Errores estándar y Teorema Central del Límite
Muestreo en Python

James Chapman
Curriculum Manager, DataCamp
Distribución muestral de puntos de taza medios
Tamaño de muestra: 5
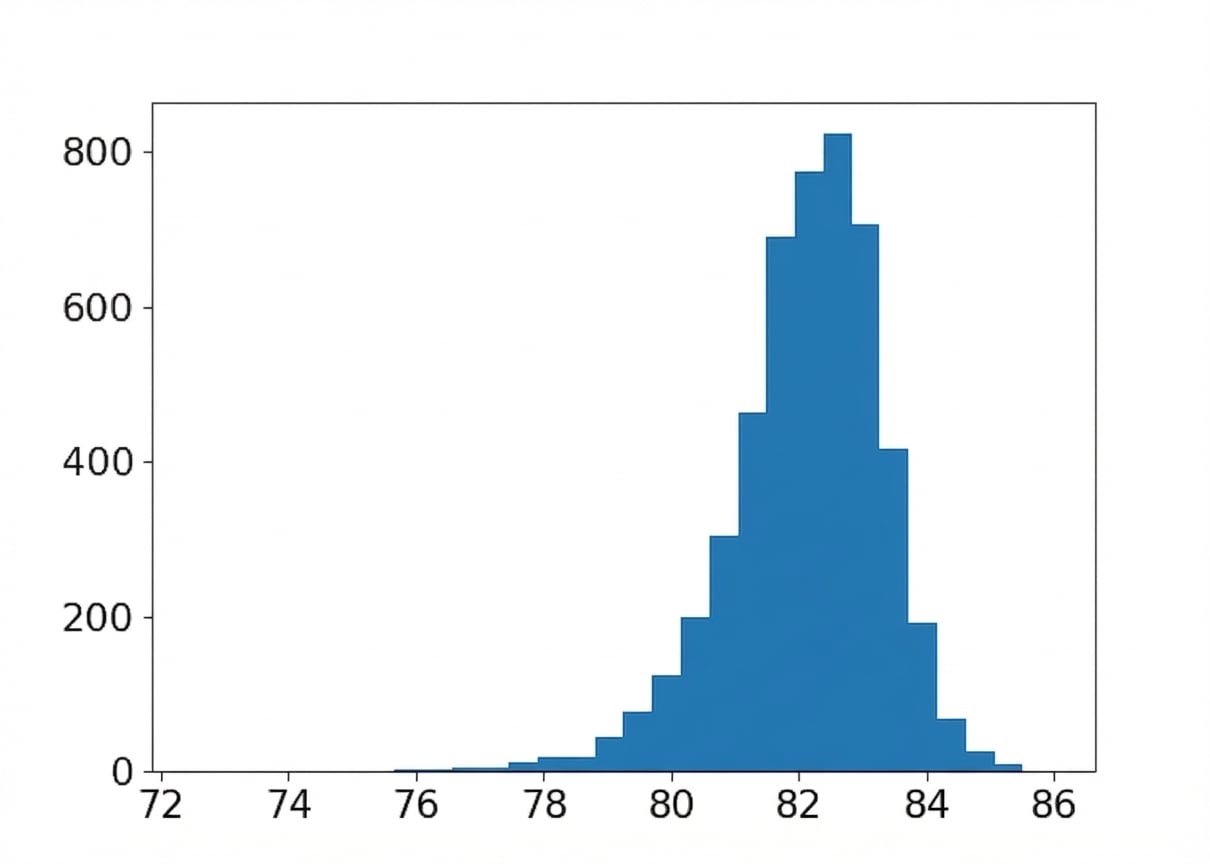
Tamaño de muestra: 20
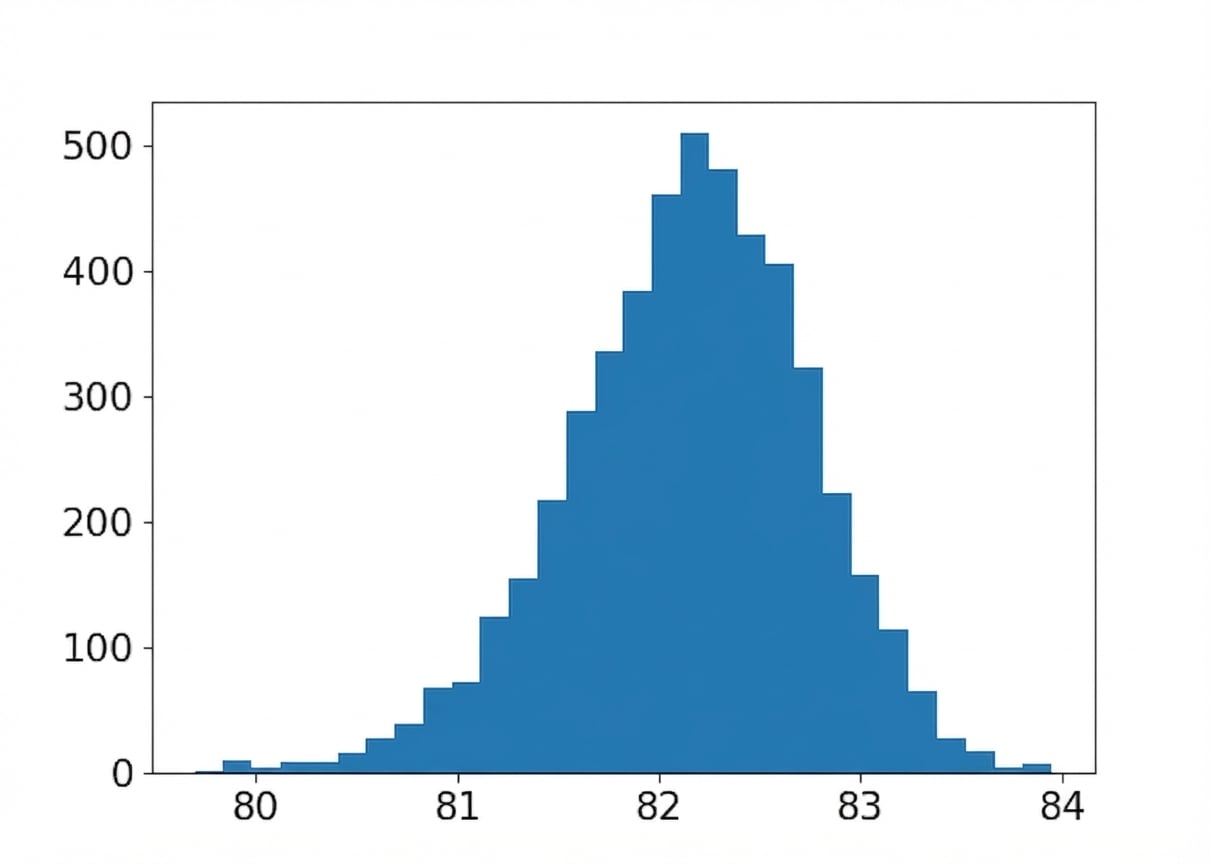
Tamaño de muestra: 80
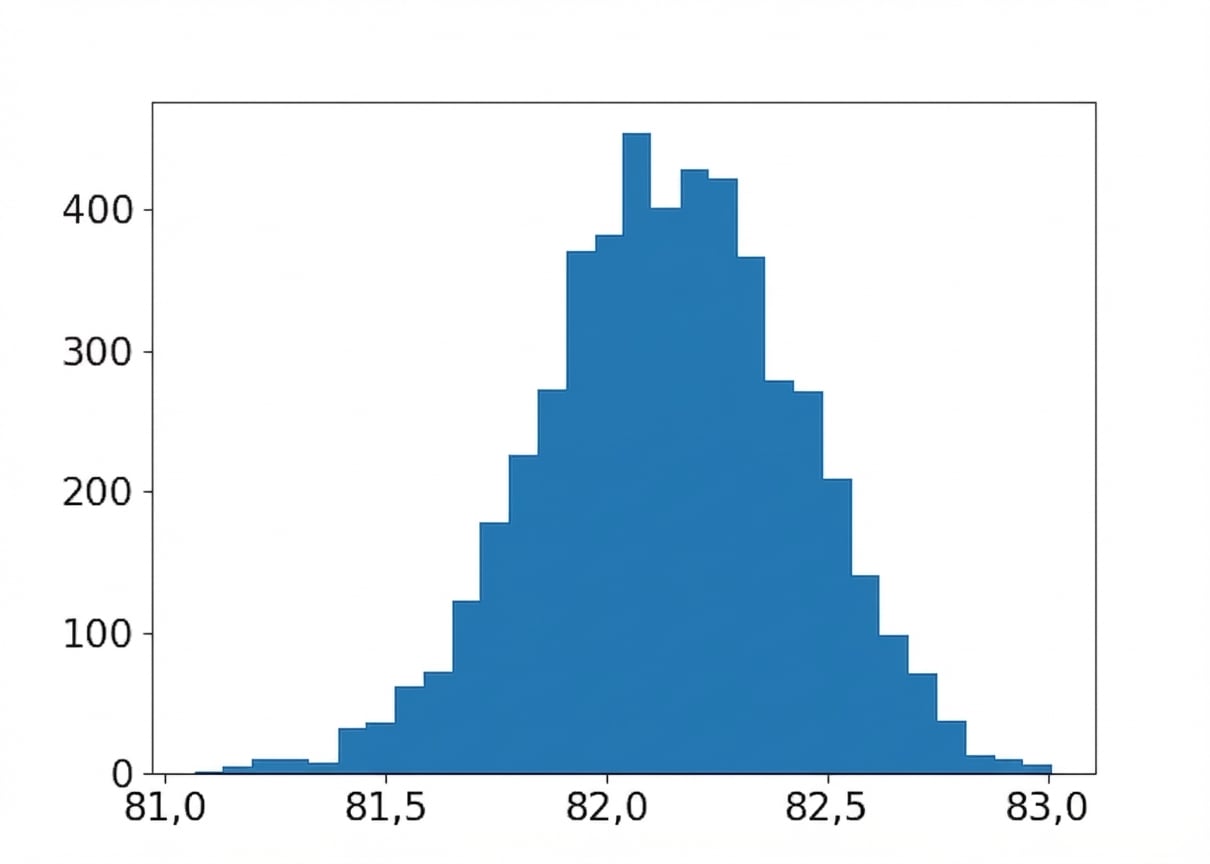
Tamaño de muestra: 320
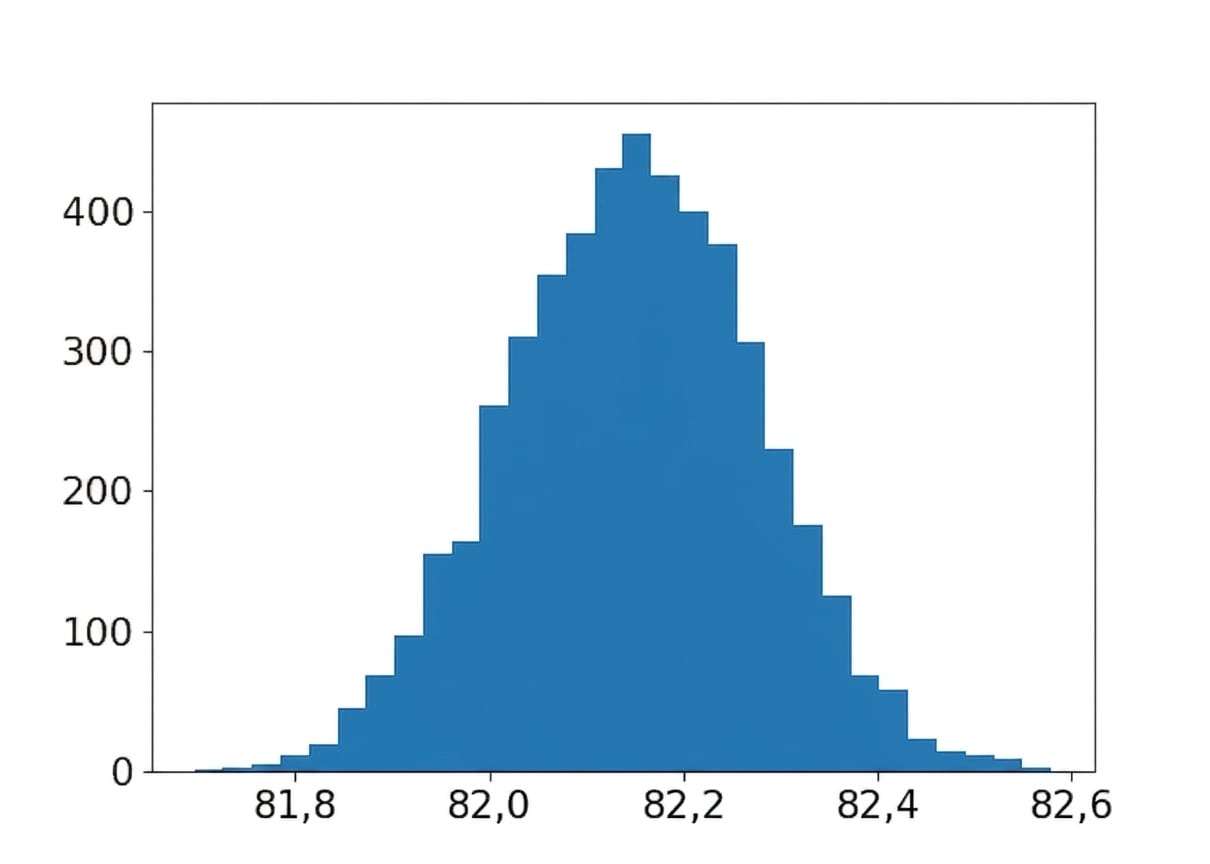
Muestreo en Python
James Chapman
Curriculum Manager, DataCamp
Tamaño de muestra: 5
Tamaño de muestra: 20
Tamaño de muestra: 80
Tamaño de muestra: 320

