Métricas para tarefas de linguagem: ROUGE, METEOR, EM
Introdução a LLMs em Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Tarefas e métricas de LLM
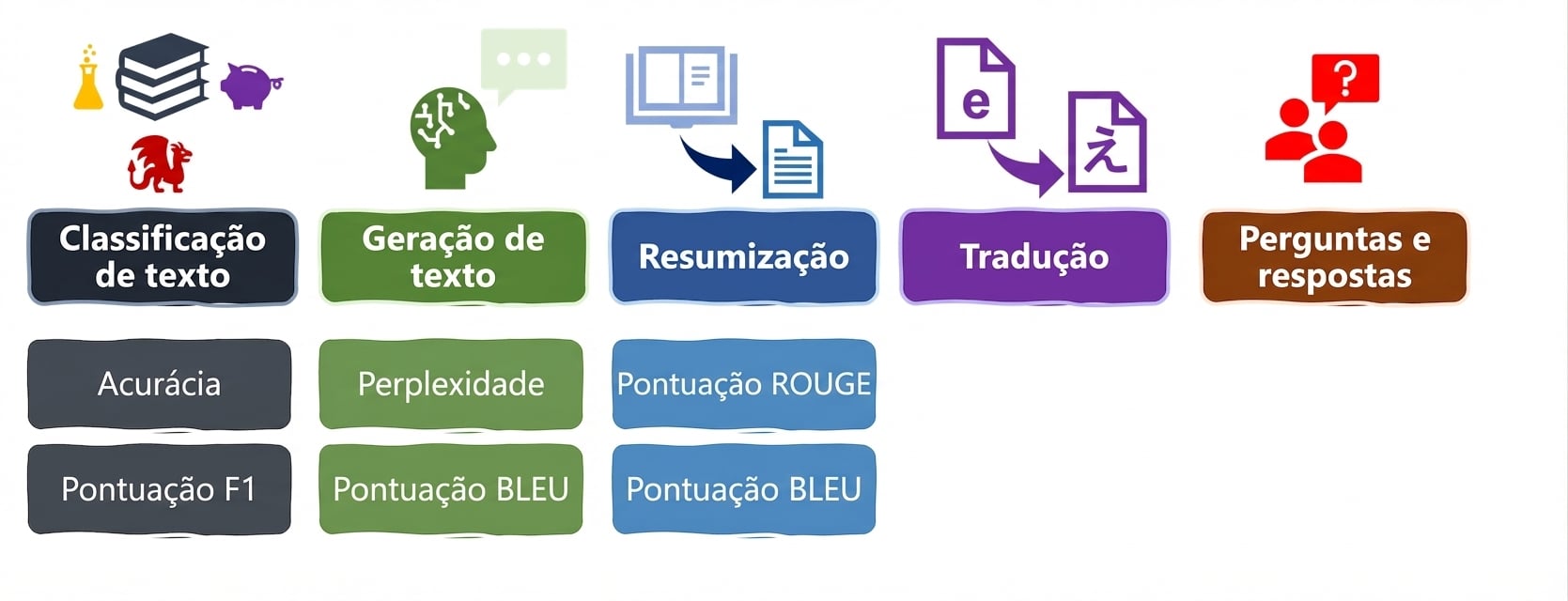
Tarefas e métricas de LLM
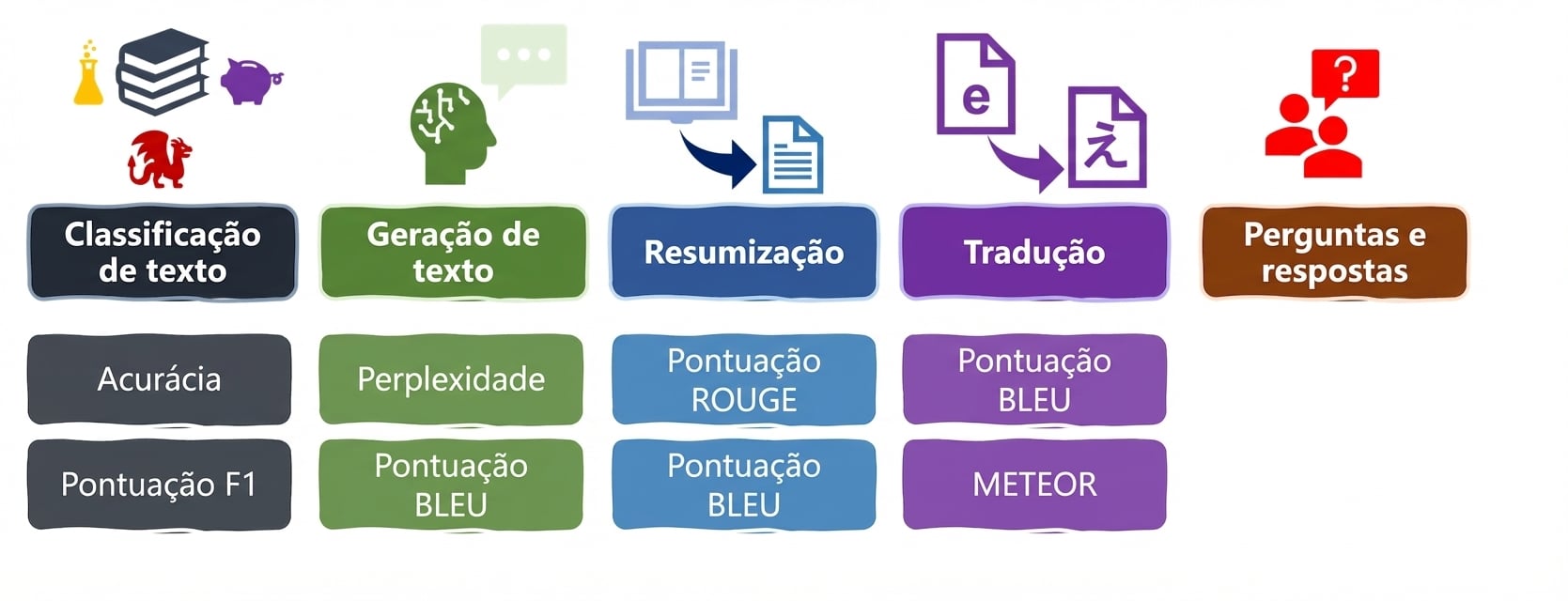
Tarefas e métricas de LLM
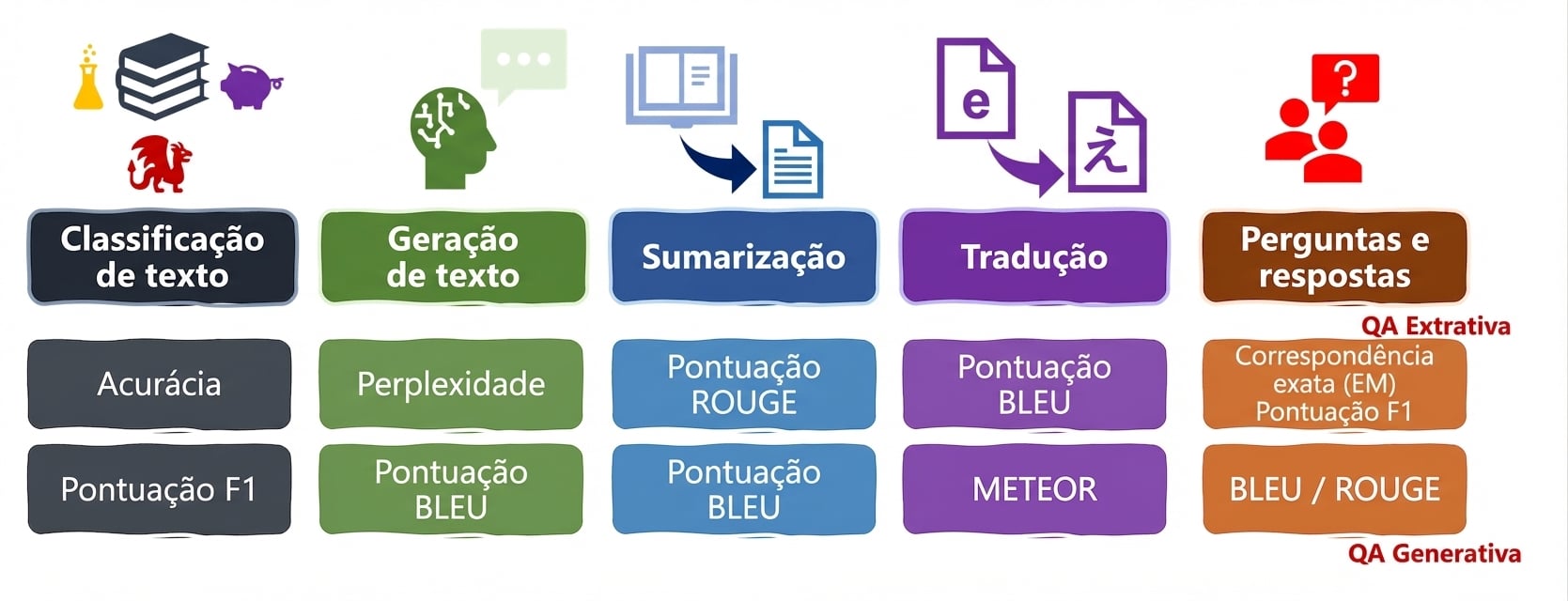
ROUGE
- ROUGE: similaridade entre um resumo gerado e os de referência
- Olha n-grams e sobreposição
predictions:saídas do LLMreferences: resumos humanos

Perguntas e respostas

