Ajuste de hiperparâmetros
Aprendizado Supervisionado com o scikit-learn

George Boorman
Core Curriculum Manager
Validação cruzada com pesquisa em grade
Validação cruzada com pesquisa em grade
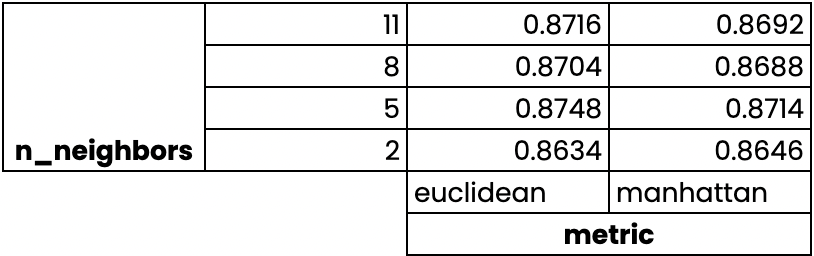
Validação cruzada com pesquisa em grade
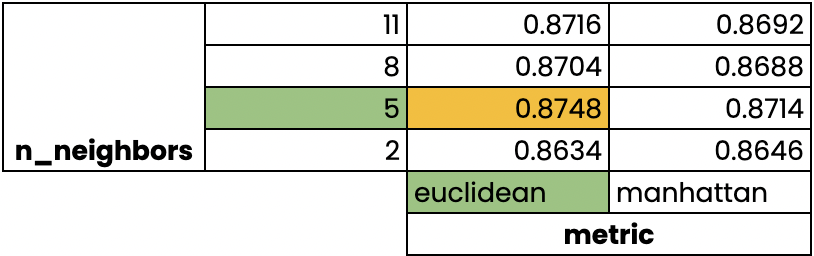
Aprendizado Supervisionado com o scikit-learn
George Boorman
Core Curriculum Manager

