Avaliação de vários modelos
Aprendizado Supervisionado com o scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Modelos diferentes para problemas diferentes
Alguns princípios orientadores
- Tamanho do conjunto de dados
- Menos variáveis independentes = modelo mais simples, menor tempo de treinamento
- Alguns modelos requerem grandes quantidades de dados para um bom desempenho
- Interpretabilidade
- Alguns modelos são mais fáceis de explicar, o que pode ser importante para as partes interessadas
- A regressão linear tem alta capacidade de interpretação, pois podemos entender os coeficientes
- Flexibilidade
- Pode melhorar a precisão, fazendo menos suposições sobre os dados
- O KNN é um modelo mais flexível – não pressupõe nenhuma relação linear
Tudo está nas métricas
Desempenho do modelo de regressão:
- RMSE
- R-quadrado
Desempenho do modelo de classificação:
- Acurácia (accuracy)
- Matriz de confusão
- Precisão (precision), sensibilidade (recall), medida F (F1-score)
- Área sob a curva de COR (ROC AUC)
Treine vários modelos e avalie o desempenho sem modificações
Uma observação sobre o escalonamento
- Modelos afetados pelo escalonamento:
- KNN
- Regressão linear (inclusive ridge e lasso)
- Regressão logística
- Rede neural artificial
- É melhor fazer o escalonamento dos dados antes de avaliar os modelos
Avaliação de modelos de classificação
import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from sklearn.model_selection import cross_val_score, KFold, train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifierX = music.drop("genre", axis=1).values y = music["genre"].values X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)
Avaliação de modelos de classificação
models = {"Logistic Regression": LogisticRegression(), "KNN": KNeighborsClassifier(), "Decision Tree": DecisionTreeClassifier()} results = []for model in models.values():kf = KFold(n_splits=6, random_state=42, shuffle=True)cv_results = cross_val_score(model, X_train_scaled, y_train, cv=kf)results.append(cv_results)plt.boxplot(results, labels=models.keys()) plt.show()
Visualização de resultados
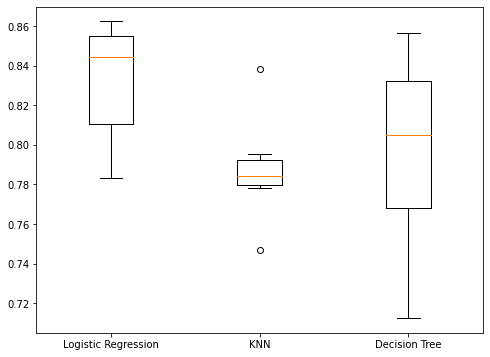
Desempenho do conjunto de teste
for name, model in models.items():model.fit(X_train_scaled, y_train)test_score = model.score(X_test_scaled, y_test)print("{} Test Set Accuracy: {}".format(name, test_score))
Logistic Regression Test Set Accuracy: 0.844
KNN Test Set Accuracy: 0.82
Decision Tree Test Set Accuracy: 0.832
Vamos praticar!
Aprendizado Supervisionado com o scikit-learn

