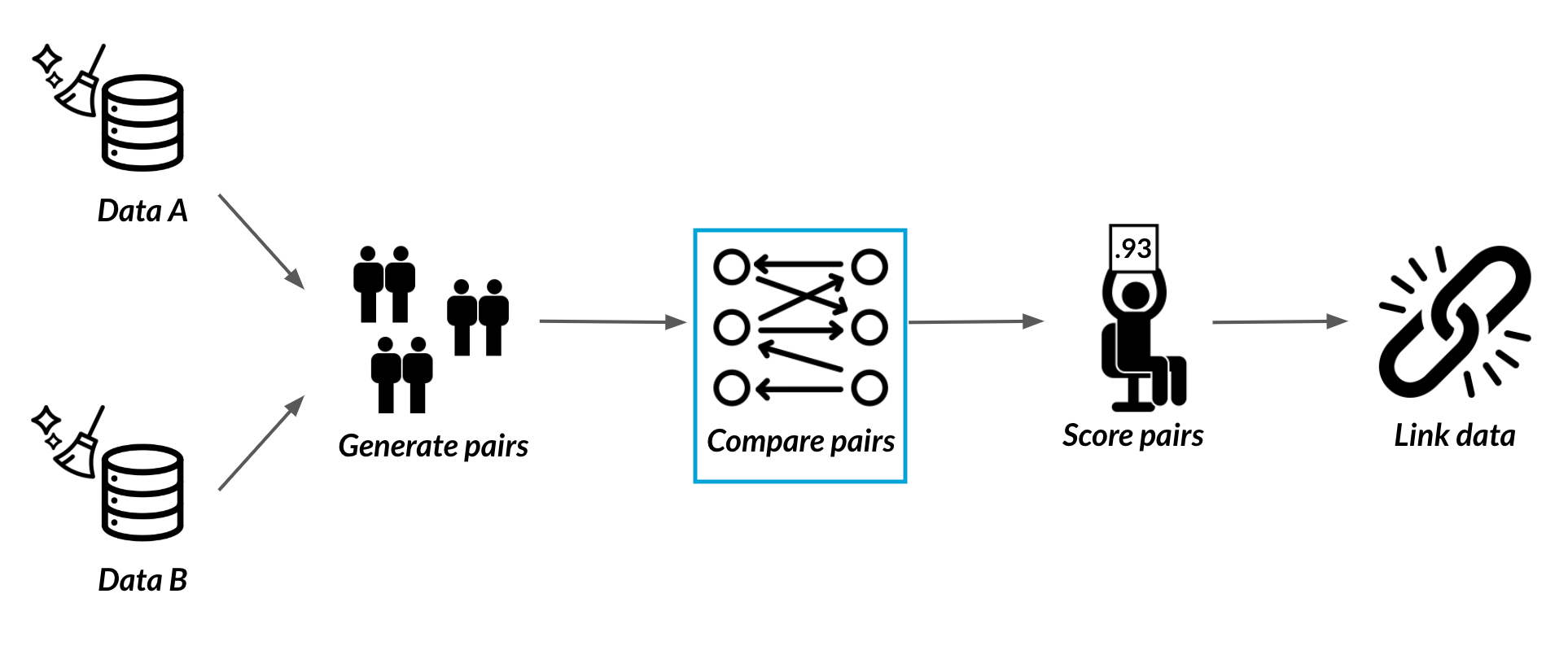
Generating and comparing pairs
Cleaning Data in R

Maggie Matsui
Content Developer @ DataCamp
When joins won't work
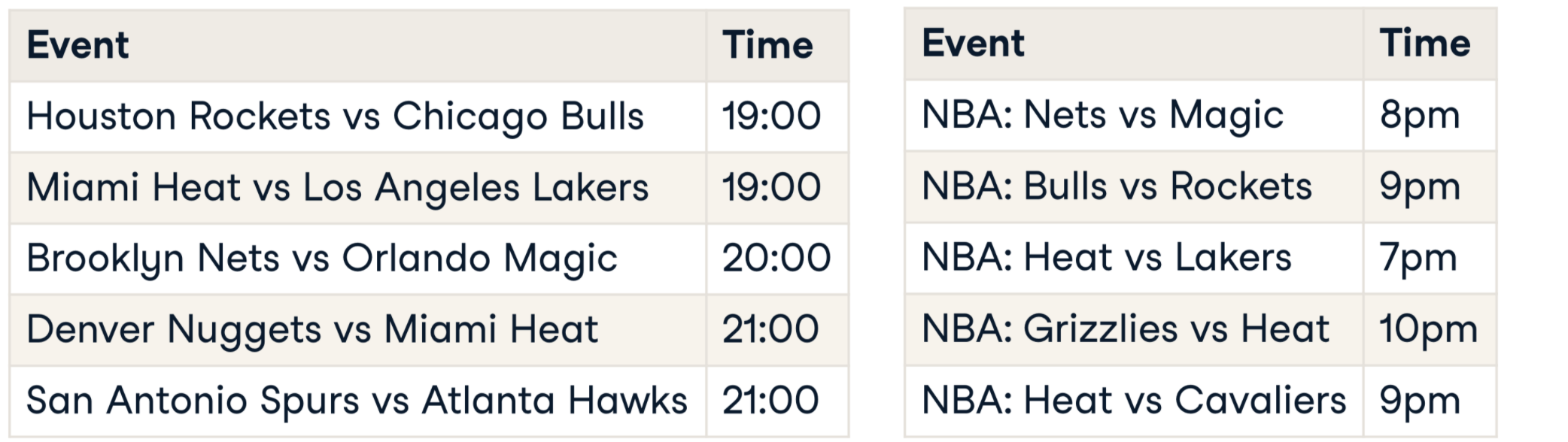
When joins won't work
What is record linkage?

What is record linkage?

What is record linkage?

What is record linkage?
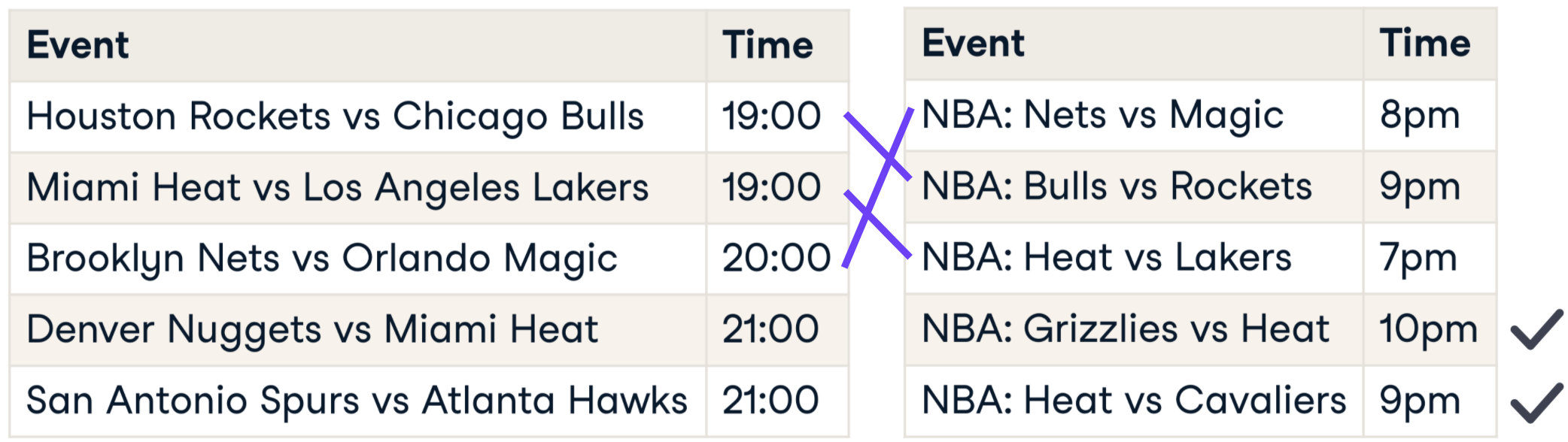
What is record linkage?
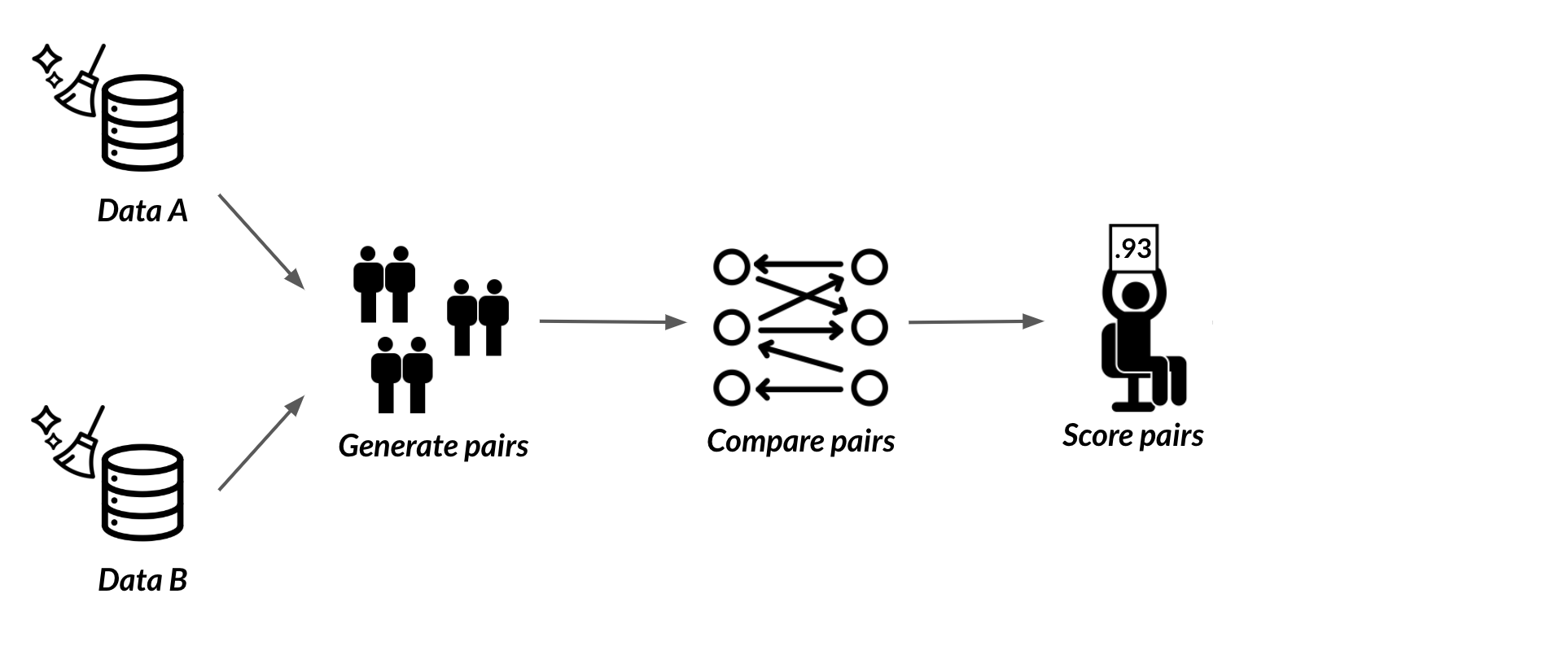
What is record linkage?
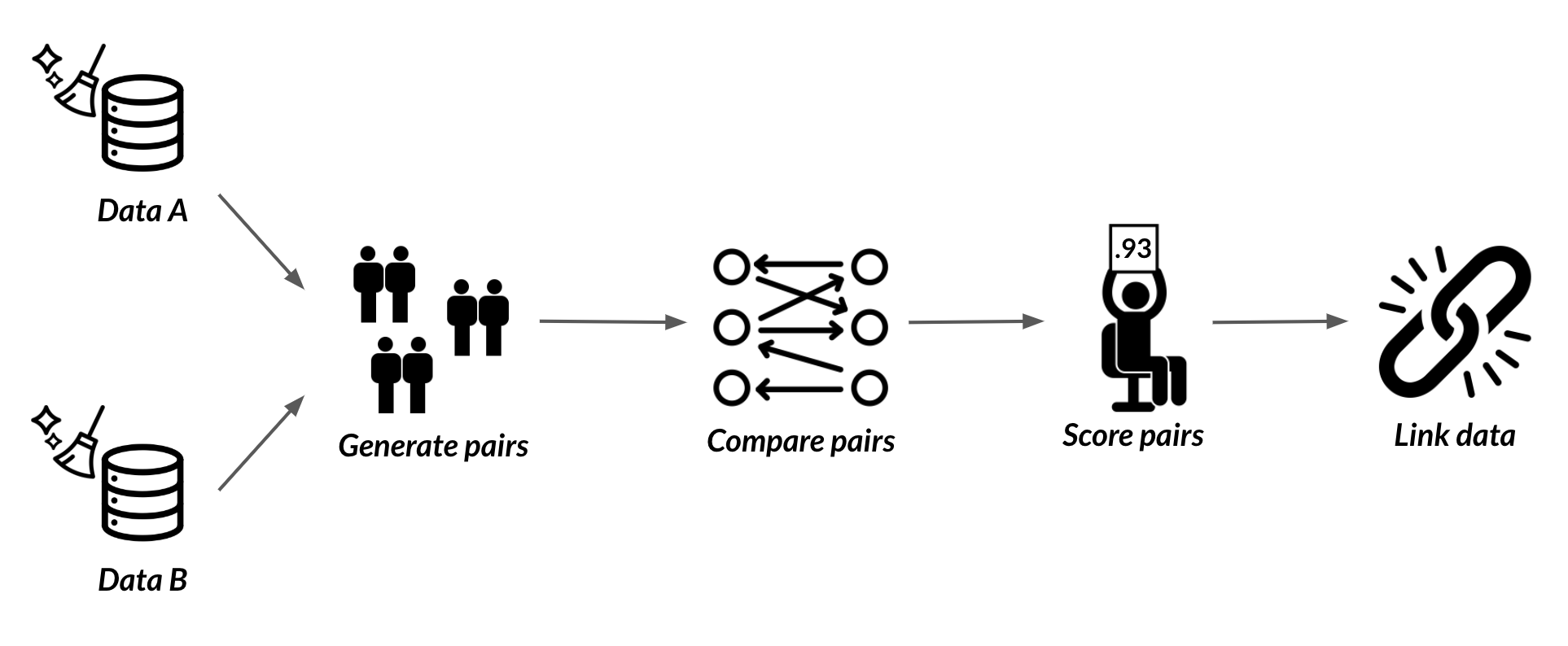
What is record linkage?
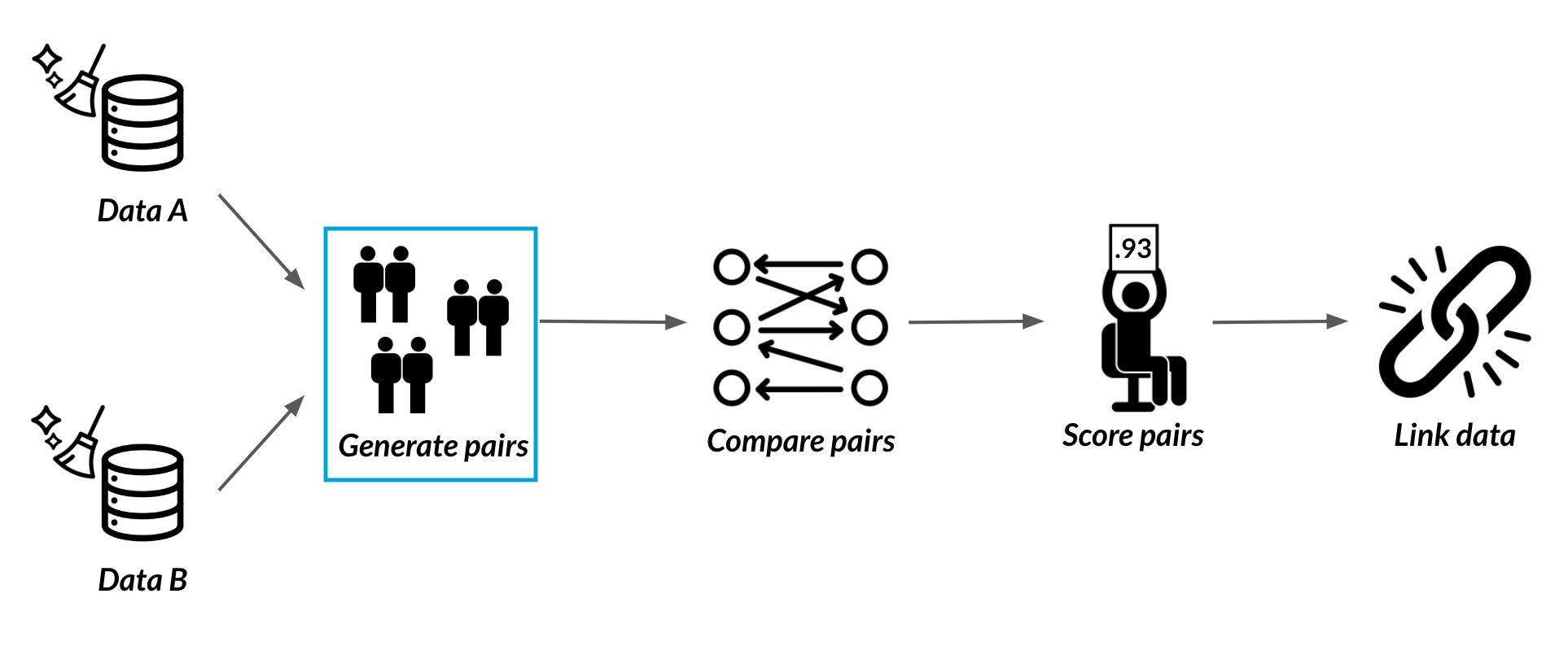
Pairs of records
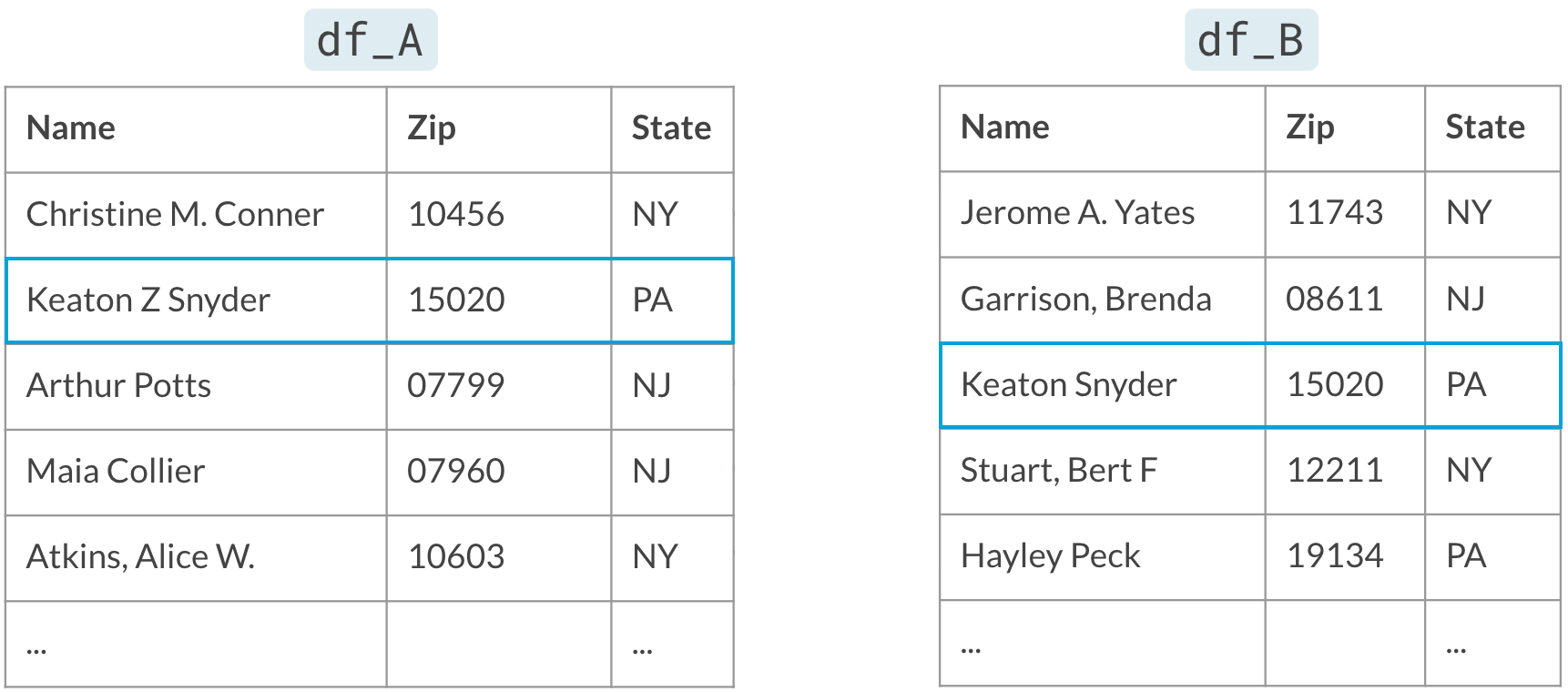
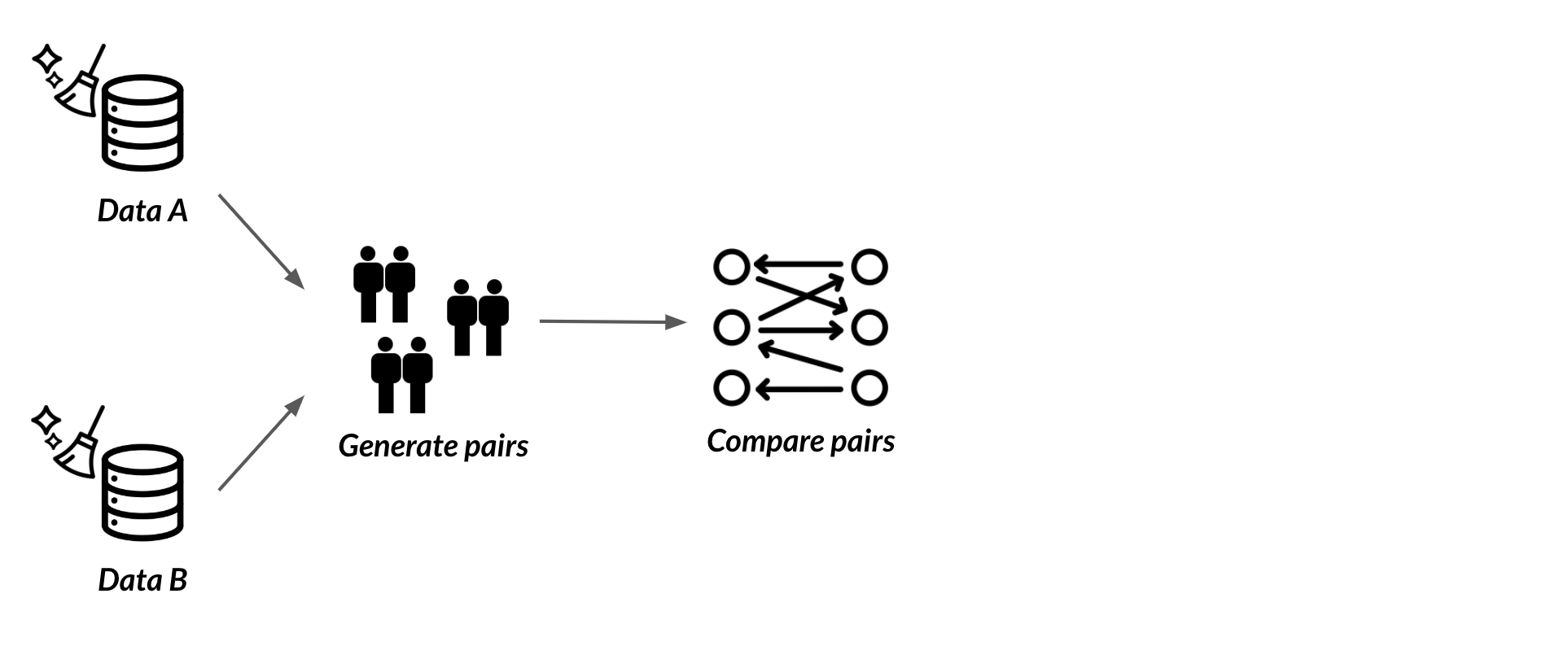
Generating pairs
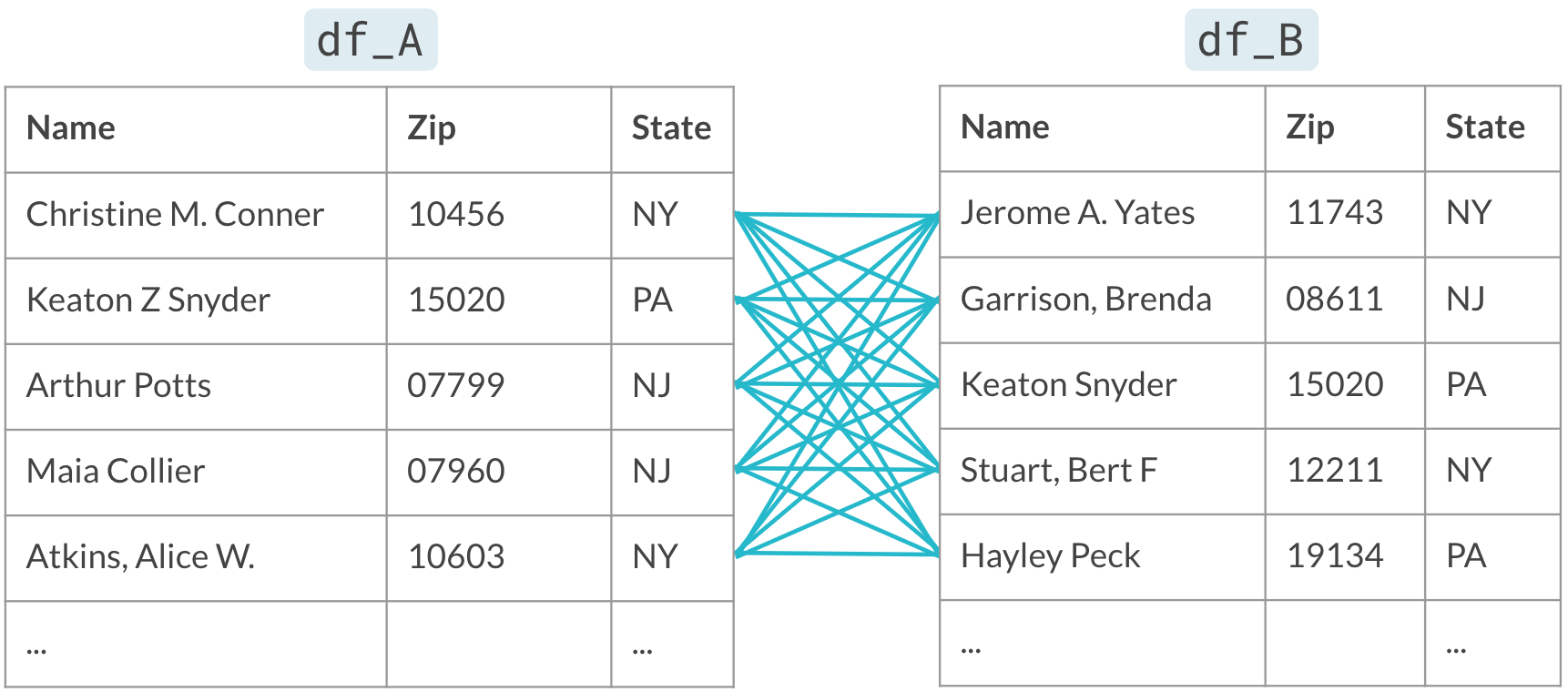
Too many pairs
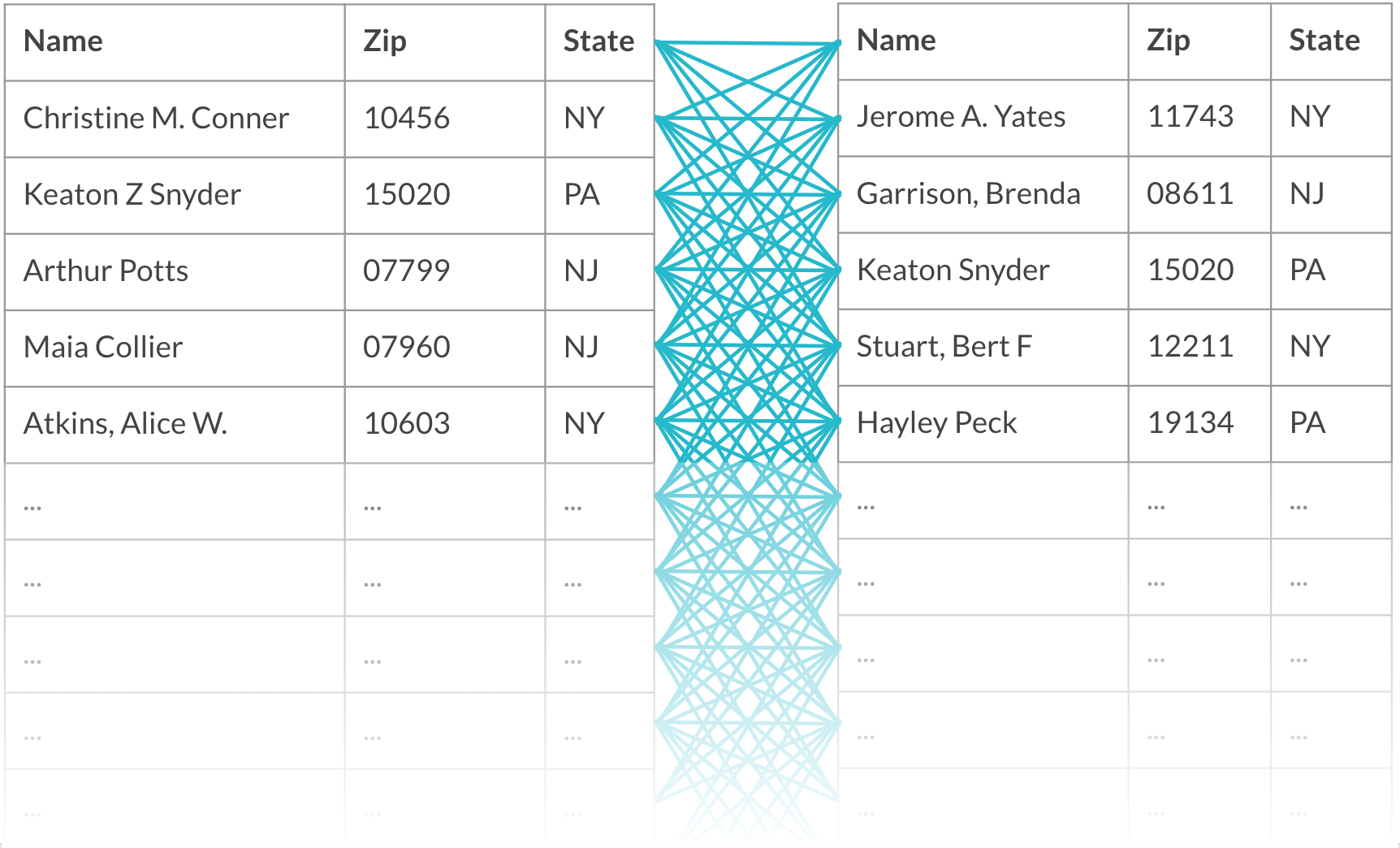
Blocking
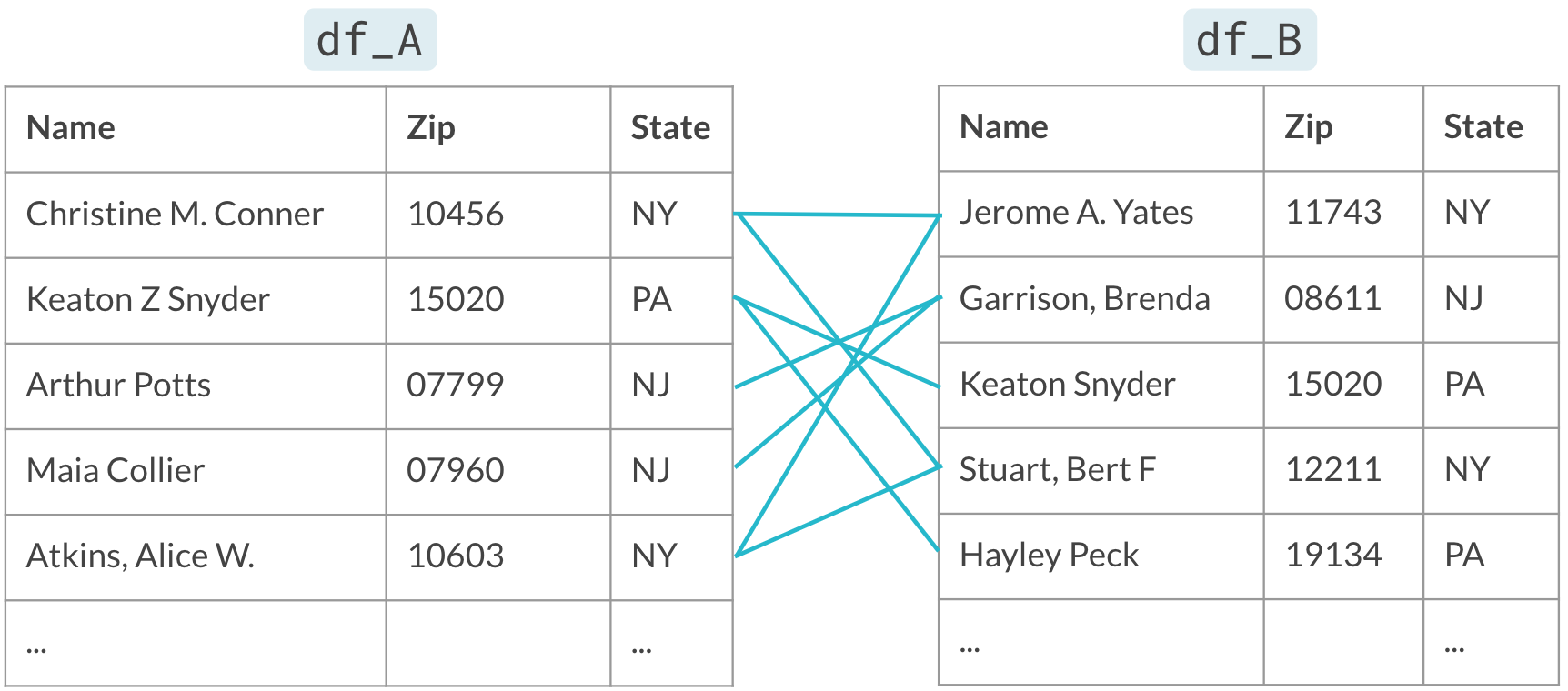
Only consider pairs when they agree on the blocking variable (State)
Comparing pairs