Muestreo aleatorio simple y sistemático
Muestreo en Python

James Chapman
Curriculum Manager, DataCamp
Muestreo aleatorio simple


Muestreo aleatorio simple de cafés


Muestreo sistemático

El problema del muestreo sistemático
coffee_ratings_with_id = coffee_ratings.reset_index()
coffee_ratings_with_id.plot(x="index", y="aftertaste", kind="scatter")
plt.show()
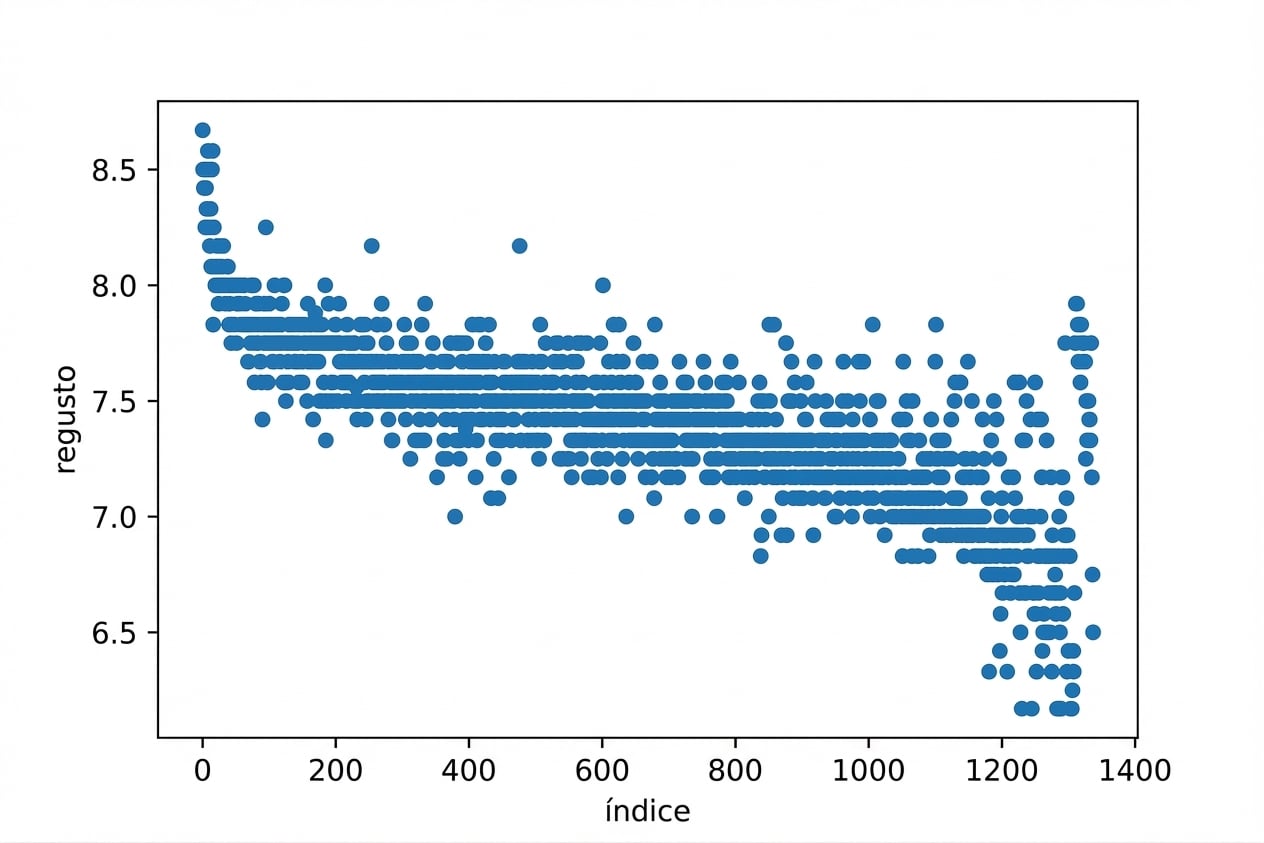
El muestreo sistemático solo es seguro si no vemos un patrón en este diagrama de dispersión
Cómo hacer seguro el muestreo sistemático
shuffled = coffee_ratings.sample(frac=1)shuffled = shuffled.reset_index(drop=True).reset_index()shuffled.plot(x="index", y="aftertaste", kind="scatter") plt.show()
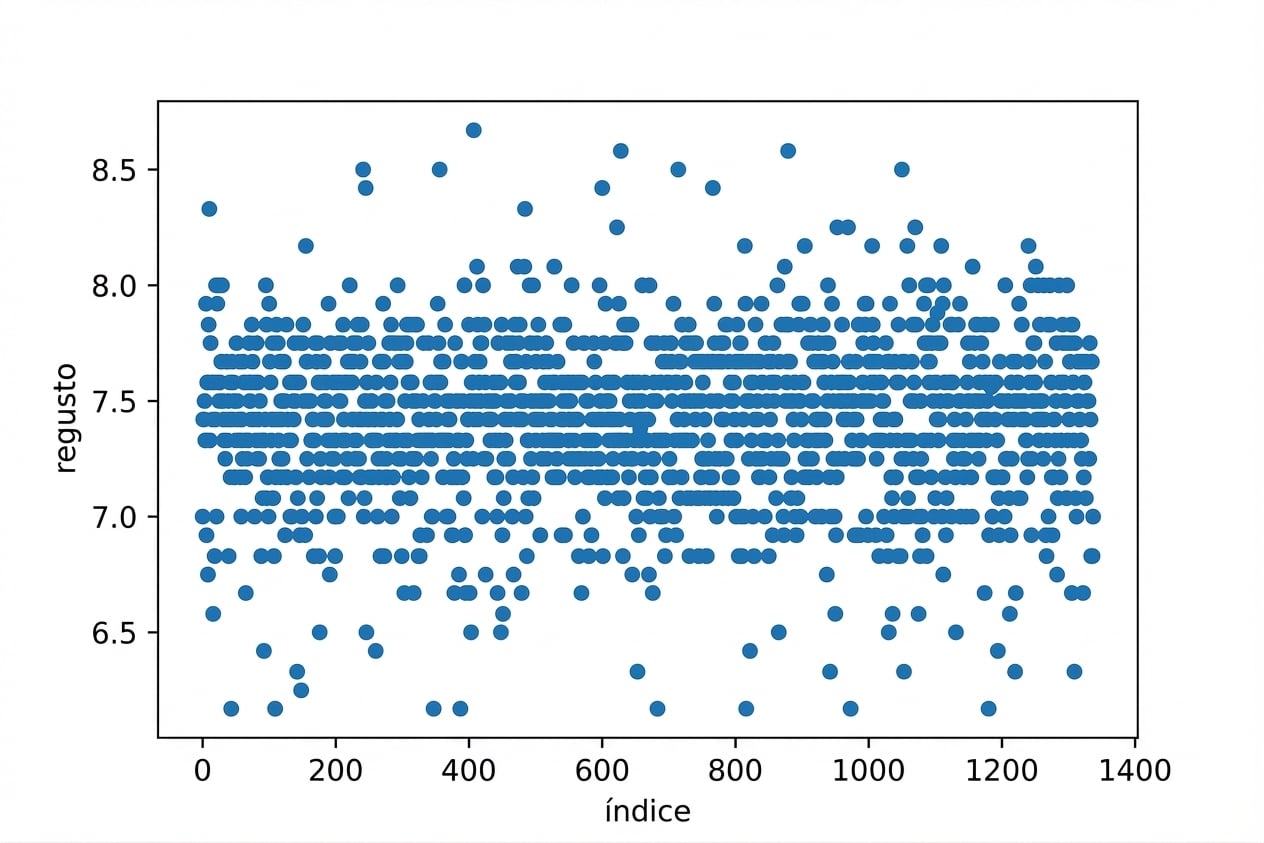
Barajar filas + muestreo sistemático equivale a muestreo aleatorio simple

