Comparar distribuciones de muestreo y bootstrap
Muestreo en Python

James Chapman
Curriculum Manager, DataCamp
Subconjunto centrado en café
coffee_sample = coffee_ratings[["variety", "country_of_origin", "flavor"]]\
.reset_index().sample(n=500)
index variety country_of_origin flavor
132 132 Other Costa Rica 7.58
51 51 None United States (Hawaii) 8.17
42 42 Yellow Bourbon Brazil 7.92
569 569 Bourbon Guatemala 7.67
.. ... ... ... ...
643 643 Catuai Costa Rica 7.42
356 356 Caturra Colombia 7.58
494 494 None Indonesia 7.58
169 169 None Brazil 7.81
[500 rows x 4 columns]
Bootstrap de las medias de sabor del café
import numpy as np
mean_flavors_5000 = []
for i in range(5000):
mean_flavors_5000.append(
np.mean(coffee_sample.sample(frac=1, replace=True)['flavor'])
)
bootstrap_distn = mean_flavors_5000
Distribución bootstrap de la media de sabor
import matplotlib.pyplot as plt
plt.hist(bootstrap_distn, bins=15)
plt.show()
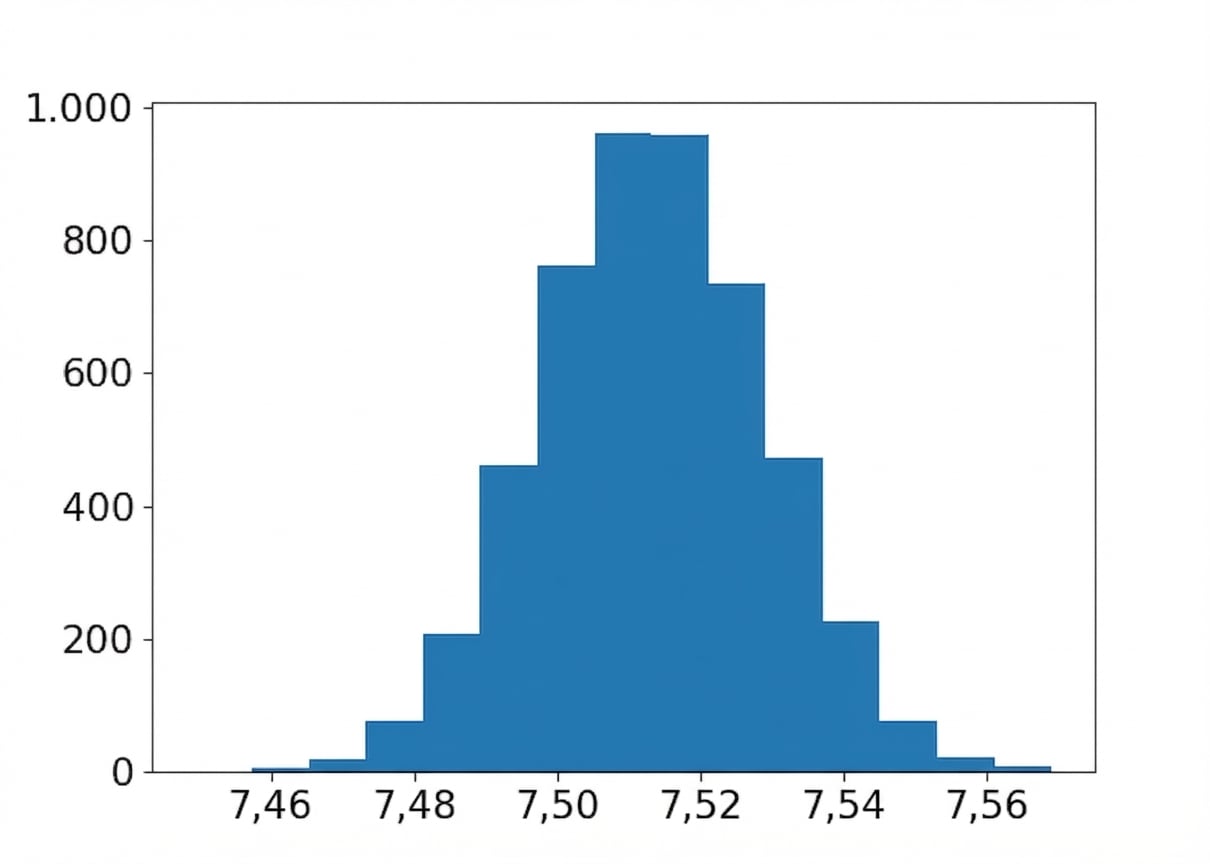
Medias: muestra, dist. bootstrap y población
Media muestral:
coffee_sample['flavor'].mean()
7.5132200000000005
Media poblacional estimada:
np.mean(bootstrap_distn)
7.513357731999999
Media poblacional real:
coffee_ratings['flavor'].mean()
7.526046337817639
Interpretar las medias
Media de la distribución bootstrap:
- Suele estar cerca de la media muestral
- Puede no estimar bien la media poblacional
El bootstrap no corrige sesgos del muestreo
DE muestral vs. DE de la distribución bootstrap
Desviación estándar muestral:
coffee_sample['flavor'].std()
0.3540883911928703
¿Desviación estándar poblacional estimada?
np.std(bootstrap_distn, ddof=1)
0.015768474367958217
DE muestral, dist. bootstrap y población
Desviación estándar muestral:
coffee_sample['flavor'].std()
0.3540883911928703
Desviación estándar poblacional estimada:
standard_error = np.std(bootstrap_distn, ddof=1)
Error estándar = desviación estándar de la estadística de interés
Desviación estándar real:
coffee_ratings['flavor'].std(ddof=0)
0.34125481224622645
standard_error * np.sqrt(500)
0.3525938058821761
El error estándar por la raíz del tamaño muestral estima la DE poblacional
Interpretar los errores estándar
- Error estándar estimado → desviación estándar de la distribución bootstrap de una estadística muestral
- $\text{DE pobl.} \approx \text{Error est.} \times \sqrt{\text{Tamaño muestral}}$
¡Vamos a practicar!
Muestreo en Python

