Pruebas de hipótesis y puntuaciones z
Pruebas de hipótesis en Python

James Chapman
Curriculum Manager, DataCamp
Pruebas A/B

1 Crédito de la imagen: "Electronic Arts" por majaX1 CC BY-NC-SA 2.0
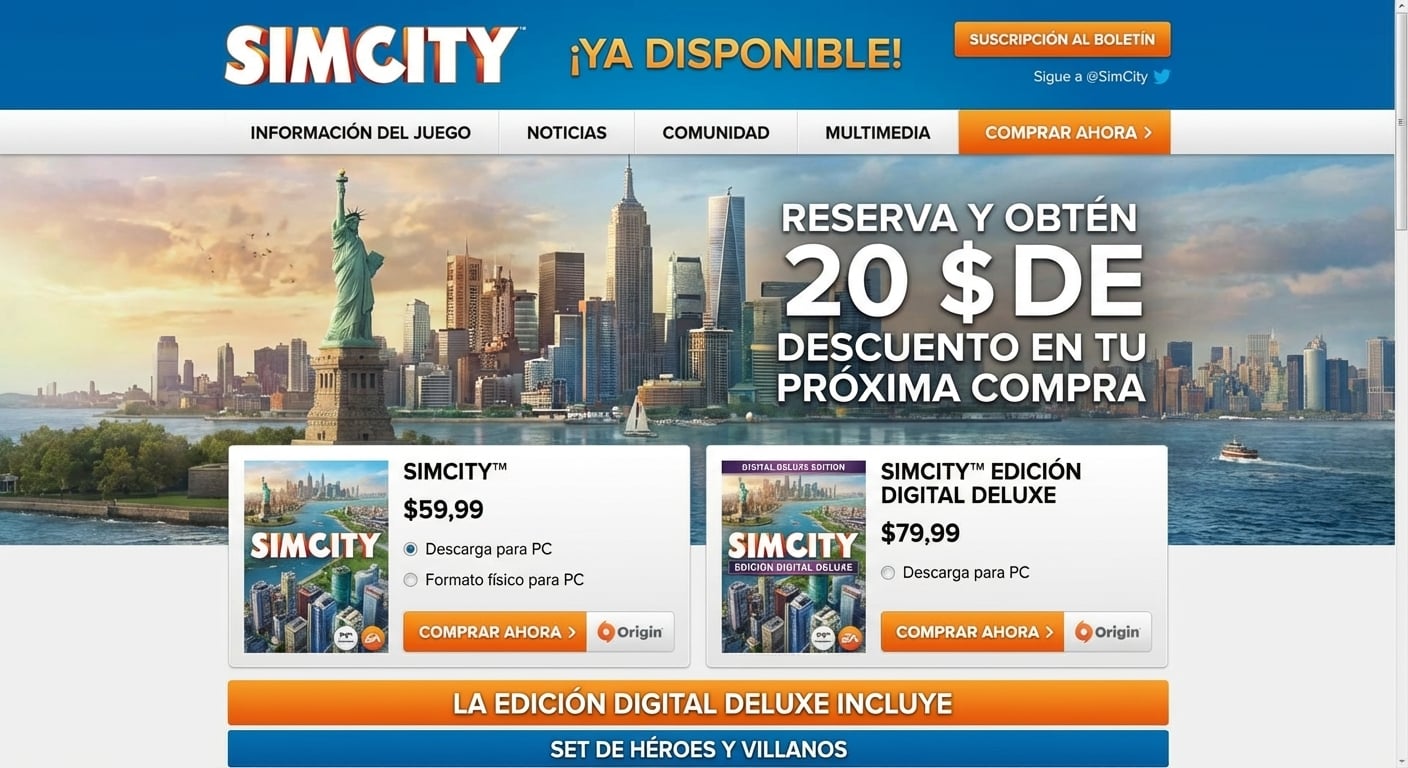
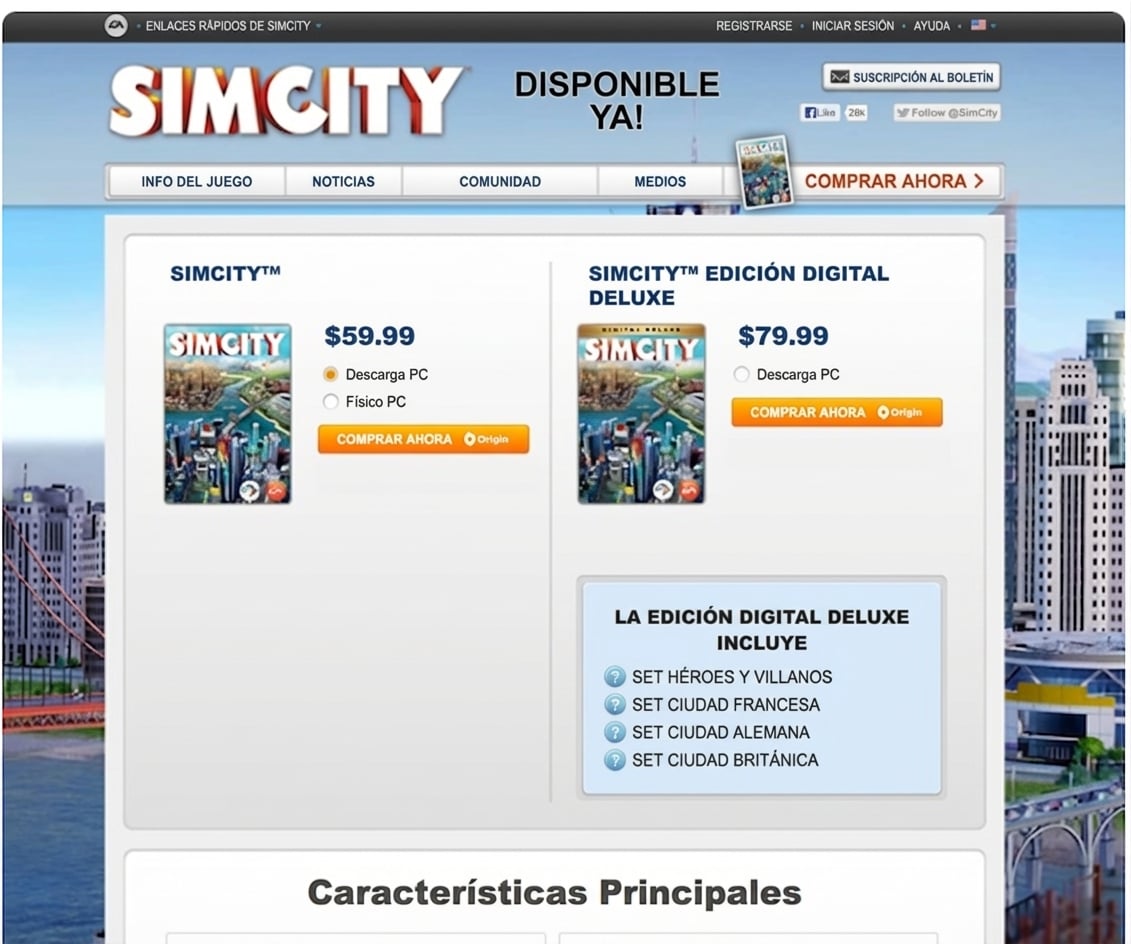
Prueba A/B en página de retail
Control:
Tratamiento:
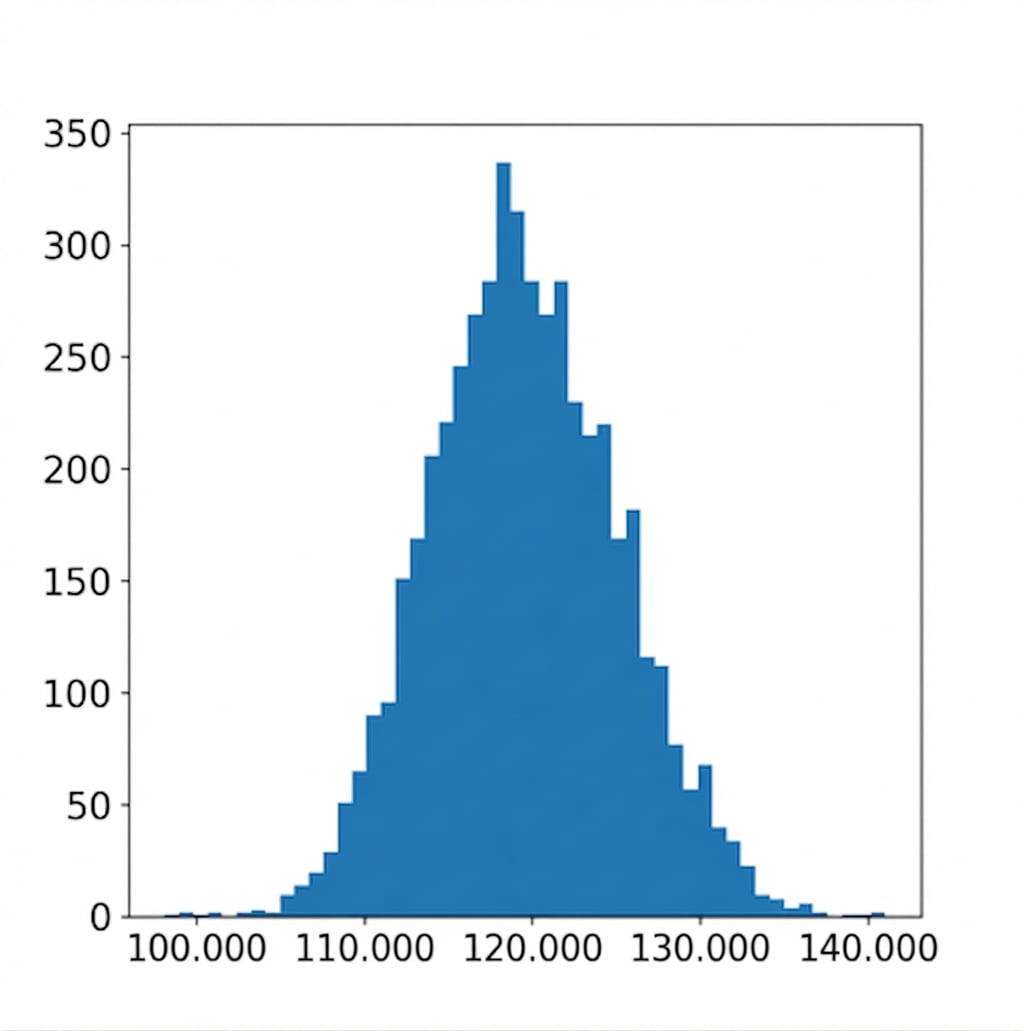
Visualizar la distribución bootstrap
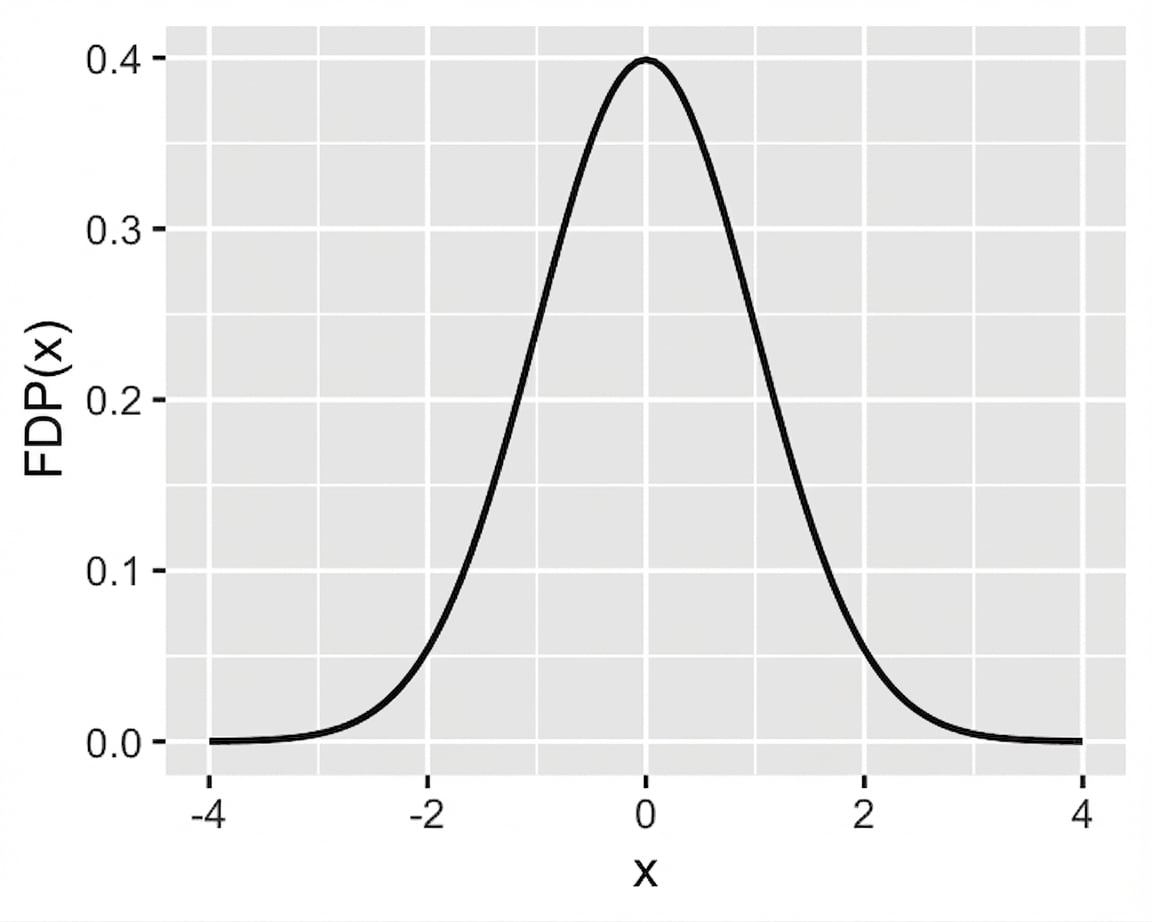
Distribución normal (z) estándar
Distribución normal estándar: normal con media = 0 y desviación estándar = 1