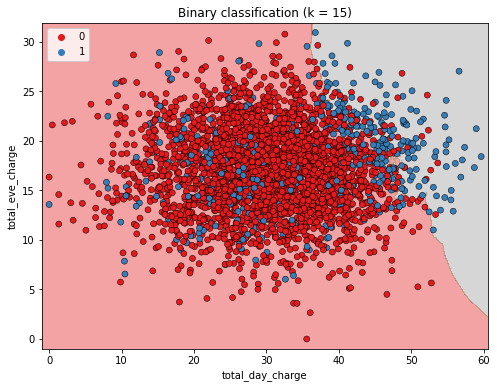
O desafio da classificação
Aprendizado Supervisionado com o scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
k vizinhos mais próximos
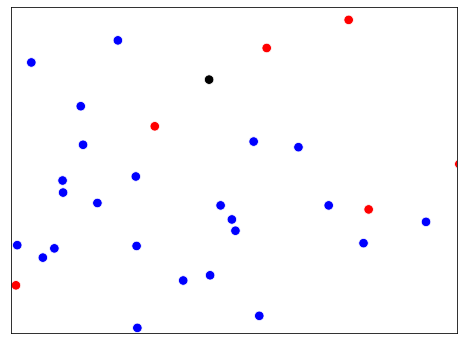
k vizinhos mais próximos
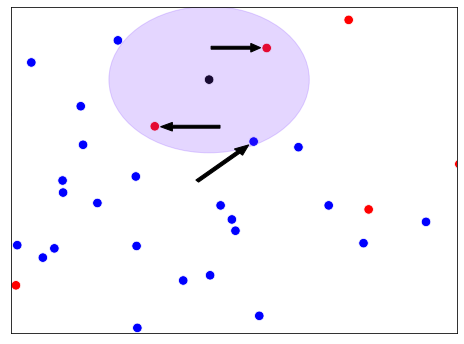
k vizinhos mais próximos
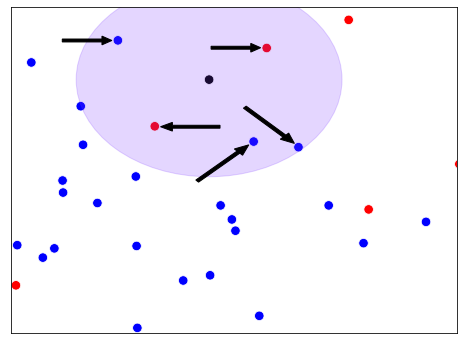
Compreensão intuitiva do KNN
Compreensão intuitiva do KNN