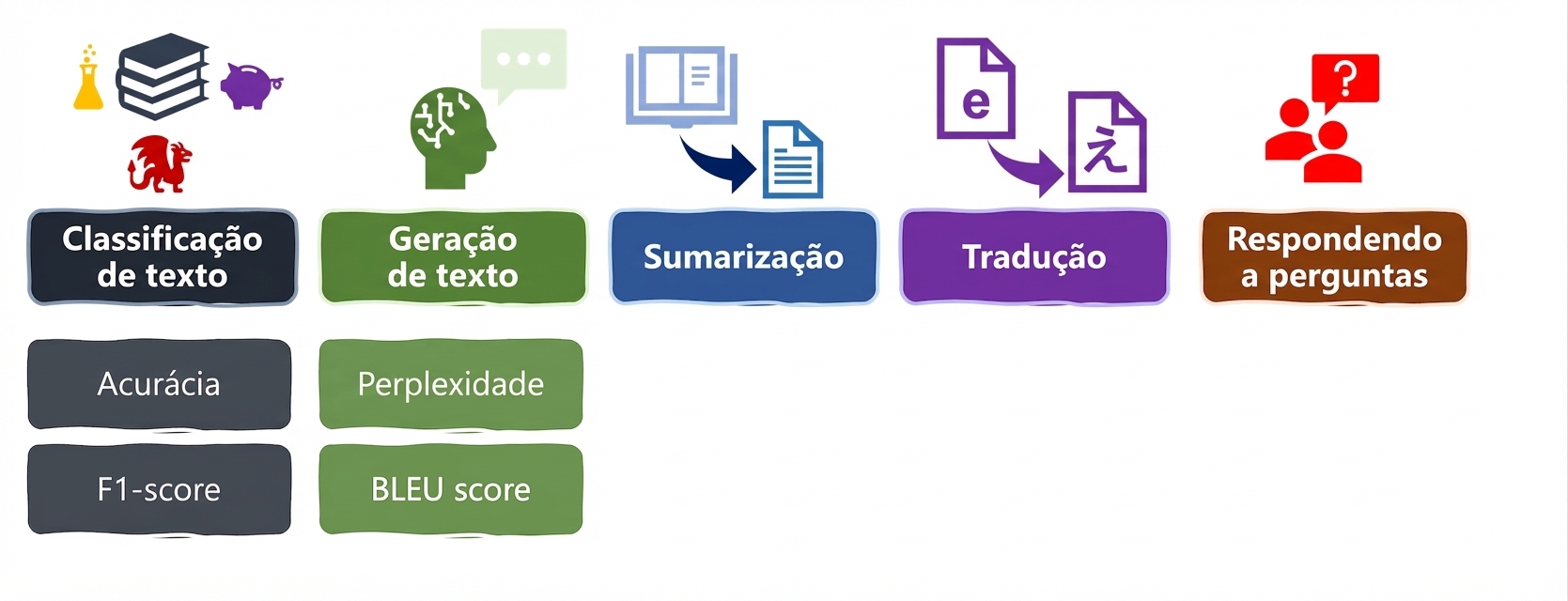
Métricas para tarefas de linguagem: perplexidade e BLEU
Introdução a LLMs em Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Tarefas e métricas em LLMs
Introdução a LLMs em Python
Jasmin Ludolf
Senior Data Science Content Developer, DataCamp

