação do desempenho da classificação
Avaliação do desempenho da classificação
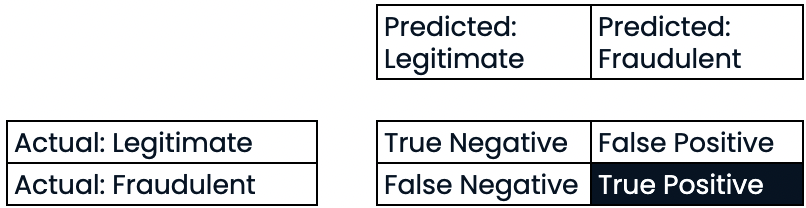
Avaliação do desempenho da classificação
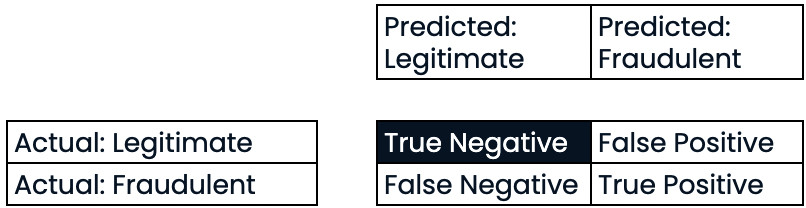
Avaliação do desempenho da classificação
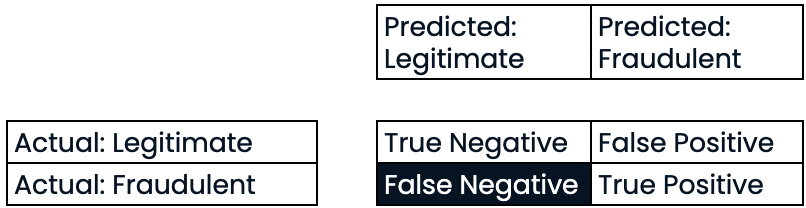
Avaliação do desempenho da classificação
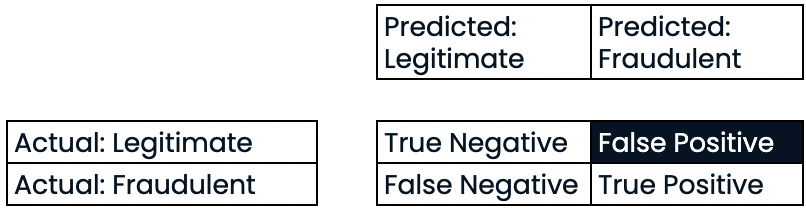
Avaliação do desempenho da classificação
- Acurácia:
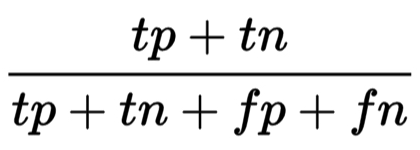
Precisão
- Precisão
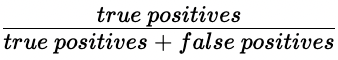
- Alta precisão = menor taxa de falsos positivos
- Alta precisão: não se prevê que muitas transações legítimas sejam fraudulentas
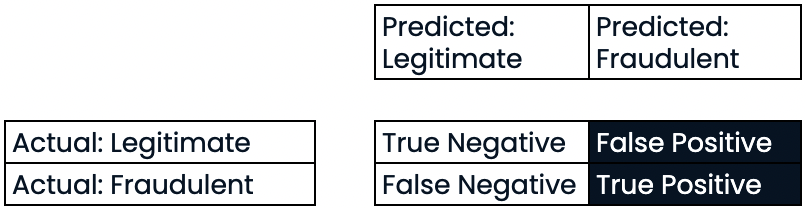
Sensibilidade
- Sensibilidade (recall)
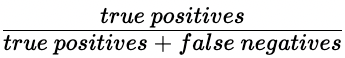
- Alta sensibilidade = menor taxa de falsos negativos
- Alta sensibilidade: previu corretamente a maioria das transações fraudulentas

