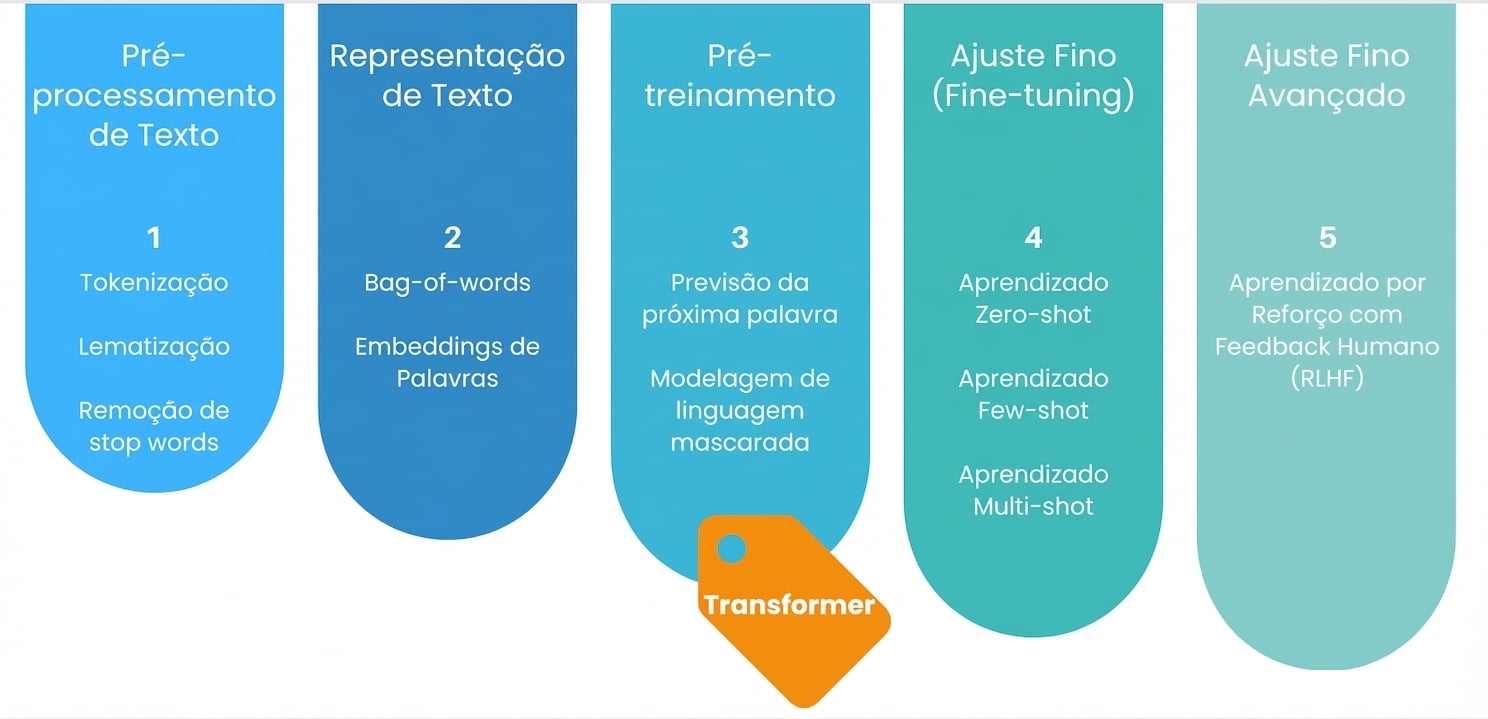
Ajuste fino avançado
Conceitos de Grandes Modelos de Linguagem (LLMs)

Vidhi Chugh
AI strategist and ethicist
Onde estamos?
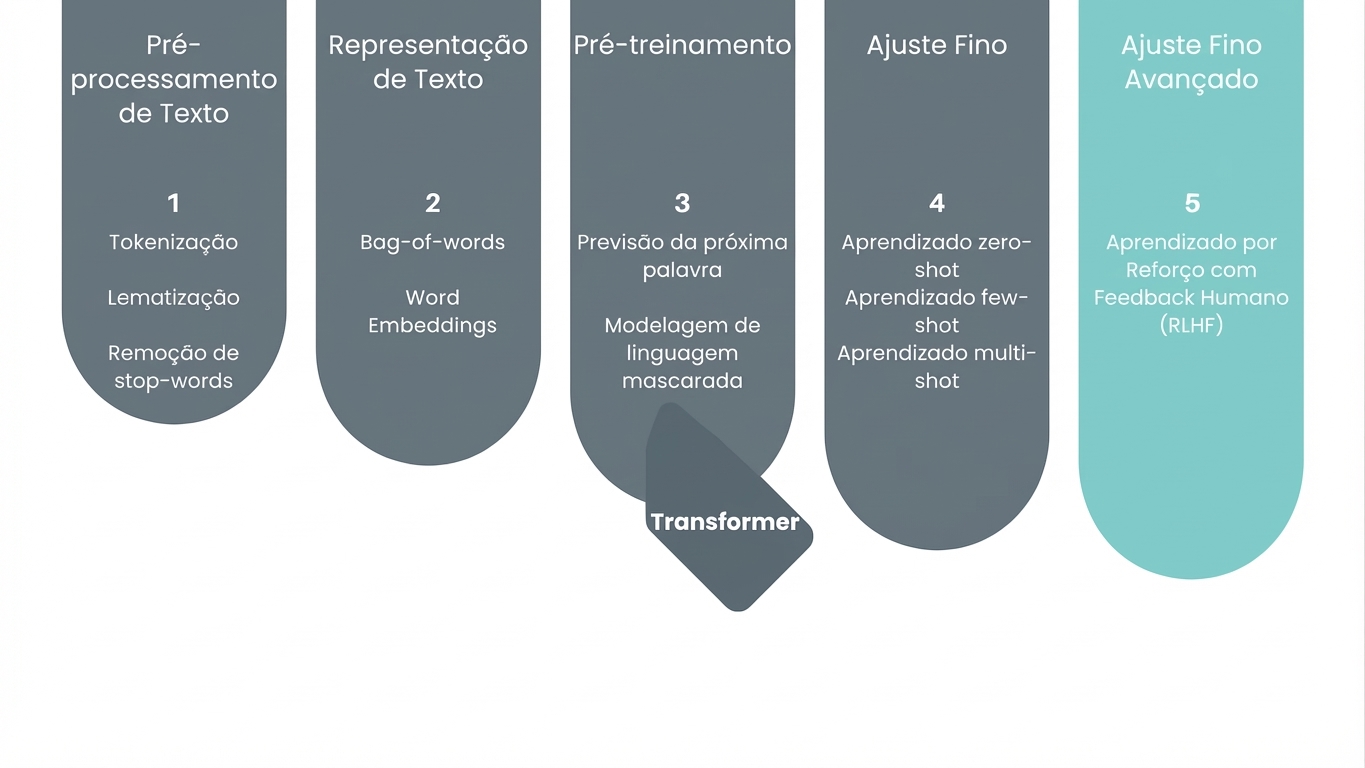
Aprendizado por reforço com feedback humano

Pré-treinamento

1 Freepik
Ajuste fino

Mas por que usar o RLHF?

O RLHF de forma simples

Entra o especialista humano

Hora do feedback
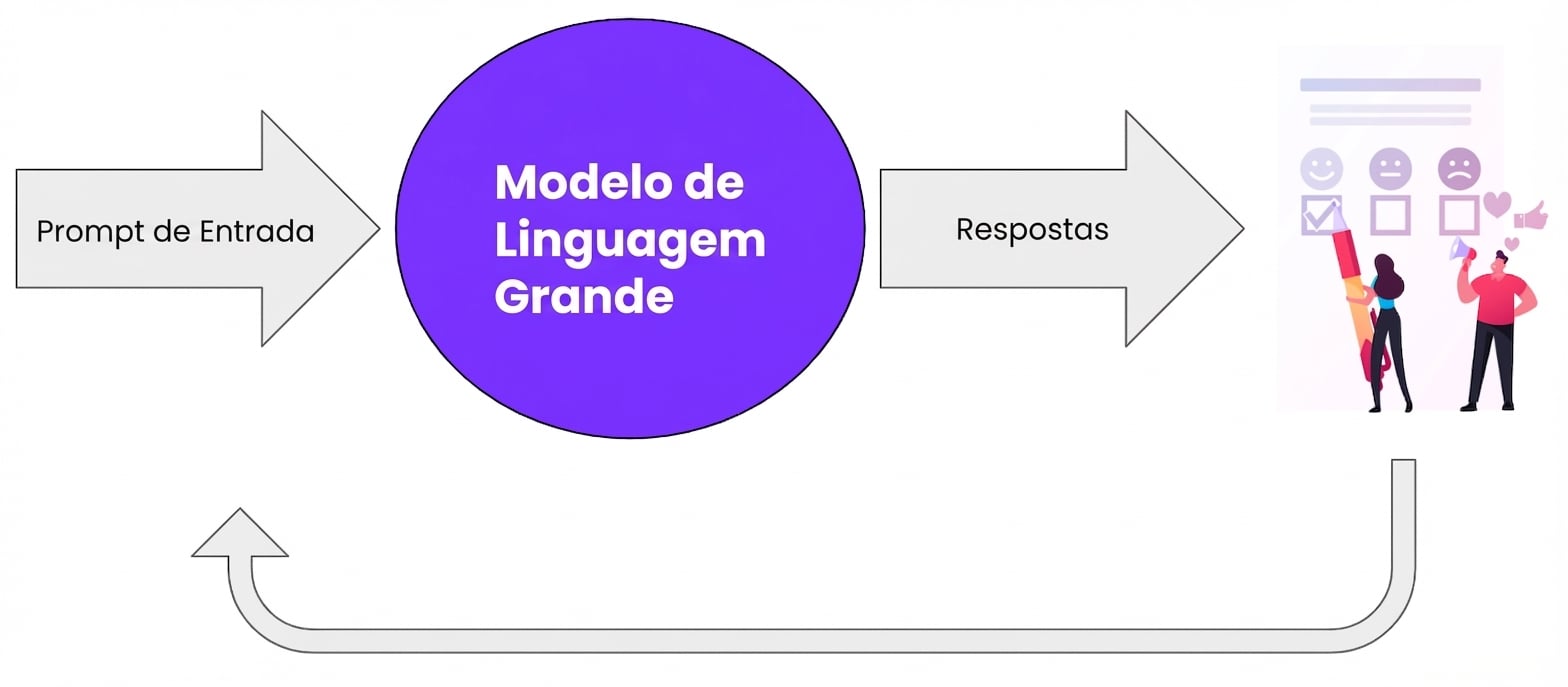
Conclusão do LLM