Pré-processamento de dados
Aprendizado Supervisionado com o scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Variáveis binárias (dummies)

Variáveis binárias (dummies)
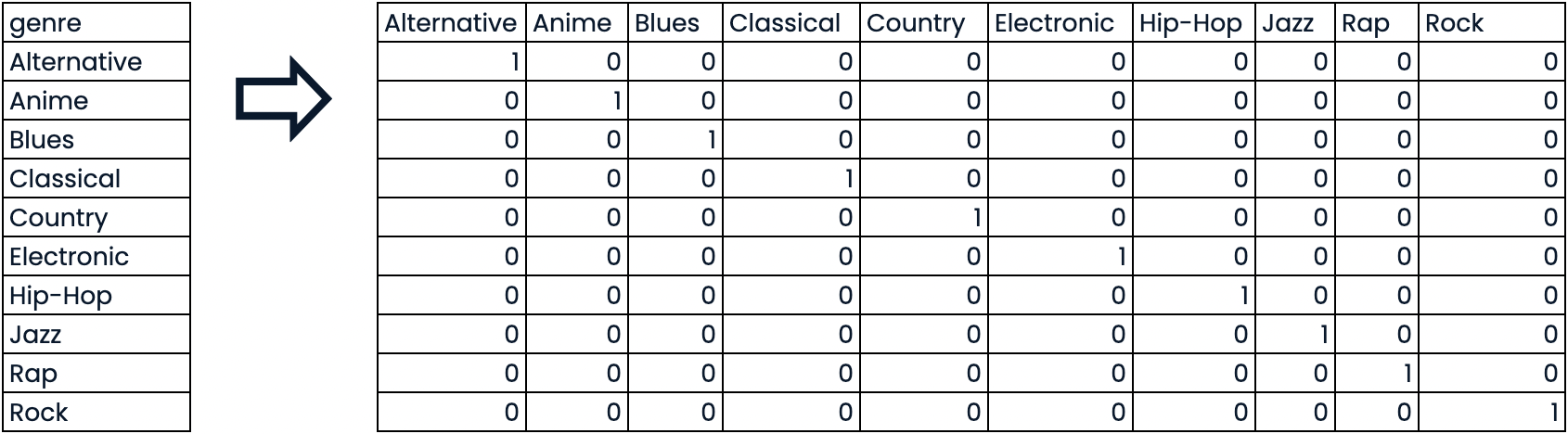
Variáveis binárias (dummies)
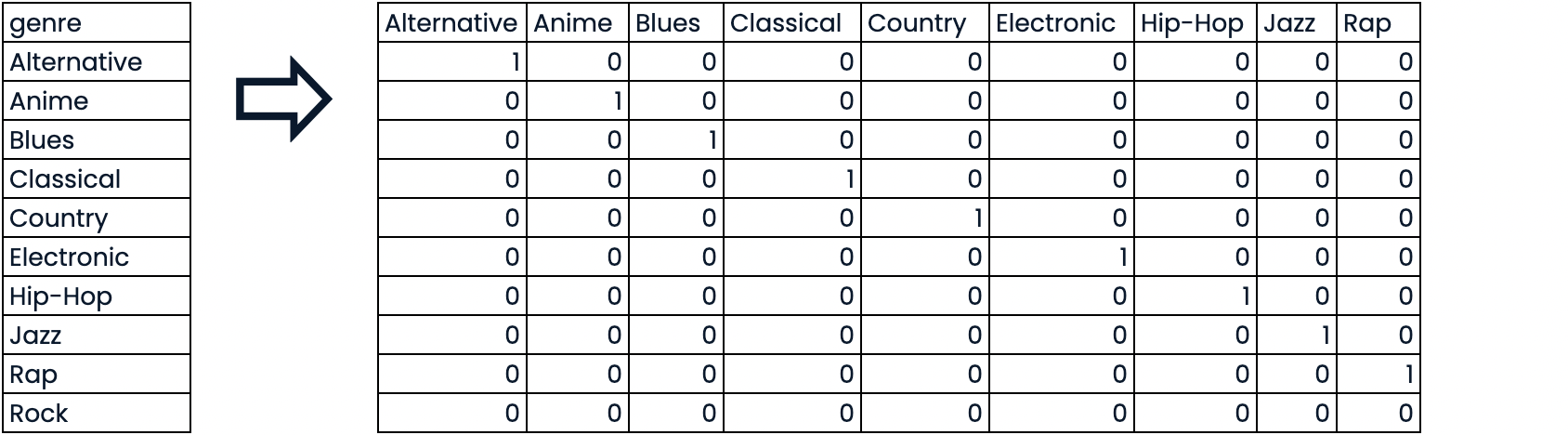
AED com variável independente categórica