Parabéns
Análise Exploratória de Dados em Python

George Boorman
Curriculum Manager, DataCamp
Inspeção e validação
Analisar dados categóricos
salaries["Job_Category"] = np.select(conditions,
job_categories,
default="Other")
Aplicar funções lambda
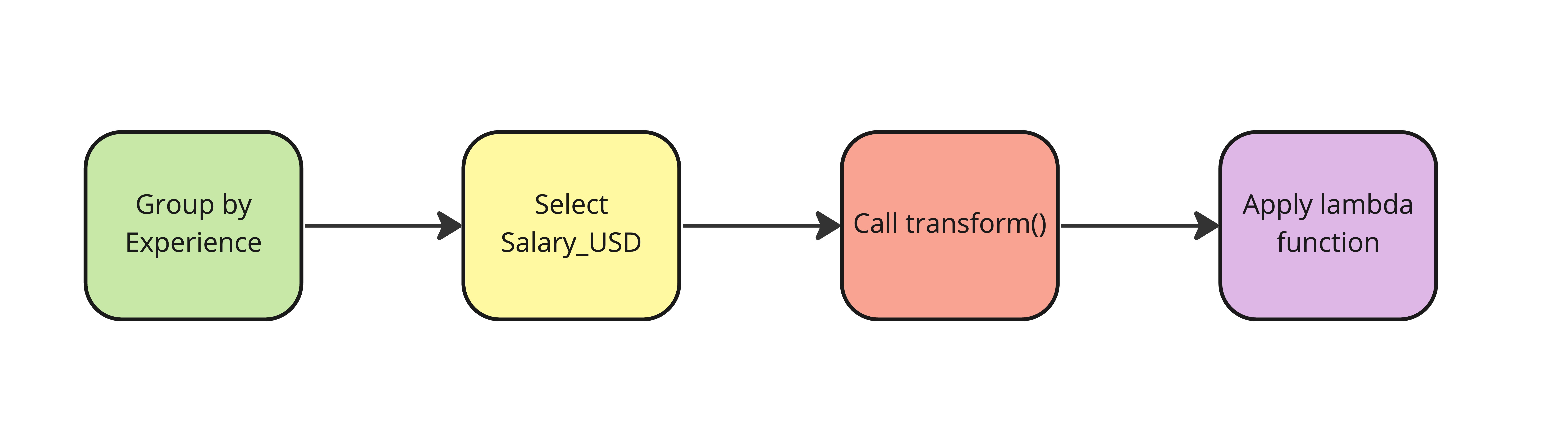
salaries["std_dev"] = salaries.groupby("Experience")["Salary_USD"].transform(lambda x: x.std())
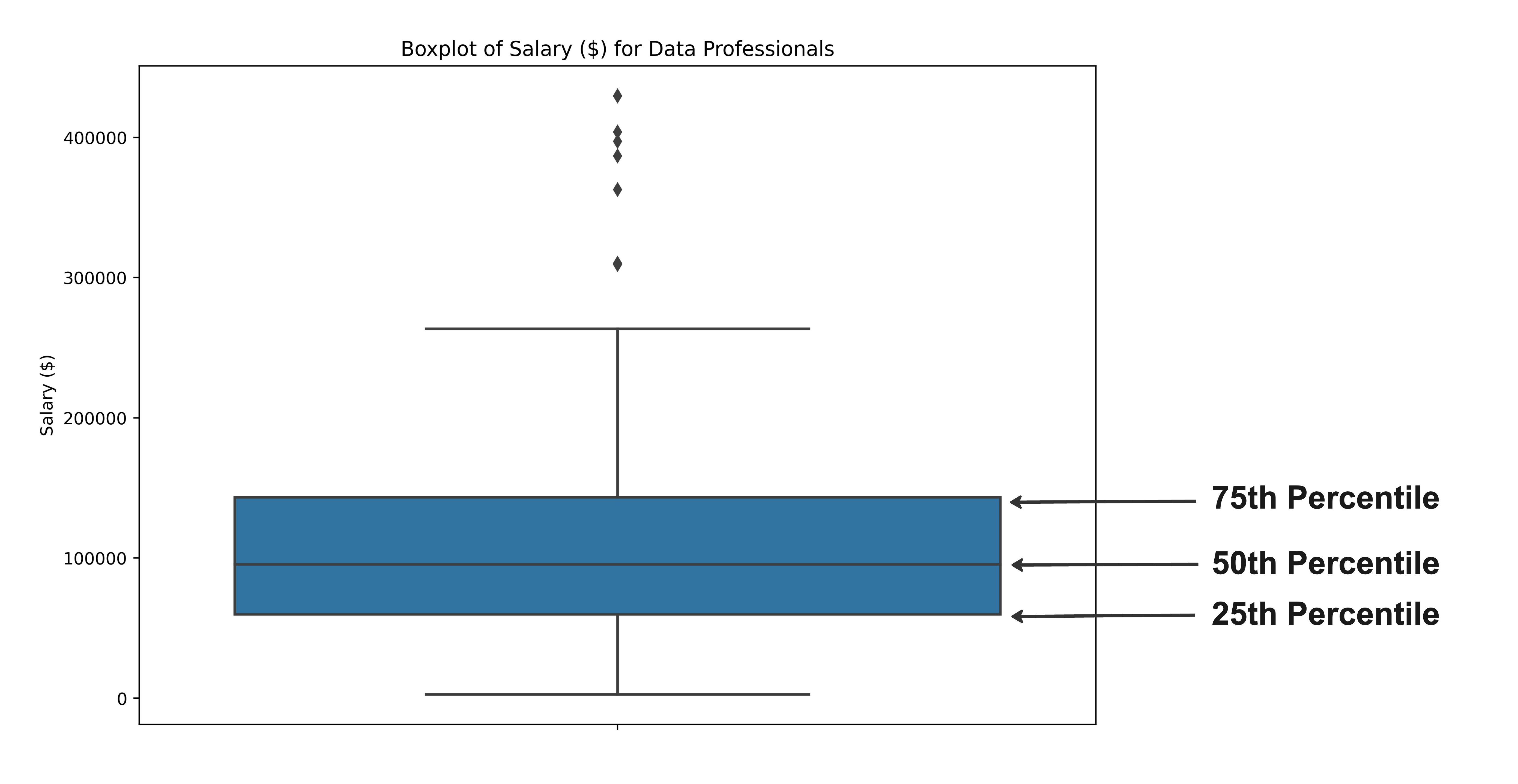
Lidar com discrepâncias
sns.boxplot(data=salaries,
y="Salary_USD")
plt.show()
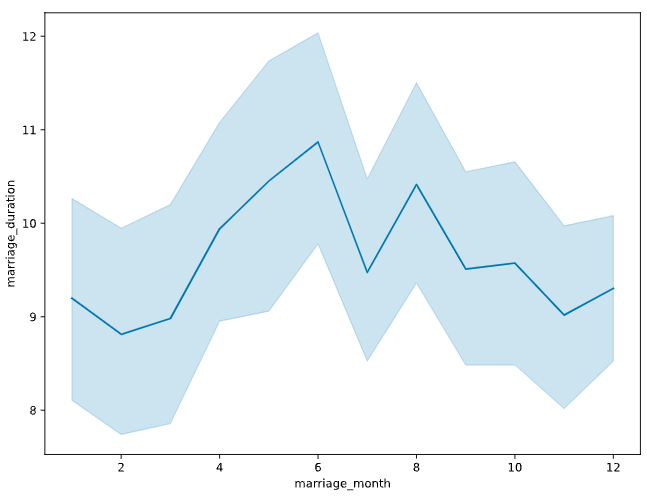
Padrões ao longo do tempo
sns.lineplot(data=divorce, x="marriage_month", y="marriage_duration")
plt.show()
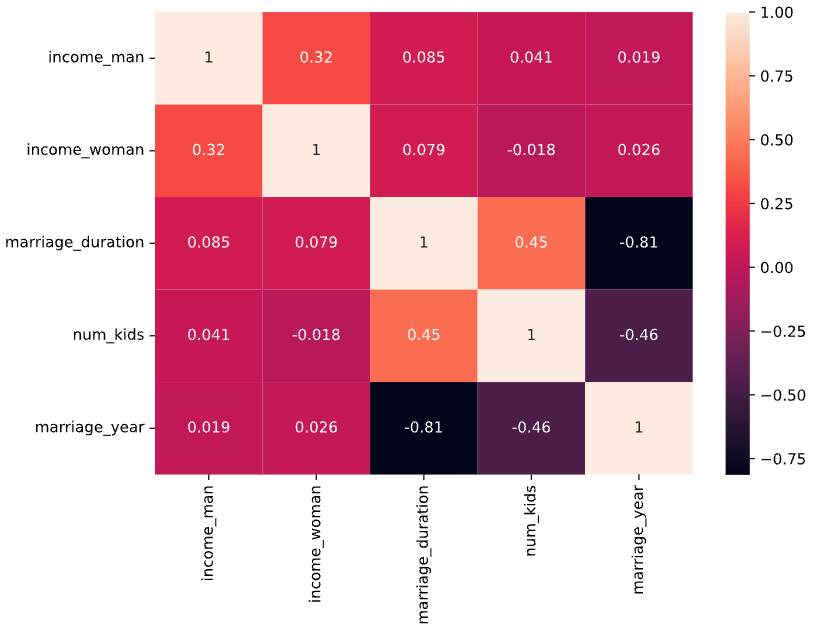
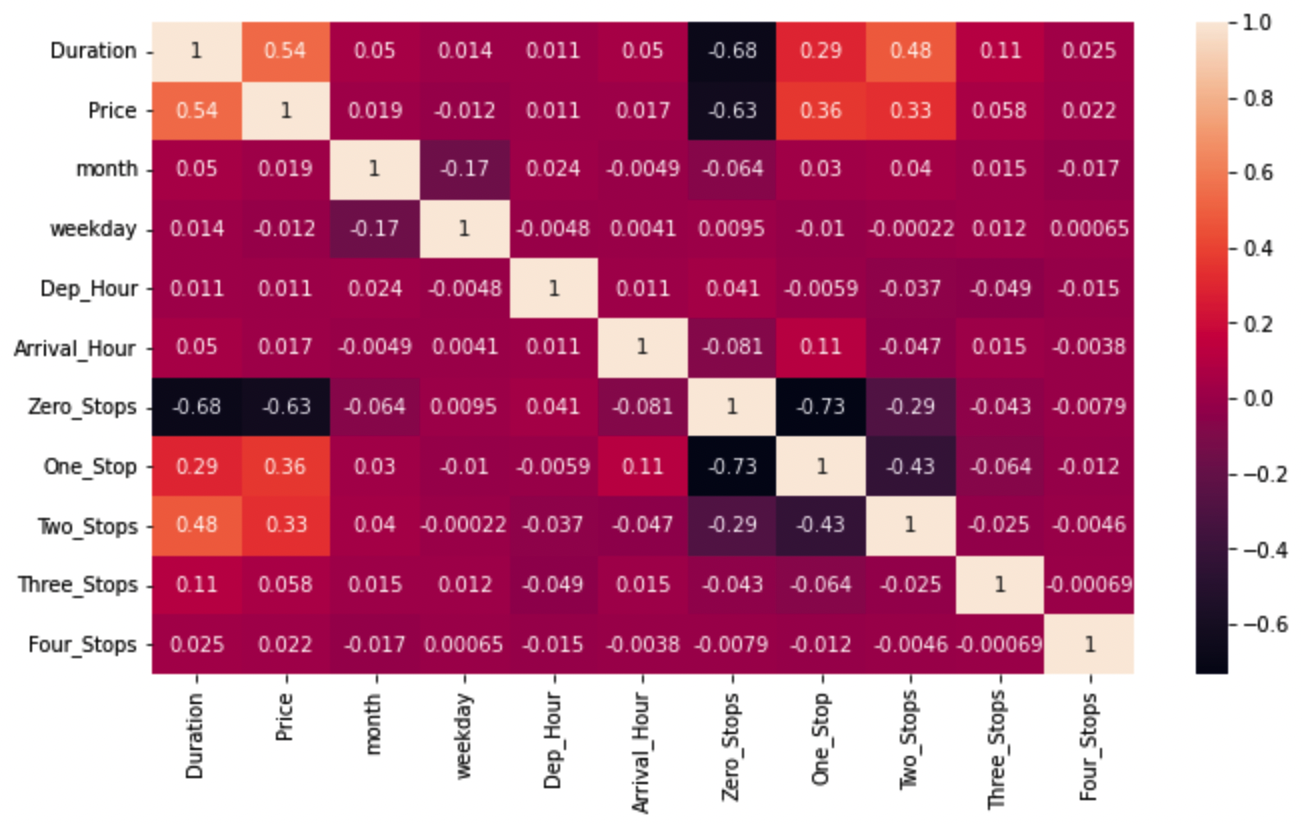
Correlação
sns.heatmap(divorce.corr(numeric_only=True), annot=True)
plt.show()
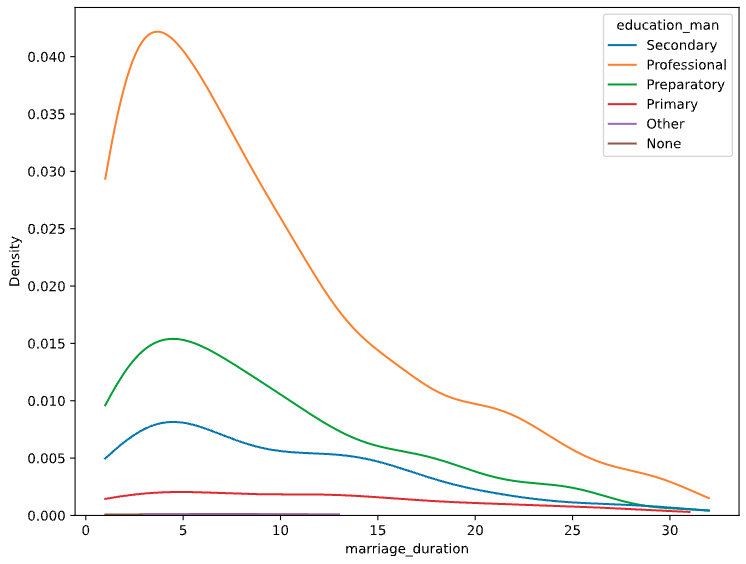
Distribuições
sns.kdeplot(data=divorce, x="marriage_duration", hue="education_man", cut=0)
plt.show()
pd.cut()
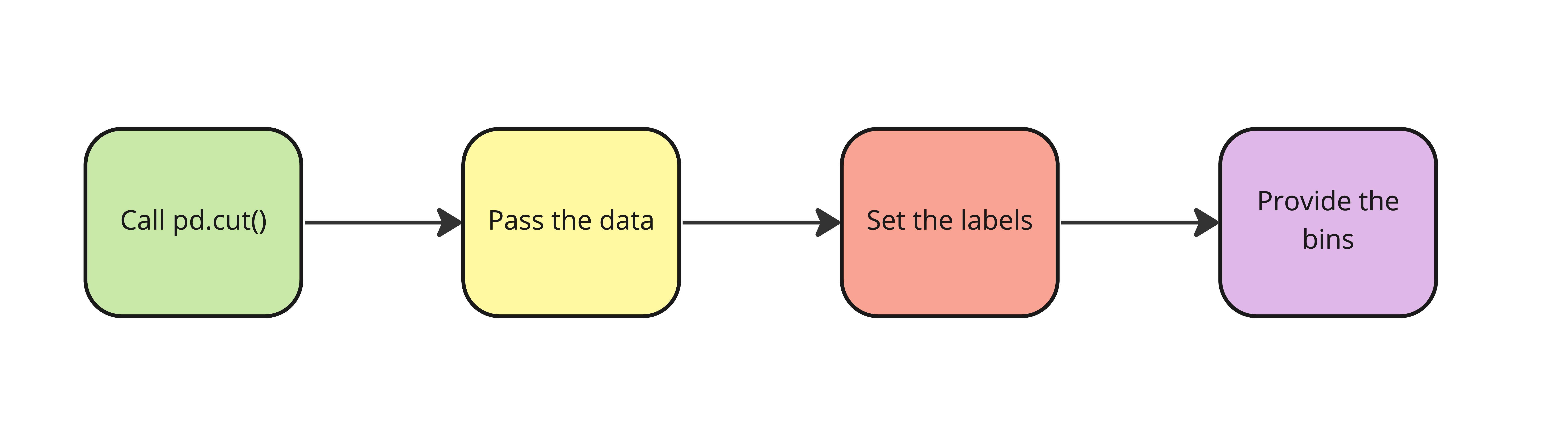
planes["Price_Category"] = pd.cut(planes["Price"],
labels=labels,
bins=bins)
Data snooping
Elaboração de hipóteses
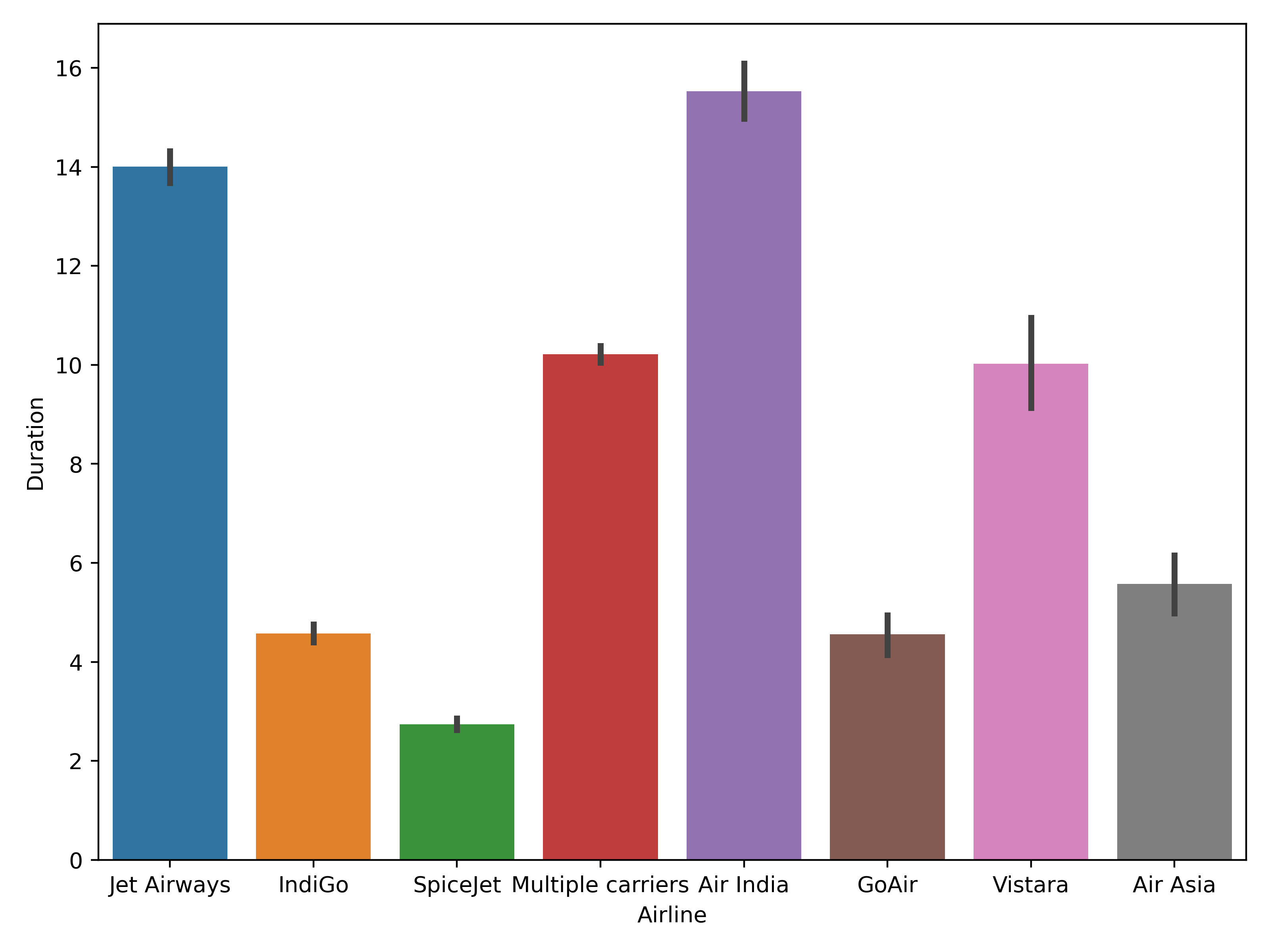
sns.barplot(data=planes, x="Airline", y="Duration")
plt.show()