Protegendo LLMs
Introdução a LLMs em Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Desafios de LLMs
Suporte multilíngue: diversidade de idiomas, disponibilidade de recursos, adaptabilidade

Dilema LLMs abertos vs fechados: colaboração vs uso responsável

Escalabilidade do modelo: capacidade de representação, demanda computacional, requisitos de treino

Vieses: dados de treino enviesados, compreensão e geração injustas

1 Ícone feito por Freepik (freepik.com)
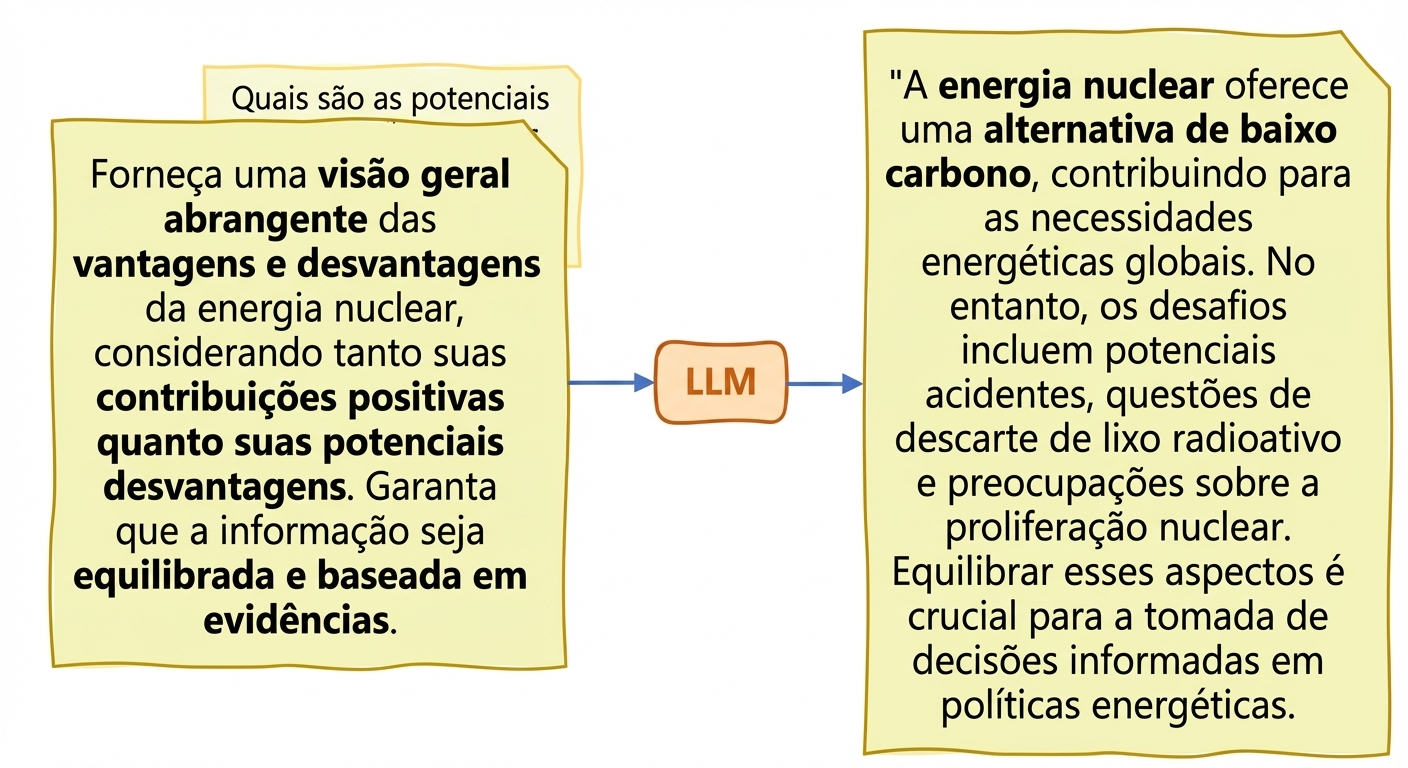
Veracidade e alucinações
- Alucinações: o texto gerado traz informações falsas ou sem sentido como se fossem corretas
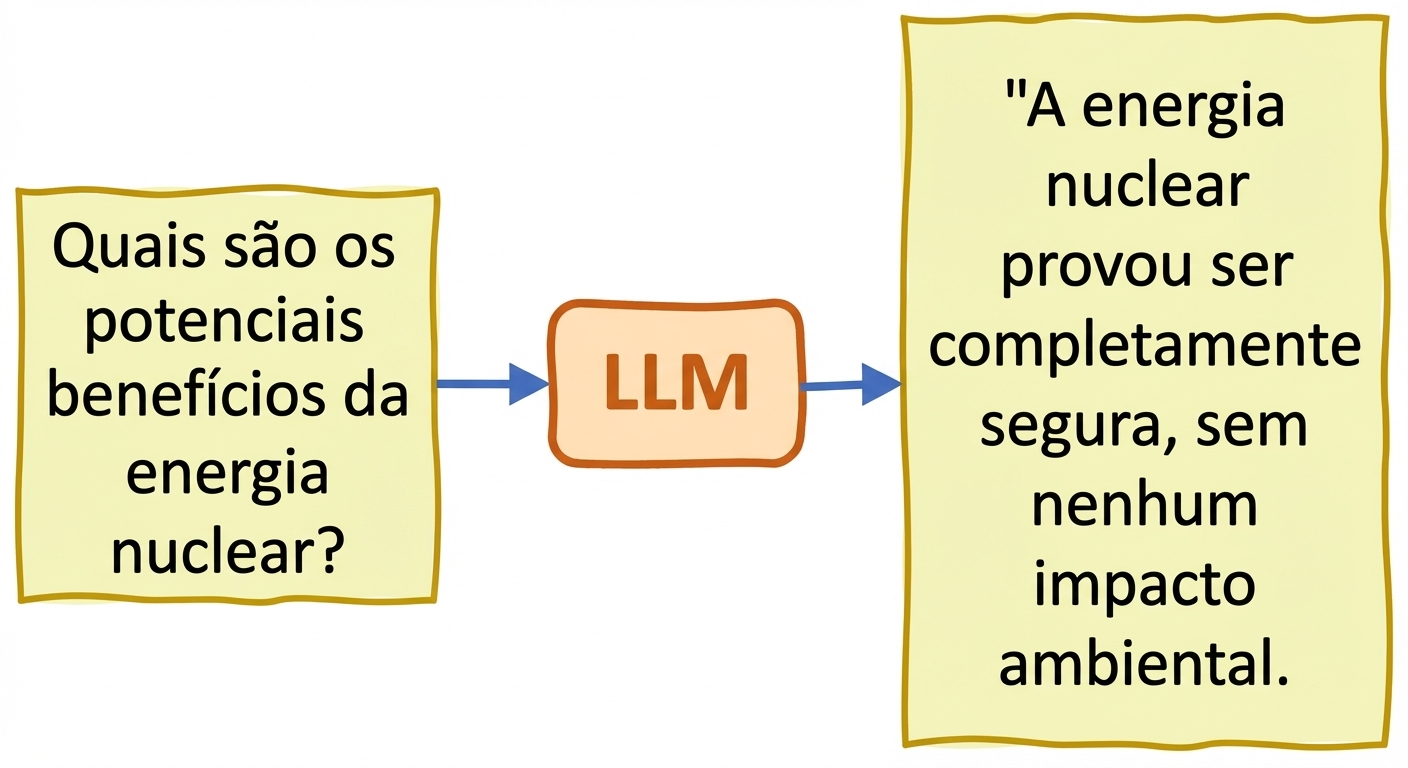
Estratégias para reduzir alucinações em LLMs:
- Exposição a dados de treino diversos e representativos
- Auditorias de viés nas saídas + técnicas de mitigação
- Fine-tuning para casos de uso específicos em apps sensíveis
- Engenharia de prompts: elaborar e refinar prompts com cuidado
Veracidade e alucinações
- Alucinações: o texto gerado traz informações falsas ou sem sentido como se fossem corretas