Validação cruzada
Aprendizado Supervisionado com scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Noções básicas de validação cruzada

Noções básicas de validação cruzada

Noções básicas de validação cruzada

Noções básicas de validação cruzada
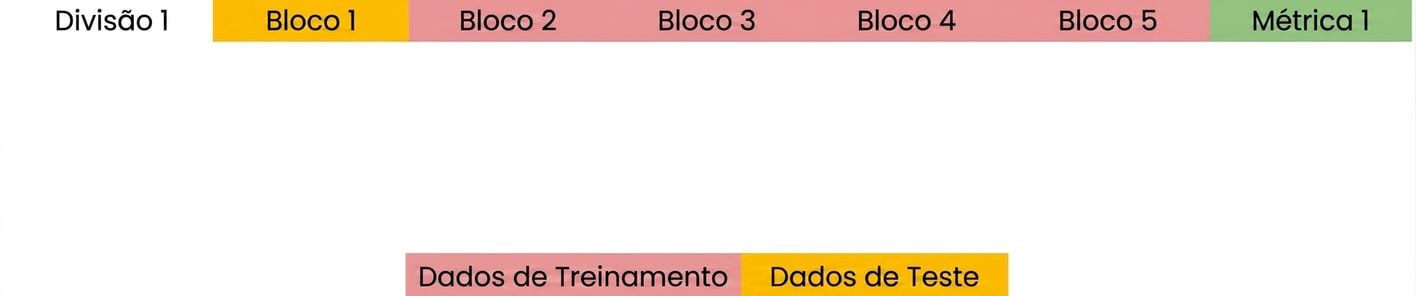
Noções básicas de validação cruzada

Noções básicas de validação cruzada

Noções básicas de validação cruzada

Noções básicas de validação cruzada
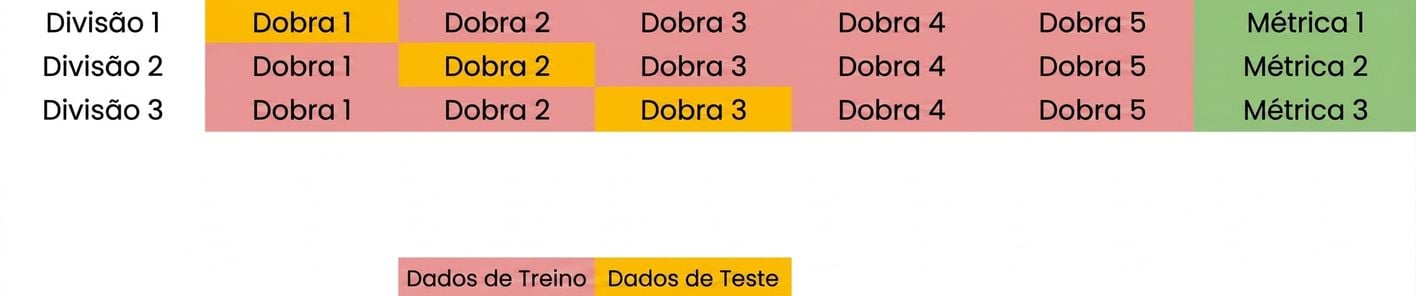
Noções básicas de validação cruzada
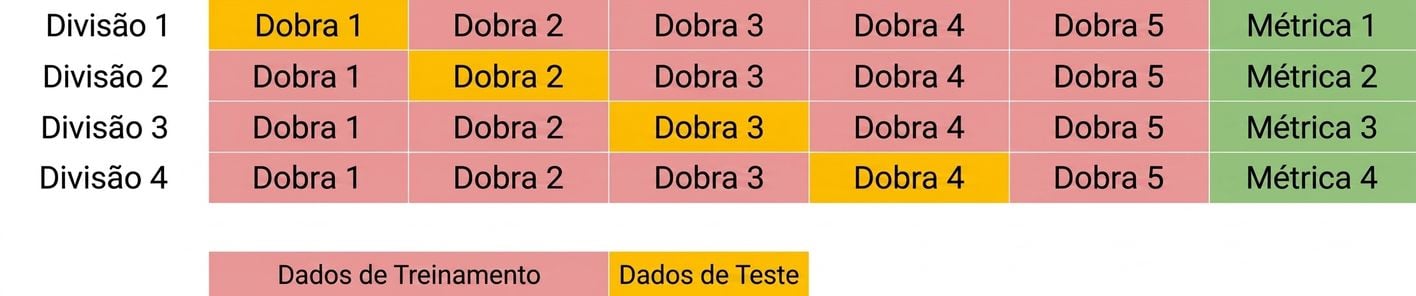
Noções básicas de validação cruzada


