Como trabalhar com dados numéricos
Análise Exploratória de Dados em Python

George Boorman
Curriculum Manager, DataCamp
Converter strings em números

Adicionar estatísticas resumidas a um DataFrame

salaries["std_dev"] = salaries.groupby("Experience")
Adicionar estatísticas resumidas a um DataFrame
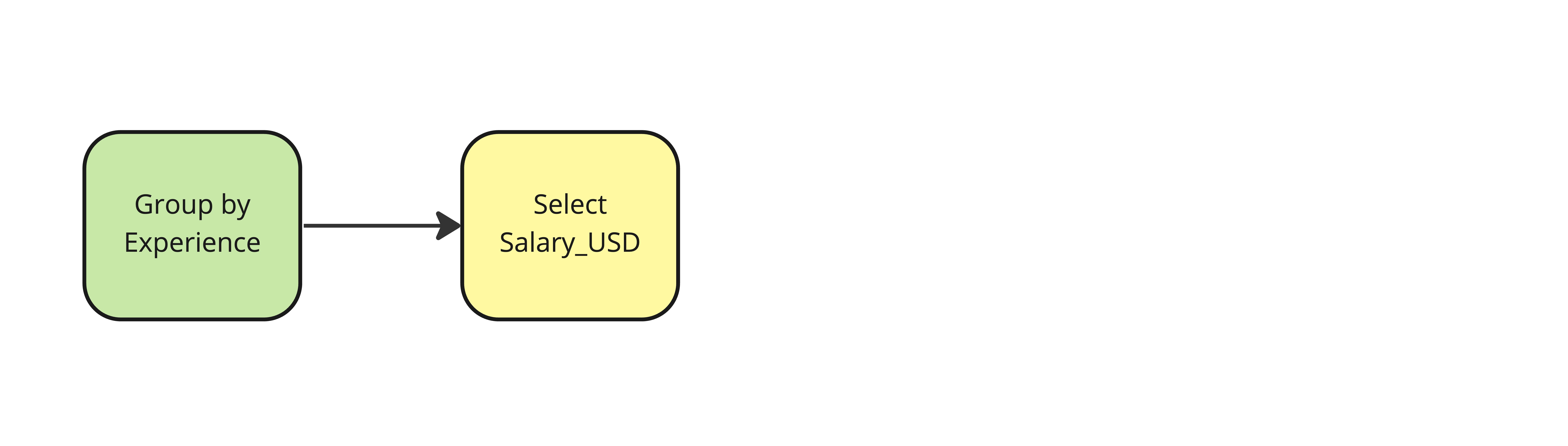
salaries["std_dev"] = salaries.groupby("Experience")["Salary_USD"]
Adicionar estatísticas resumidas a um DataFrame
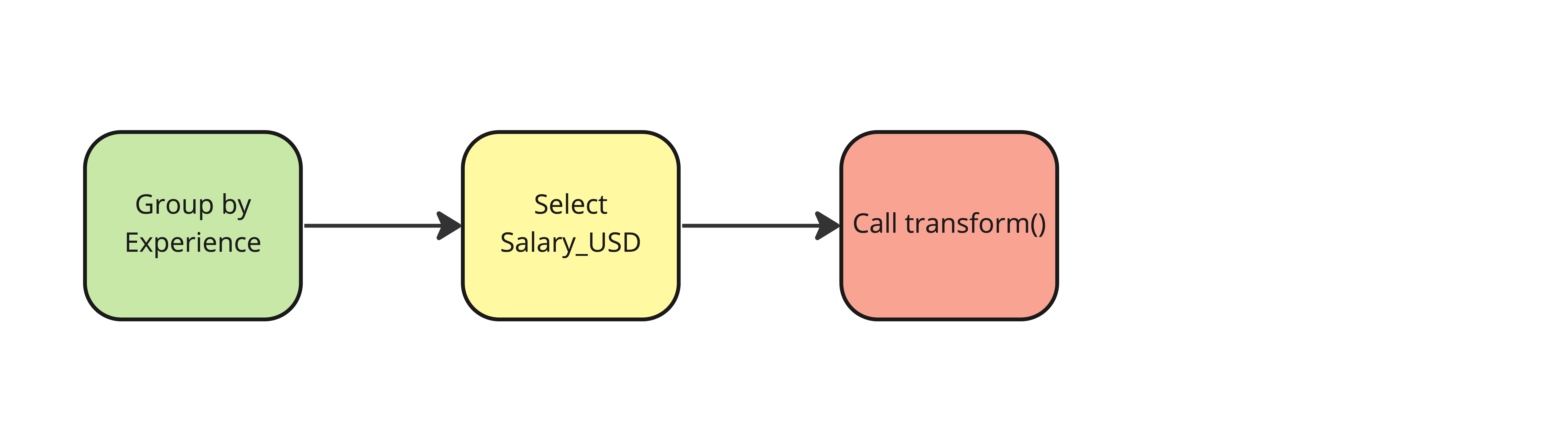
salaries["std_dev"] = salaries.groupby("Experience")["Salary_USD"].transform(
Adicionar estatísticas resumidas a um DataFrame
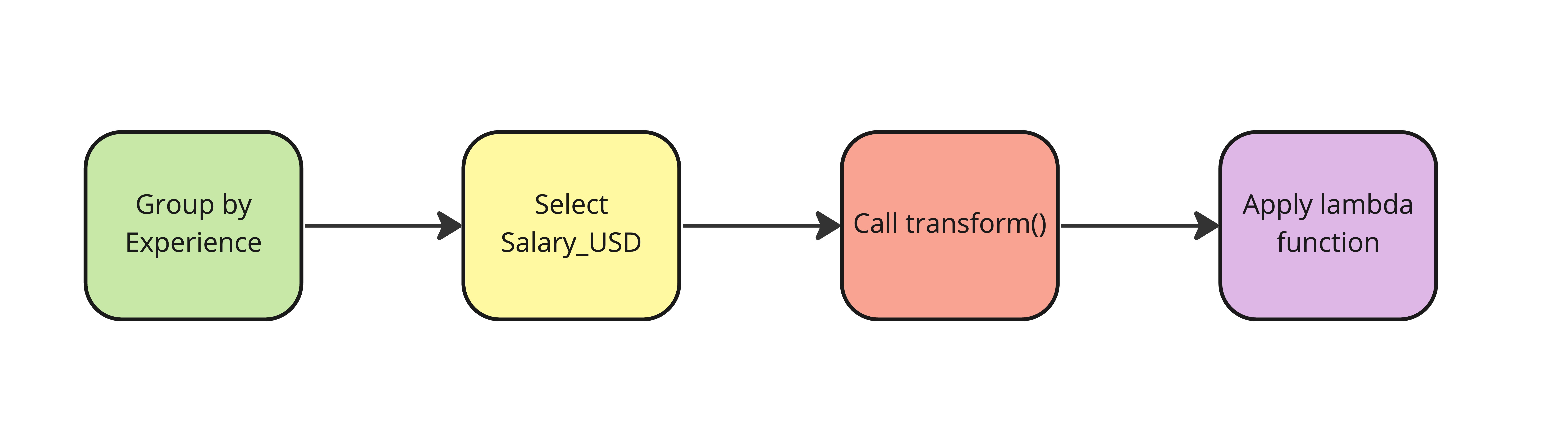
salaries["std_dev"] = salaries.groupby("Experience")["Salary_USD"].transform(lambda x: x.std())

