Como lidar com dados ausentes
Análise Exploratória de Dados em Python

George Boorman
Curriculum Manager, DataCamp
Por que dados ausentes são um problema?
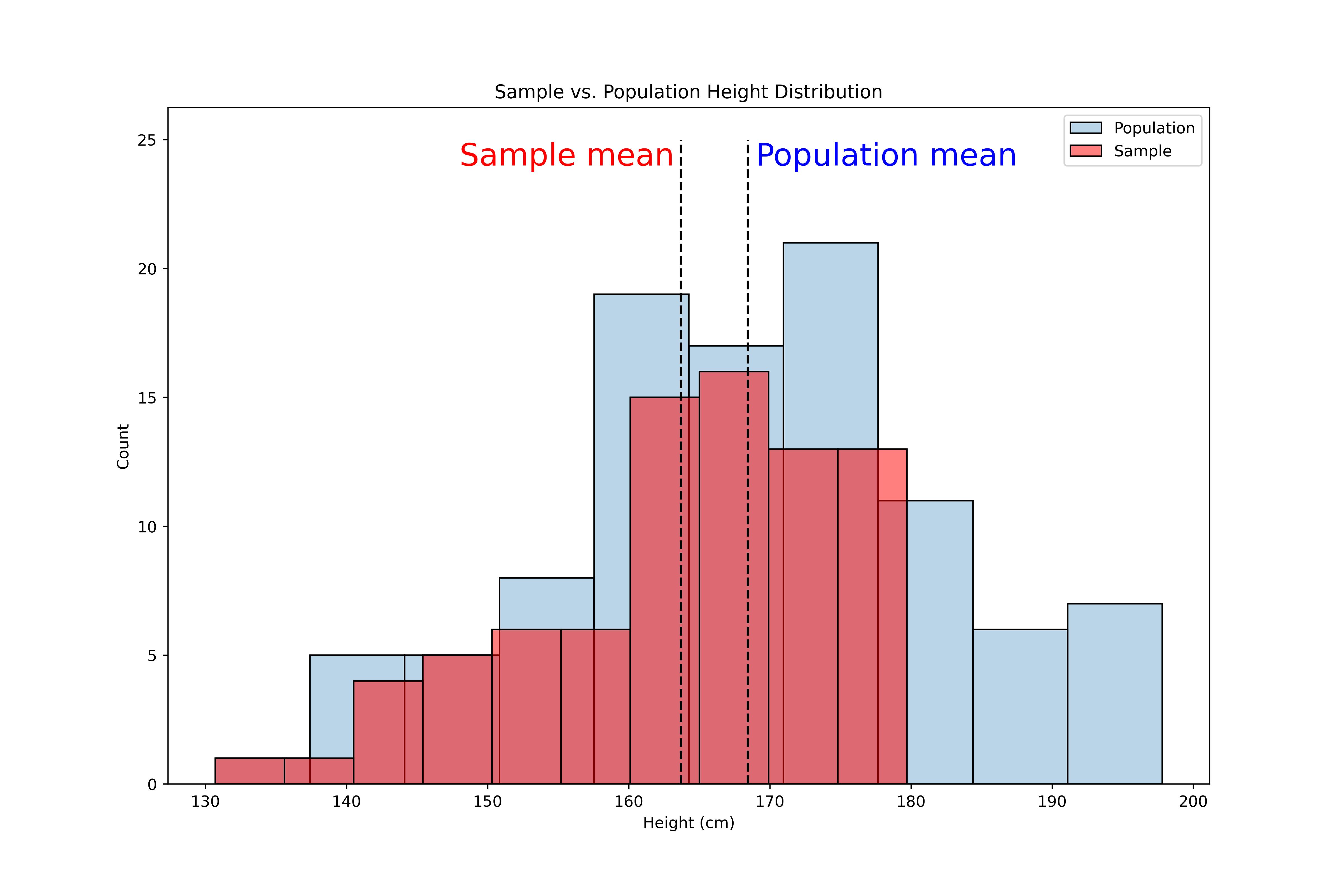
Salário por nível de experiência
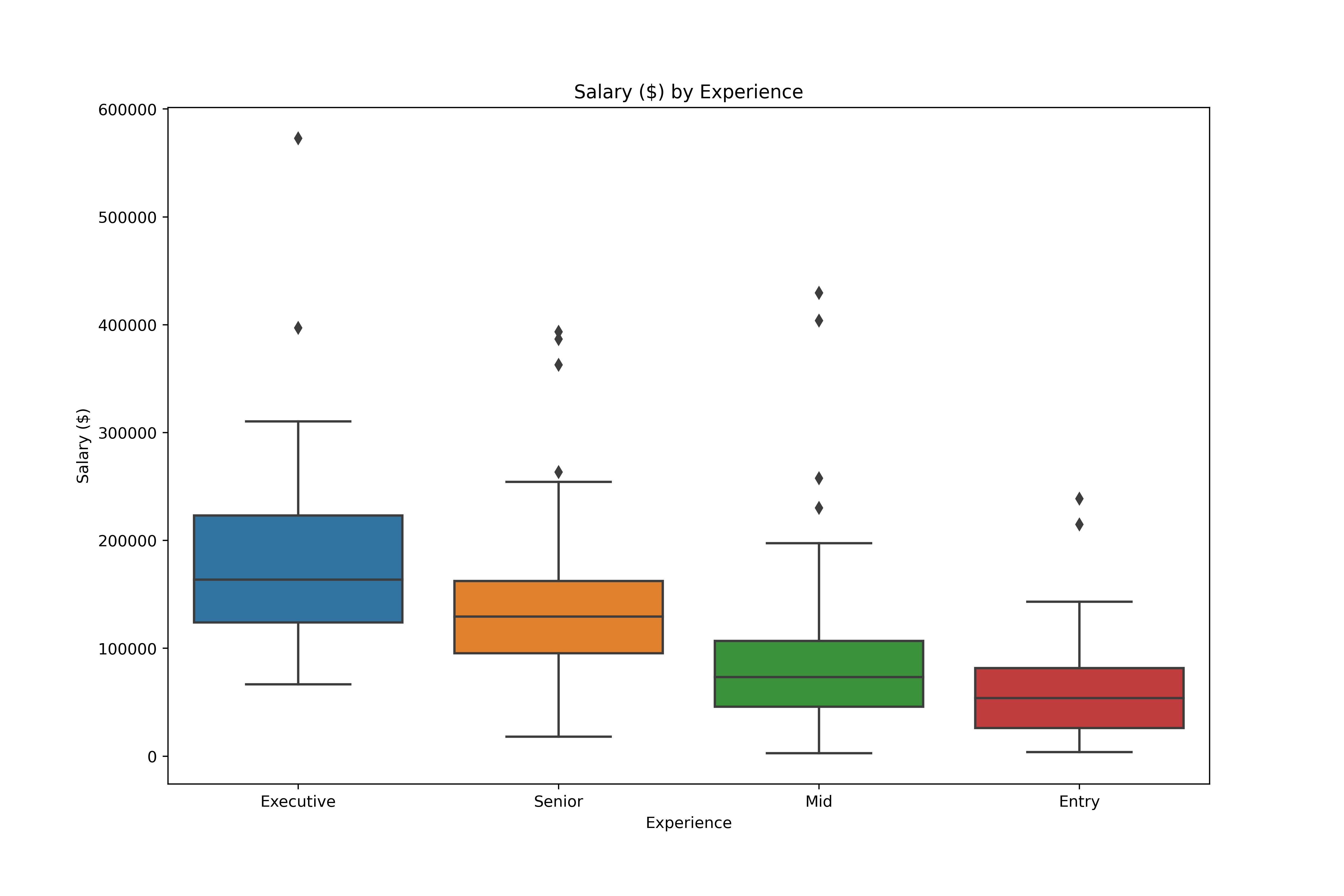
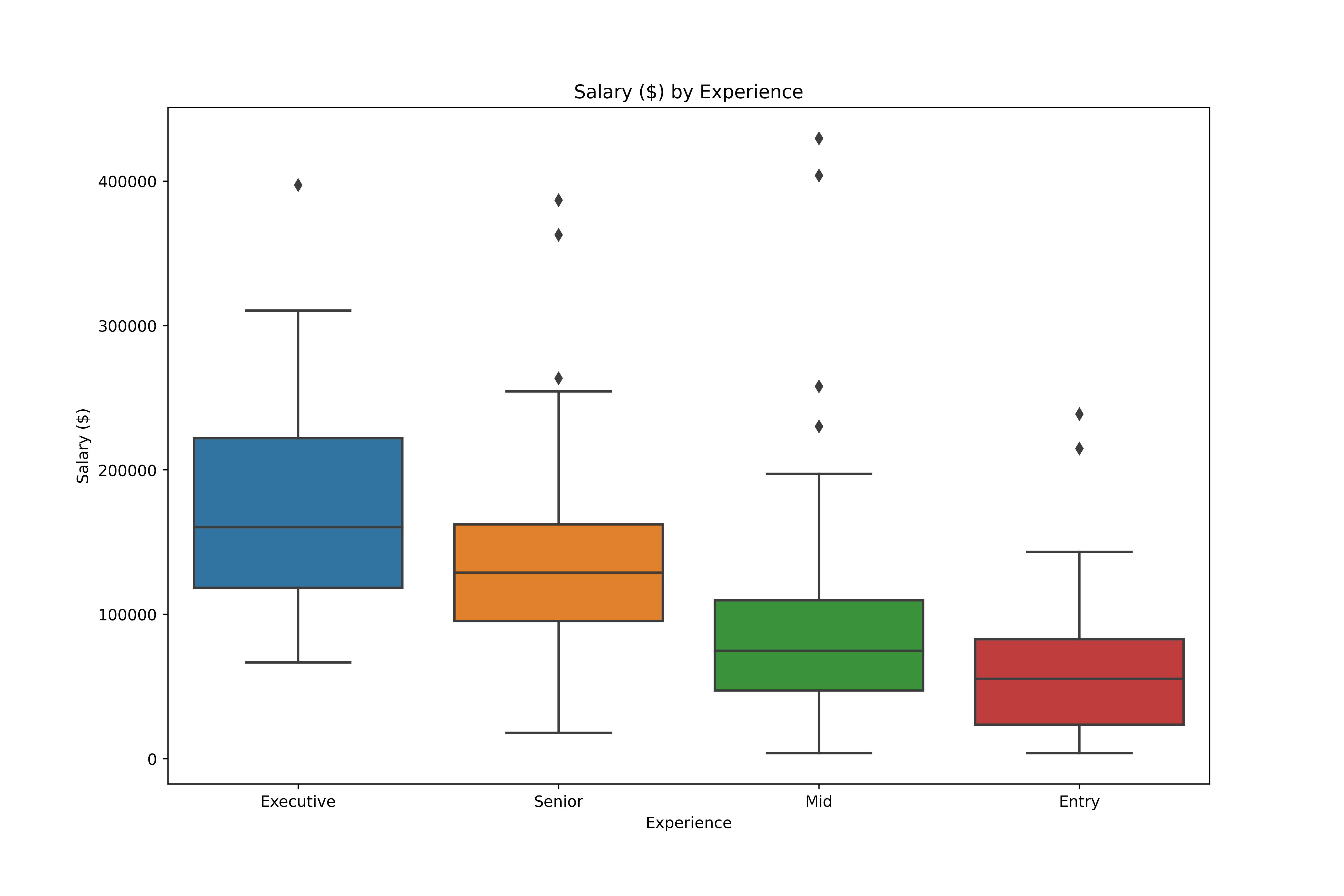
Análise Exploratória de Dados em Python
George Boorman
Curriculum Manager, DataCamp

